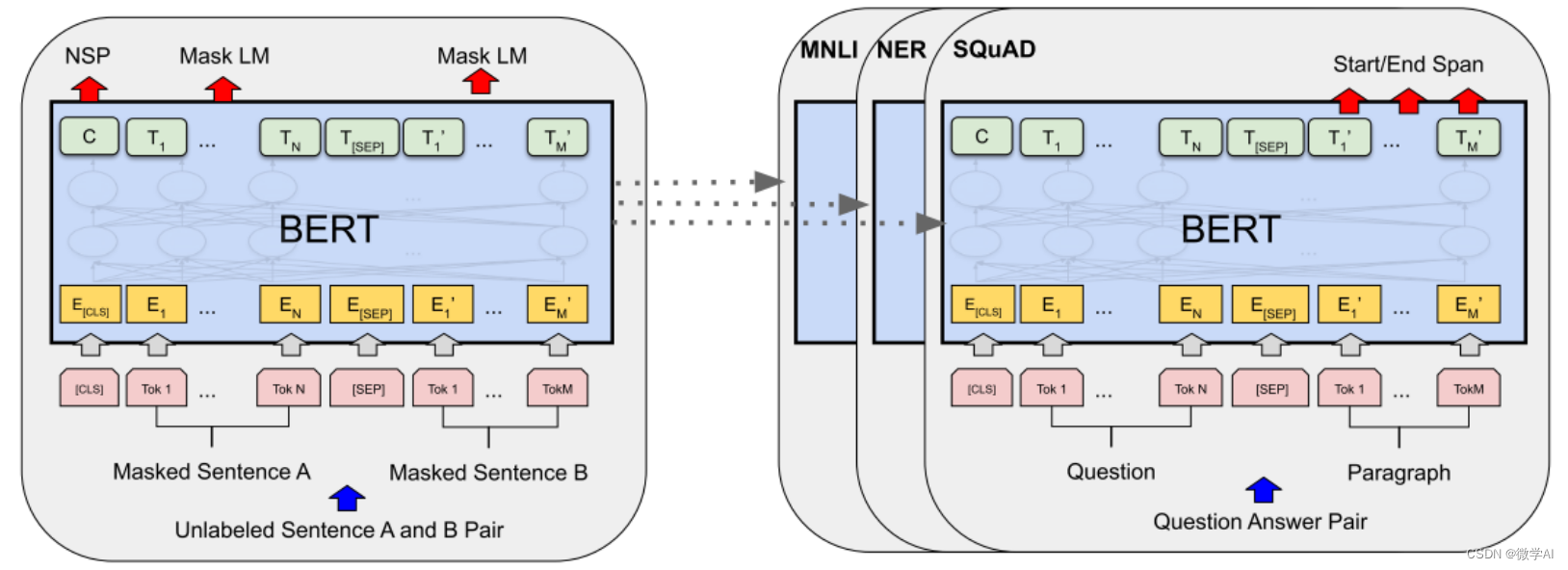
人工智能
OD
搭建网站
Table API
.pdf预览
绘图机器人
STM32G070RBT6
jmeter
PCB
指针
逆向
408
增强现实
产品经理常犯的错误
NISCTF
资损
界面设计
校园二手交易系统
医疗
OpenHarmony
nlp
2024/4/11 14:43:39
论文笔记 ACL 2015|Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks
文章目录1 简介1.1 动机1.2 创新2 方法Word Embedding Learning and Lexical-Level Feature RepresentationExtracting Sentence-Level Features Using a DMCNNModel for Trigger Classification3 实验4 总结1 简介
论文题目:Event Extraction via Dynamic Multi-P…

【pytorch模型实现4】TextCNN
TextCNN模型实现
NLP模型代码github仓库:https://github.com/lyj157175/Models
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, config):super(TextCNN, self).__init__()self.max_seq_len …
NLP系列项目二:RNN训练语言模型(pytorch完整代码)
欢迎查看Github代码及训练数据集,给个star呗~
训练语言模型
用RNN,LSTM,GRU来训练一个语言模型,用于预测单词的下一个词
torchtext基本用法
构建 vocabularyword to index 和 index to word
torch.nn的一些基本模型
LinearRNNLSTMGRU
RNN的训练技…

CNCC 2018技术论坛——知识图谱赋能数字经济
本周五报名参加了在杭州举办的CNCC 2018大会,听取了关于知识图谱的技术论坛——知识图谱赋能数字经济。共有6位专家讲者带来了精彩的主题报告,以及一个小时的Panel环节。本博客将整理总结分享专家的报告,供大家参考。
1、周傲英:…

论文笔记 ACL 2010|Using Document Level Cross-Event Inference to Improve Event Extraction
文章目录1 简介1.1 动机1.2 创新2 背景知识任务介绍论元和触发词一致性3 方法Sentence-level Baseline SystemDocument-level Confident Information CollectorStatistical Cross-event ClassifiersDocument Level Trigger ClassifierDocument Level Argument (Role) Classifie…

论文笔记 ACL 2015|Event Detection and Domain Adaptation with Convolutional Neural Networks
文章目录1 简介1.1 动机1.2 创新2 方法3 实验对比实验域适应实验4 总结1 简介
论文题目:Event Detection and Domain Adaptation with Convolutional Neural Networks 论文来源:ACL2015 论文链接:https://aclanthology.org/P15-2060.pdf
1.…

论文笔记 arxiv 2015|Bidirectional LSTM-CRF Models for Sequence Tagging
文章目录1 简介1.1 动机1.2 创新2 背景知识LSTM NetworksBidirectional LSTM NetworksCRF networks3 方法LSTM-CRF networks4 实验5 总结1 简介
论文题目:Bidirectional LSTM-CRF Models for Sequence Tagging 论文来源:2015 arxiv 论文链接:…

论文笔记 ACL2021|CLEVE-Contrastive Pre-training for Event Extraction
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 预处理3.2 事件语义预训练3.2.1 文本编码器3.2.2 触发词-论元对辨别3.3 事件结构预训练3.3.1 图编码器3.3.2 AMR子图辨别4 实验4.1 预训练设置4.2 CLEVE的改写4.3 监督事件抽取4.4 无监督自由的事件抽取5 总结1 简介
论文题…

论文笔记 COLING 2020|Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法Handshaking Tagging Scheme3.1.1 Tagging3.1.2 DecodingToken Pair RepresentationHandshaking TaggerLoss Function4 实验5 总结1 简介
论文题目:Single-stage Joint Extraction of Entities and Relations Throu…

机器学习笔记 - 深入研究spaCy库及其使用技巧
一、简述 spaCy 是一个用于 Python 中高级自然语言处理的开源库。它专为生产用途而设计,这意味着它不仅功能强大,而且快速高效。spaCy 在学术界和工业界广泛用于各种 NLP 任务,例如标记化、词性标注、命名实体识别等。 安装,这里使用阿里的源。
pip install spacy…
文本生成:自动摘要评价指标 Rouge
本文结构概览不同的摘要任务下,选择合适的Rouge指标Rouge-N的理解与示例Rouge-L的理解与示例代码示例(char粒度 计算摘要的Rouge值)代码示例(word粒度 计算摘要的Rouge值)个人思考ReferenceRouge的全名是Recall-Orient…
机器学习NLP参考文章
本站整理了一些NLP的入门资料参考,建议初学者看看。
需要复制链接在浏览器里打开。 1.通过kaggle比赛学习机器学习文本分类方法https://zhuanlan.zhihu.com/p/34899693?utm_mediumsocial&utm_sourcewechat_session&fromgroupmessage&isappinstalled0&…

Ace2005英文数据解析过程(事件抽取)
本文是对ace2005-preprocessing代码的解读。
数据集介绍
英文的数据包括以下文件夹:NW(Newswire)、BN(Broadcast News)、BC(Broadcast Conversation)、WL(Weblog)、UN(UsenetNewsgroups /Discussion Forum)、CTS(Conversational Telephone Speech),主要关注内容为…
论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations 1. 文章简介2. 文章概括3 文章重点技术3.1 BiLM(Bidirectional Language Model)3.2 ELMo3.3 将ELMo用于NLP监督任务 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Deep contextualized word representations作者…

基于MLP进行文本分类
最近学习了基于Pytorch框架下的MLP、CNN、RNN网络模型,利用在GitHub上获取的商品评论数据进行文本分类实验。本文介绍了如何在Pytorch框架下建立MLP对数据进行二分类,数据集大致如下:
1、导入模块
import pandas as pd
import numpy as np…

利用spaCy对中文文本分词和去除停用词处理
spaCy简介
spaCy语言模型包含了一些强大的文本分析功能,如词性标注和命名实体识别功能。目前spaCy免费支持的语言有:英文、德语、法语、西班牙语、葡萄语、意大利语和荷兰语,其他的语言也在慢慢的增长。对于spaCy处理中文文本(本…

Python模拟简易版淘宝客服机器人
对于用Python制作一个简易版的淘宝客服机器人,大概思路是:首先从数据库中用sql语句获取相关数据信息并将其封装成函数,然后定义机器问答的主体函数,对于问题的识别可以利用正则表达式来进行分析,结合现实情况选择答案&…
如何检验下载的大模型checkpoint文件是否正确的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…

NLP笔记:fastText模型考察
NLP笔记:fastText模型考察 1. fastText模型原理2. facebook的fastText模块使用3. 使用tensorflow构建fastText模型4. 使用torch构建fastText模型5. 总结6. 参考链接 1. fastText模型原理
fastText大约是NLP文本分类任务中最简单最直观的模型架构之一了,…

【小沐学NLP】Python进行统计假设检验
文章目录 1、简介1.1 假设检验的定义1.2 假设检验的类型1.3 假设检验的基本步骤 2、测试数据2.1 sklearn2.2 seaborn 3、正态分布检验3.1 直方图判断3.2 KS检验(scipy.stats.kstest)3.3 Shapiro-Wilk test(scipy.stats.shapiro)3.…
大模型的三大法宝:Finetune, Prompt Engineering, Reward
编者按:基于基础通用模型构建领域或企业特有模型是目前趋势。本文简明介绍了最大化挖掘语言模型潜力的三大法宝——Finetune, Prompt Engineering和RLHF——的基本概念,并指出了大模型微调面临的工具层面的挑战。 以下是译文,Enjoy! 作者 | B…

论文笔记 NLPCC 2016|A Convolution BiLSTM Neural Network Model for Chinese Event Extraction
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 触发词标记3.1.1 单词级别模型3.1.2 字符级别模型3.2 论元标记4 实验4.1 触发词标记4.2 论元标记5 总结1 简介
论文题目:A Convolution BiLSTM Neural Network Model for Chinese Event Extraction 论文来源&am…
LSTM已死,Transformer当立(LSTM is dead. Long Live Transformers! ):上
回想一下在Seq2seq模型中,如何使用Attention。这里简要回顾一下【1】介绍的方法2(并以此为基础展开对Transformer的讨论)。
下图中包含一个encoder(左)和一个decoder(右)。对于decoder来说,给定一个输入,得到输出,如何进一步得到context vector 呢?
我们需要根据和…

论文笔记 AAAI 2018|Scale Up Event Extraction Learning via Automatic Training Data Generation
文章目录1 简介1.1 动机1.2 创新2 方法2.1 训练数据生成2.1.1 确定关键论元2.1.2 数据生成2.2 事件抽取2.2.1 关键论元和事件检测2.2.2 非关键论元检测3 实验3.1 数据集评测3.2 抽取评测3.2 人工评测4 总结1 简介
论文题目:Scale Up Event Extraction Learning via…

论文笔记 ACL 2018|Document Embedding Enhanced Event Detection with Hierarchical and Supervised Attention
文章目录1 简介1.1 动机1.2 创新2 方法2.1 文档编码学习2.1.1 单词级别编码2.1.2 句子级别编码2.2 事件检测模型3 实验4 总结1 简介
论文题目:Document Embedding Enhanced Event Detection with Hierarchical and Supervised Attention 论文来源:ACL 2…


NLP-字词向量的平衡算法(消除“偏见”)
向量的平衡算法
用于NLP领域的消除性别等偏见。问题表征如下:
为了使得e_w1 and e_w2对bia_orth有同样的距离
(扩充:nlp为了消除字词的语义偏见,比如,
给定“工程师”首先想到man而不是woman,即“工程师…

NLP之中文命名实体识别
在MUC-6中首次使用了命名实体(named entity)这一术语,由于当时关注的焦点是信息抽取(information extraction)问题,即从报章等非结构化文本中抽取关于公司活动和国防相关活动的结构化信息,而人名…
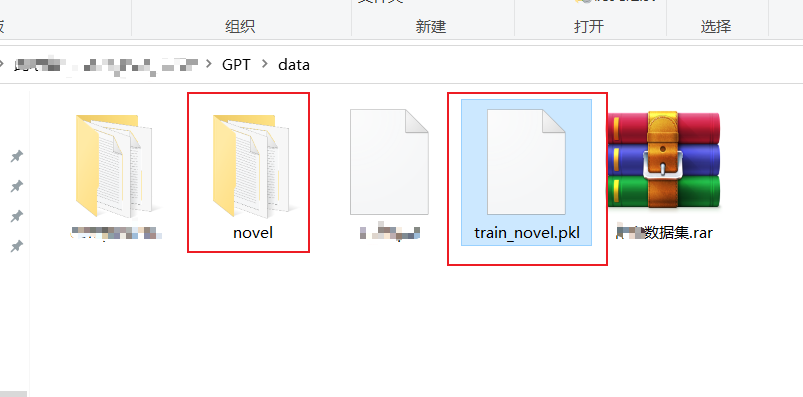
从零构建属于自己的GPT系列1:预处理模块(逐行代码解读)、文本tokenizer化
1 训练数据
在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件 数据打开后的样子
数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token 最后生成的文件就是train_novel.pkl文件&a…

NLP之人机对话系统
人机对话系统
人机对话系统又称口语对话系统(spoken dialogue system)。一个典型的人机对话系统主要包括如下6个技术模块:①语音识别器(speech recognizer);②语言解析器(language parser&…
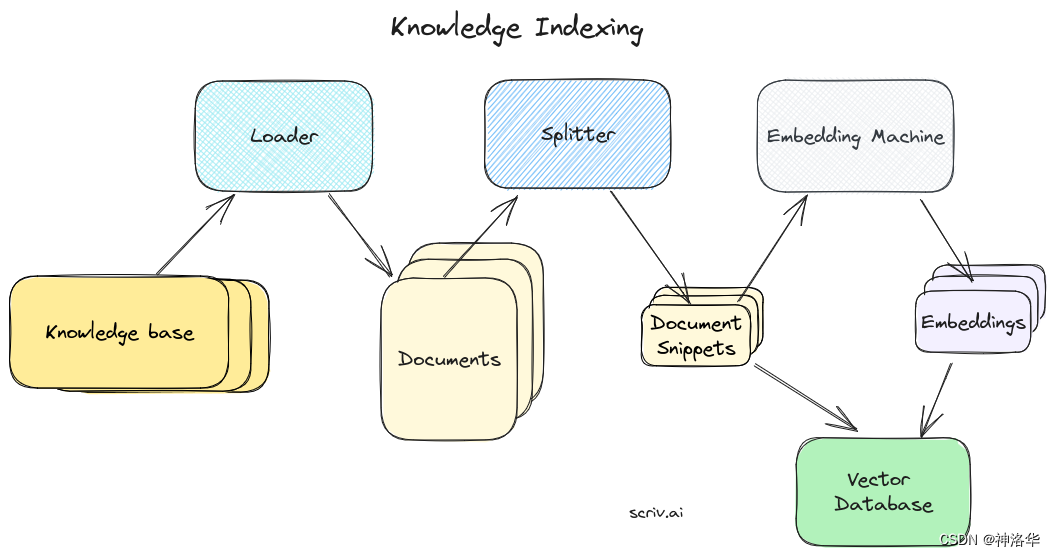
LangChain(0.0.340)官方文档八:Retrieval——Document transformers
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、Text splitters1.1 快速开始(RecursiveCharacterTextSplitter)1.2 MarkdownHeaderTextSplitter1.2.1 按结构拆分md文件1.2.2 继续分割 Markdown gr…

论文笔记 Bioinformatics 2020|DeepEventMine:end-to-end neural nested event extraction from biomedical tex
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 BERT层3.2 实体(触发词)层3.3 角色层3.4 事件层4 实验5 总结1 简介
论文题目:DeepEventMine:end-to-end neural nested event extraction from biomedical texts 论文来源:Bioinformatics 2020 论文…

论文笔记 ACL 2020|Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Enc
文章目录1 简介1.1 动机1.2 创新2 背景知识2.1 句子级事件抽取2.2 文档级事件抽取3 方法3.1 构建token-tag序列3.2 k个句子阅读器3.3 多粒度阅读器4 实验5 总结1 简介
论文题目:Document-Level Event Role Filler Extraction using Multi-Granularity Contextualiz…

论文笔记 EMNLP 2019|Entity, Relation, and Event Extraction with Contextualized Span Representations
文章目录1 简介1.1 创新2 背景知识3 方法4 实验1 简介
论文题目:Entity, Relation, and Event Extraction with Contextualized Span Representations 论文来源:EMNLP 2019 论文链接:https://aclanthology.org/D19-1585.pdf 代码链接&#x…

虚假内容检测,谣言检测,不实信息检测,事实核查;纯文本,多模态,多语言;数据集整理
本博客系博主个人理解和整理所得,包含内容无法详尽,如有补充,欢迎讨论。
这里只提供数据集相关介绍和来源出处,或者下载地址等,因版权原因不提供数据集所含的元数据。如有需要,请自行下载。
“Complete d…

水果这样切18刀,简直是太香啦!
12月24日《疯狂切水果》登录 Cocos Store 敬请期待!!!届时 Cocos Store 还有圣诞幸运大 🎁 送给大家,有没觉得很暖心呢!除了Cocos实物周边外,Store开发者还准备了¥100巨额ÿ…

jieba源碼研讀筆記(七) - 分詞之精確模式(使用HMM維特比算法發現新詞)
jieba源碼研讀筆記(七) - 分詞之精確模式(使用HMM維特比算法發現新詞)前言jieba/finalseg的目錄結構jieba/finalseg/__init__.py載入HMM的參數viterbi函數__cut函數add_force_split函數cut函數jieba/__init__.py__cut_DAG函數參考…

医学诊断报告生成论文综述
摘要
由Image/Video Captioning、VQA等图像理解任务的不断往前发展,以及目前智能医疗的兴起,有些学者自然而然地想到图像理解是否可以应用到医学领域,因此根据CT、核磁等图像自动生成诊断报告(病例),这个任务被提了出来。
2018年…
bert-base-chinese 判断上下句
利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值 MERGE_RATIO &#…
GPT-4要点内容记录
多模态的模型:GPT-4是一个多模态的模型,可以接受文本或图像的输入,但是只能以纯文本的形式给出输出。OpenAI的实验表明,通过结合图像输入,GPT-4能够取得更好的回答效果。GPT的训练完成:早在2022年8月&#…

ChatGLM3设置角色和工具调用的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

实现spaCy训练词性标注模型
词性标注是指为输入文本中的单词标注对应词性的过程。词性标注的主要作用在于预测接下来一个词的词性,并为句法分析、信息抽取等工作打下基础。通常地,实现词性标注的算法有HMM(隐马尔科夫)和深度学习(RNN、LSTM等&…

手推FlinkML2.2(一)
Java
快速入门 # 本文档提供了一个关于如何使用Flink ML的快速入门。阅读本文档的用户将被指导提交一个简单的Flink作业,用于训练机器学习模型并提供预测服务。
求助,我卡住了!# 如果你遇到困难,请查看社区支持资源。特别是&…

MagicThoughts|让ChatGPT变得更智能的Finetuned数据集
近两个月,ChatGPT无疑都是AI领域最炙手可热的话题。而它的成功,也引发了行业内外对于对话式AI、LLM模型商业化应用可能性的思考。诚然,尽管就目前来看ChatGPT对大部分问答都能基本做到“对答如流”。但是,ChatGPT本质上依旧是预训…

【2021年2月新书推荐】Advanced Natural Language Processing with TensorFlow 2
各位好,此账号的目的在于为各位想努力提升自己的程序员分享一些全球最新的技术类图书信息,今天带来的是2021年2月由Apress出版社最新出版的一本关于NLP和机器学习的书,涉及的语言位python。
Advanced Natural Language Processing with Tens…

大规模文本分类参考(转发)
前几天在网上看到了一个blog关于大规模文本分类的内容,在这里转发保存一下。
大规模文本分类实践-知乎看山杯总结 原文地址:http://coderskychen.cn/2017/08/20/zhihucup/ 本文主要介绍了我在知乎看山杯机器学习挑战赛中的一些实验和总结,代…

NLP之汉语自动分词
汉语自动分词就是让计算机识别出汉语文本中的‘词’,在词与词之间自动加上空格或其他边界标记。
目录
一.汉语自动分词中的基本问题
1.1分词规范问题
2.2歧义切分问题
3.未登录词问题
二.汉语分词方法
1.N-最短路径方法
2.基于词的n元语法模型的分词方法
3…


论文笔记 ACL 2017|Exploiting Argument Information to Improve Event Detection via Supervised Attention
文章目录1 简介1.1 动机1.2 创新2 方法2.1 上下文表示学习2.2 事件检测3 实验4 总结1 简介
论文题目:Exploiting Argument Information to Improve Event Detection via Supervised Attention Mechanisms 论文来源:ACL 2017 论文链接:https:…

论文笔记 EMNLP 2019|Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event
文章目录1 简介1.1 动机1.2 创新2 相关工作3 方法3.1 输入表示3.2 实体识别3.3 文档级实体编码3.3.1 实体和句子编码3.3.2 文档级别编码3.4 基于实体的有向无环图的生成3.4.1 EDAG的建立3.4.2 任务分解3.4.3 记忆3.4.4 路径扩展3.4.5 优化3.4.5 训练4 实验5 总结1 简介
论文题…

word2vec之CBOW模型与skip-gram模型
在对自然语言进行处理时,首先需要面对文本单元表示问题。单词(words)作为常考虑的最小文本单元,因而,如何将单词表示成恰当的词向量(word vector)成为了研究者们研究的重点。最简单直观的方法是…


DPCNN:深度金字塔 CNN 文本分类网络
DPCNN(Deep Pyramid CNN),是2017年腾讯AI-Lab提出的一种用于文本分类的网络,可以称之为"深度金字塔卷积神经网络"。
论文:Deep Pyramid Convolutional Neural Networks for Text Categorization
在之前的博…
NLP系列项目一:skip-gram方法训练词向量(pytorch完整代码)
skip-gram方法训练词向量(pytorch完整代码)
欢迎移步小弟GitHub查看完整代码和训练使用的数据集
https://github.com/lyj157175/My_NLP_projects
尝试复现论文Distributed Representations of Words and Phrases and their Compositionality中训练词向…
【pytorch模型实现5】ChartextCNN
ChartextCNN模型实现
NLP模型代码github仓库:https://github.com/lyj157175/Models
import torch
import torch.nn as nn class ChartextCNN(nn.Module):6层卷积,3层全连接层def __init__(self, config):super(ChartextCNN, self).__init__()self.in_f…

ESIM网络结构总结以及代码详解
Enhanced LSTM for Natural Language Inference https://arxiv.org/pdf/1609.06038.pdf 文本匹配、文本相似度模型之ESIM https://blog.csdn.net/u012526436/article/details/90380840 如何又好又快的做文本匹配-ESIM https://zhuanlan.zhihu.com/p/337567073
1. 总体思路 2. …
图解Word2vec
作者: 龙心尘 时间:2019年4月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89077048
审校:龙心尘 作者:Jay Alammar 编译:张秋玥、毅航、高延 嵌入(embedding)是机…
收纳一些学习nltk过程中遇到的问题
NLP学习材料收纳
I>常见问题:
python3使用nltk.download()时出错的解决办法 / 离线安装nltk_data如何用Python从海量文本抽取主题?
II>电子书:
Python 自然语言处理 第二版
III>论文:
基于NLTK的中文文本内容抽取方…
NLP笔记:分类问题常用metrics整理
NLP笔记:分类问题常用metrics整理 0. 简介1. Accuracy2. Precision, Recall & F1 score 1. TP, FP, FN, TN2. Precision3. Recall4. F1 score 1. micro F12. macro F1 5. 代码实现样例 3. ROC & AUC 0. 简介
这里,我们来考察一下NLP分类问题中…
NLP笔记:浅谈字符串之间的距离
NLP笔记:浅谈字符串之间的距离 0. 引言1. 汉明距离2. 最长公共子串3. 编辑距离4. jaccard距离5. bleu & rouge & ……6. 总结 0. 引言
故事起源于工作的一个实际问题,要分析两个文本序列间的相似性,然后就想着干脆把一些常见的字符…
奇异值分解与LSA潜在语义分析
传统的向量空间模型(Vector Space Model)中,文档被表示成由特征词出现频率(或概率)组成的多维向量,然后计算向量间的相似度。向量空间模型依旧是现在很多文本分析模型的基础,但向量空间模型无法…
文本建模之Unigram Model,PLSA与LDA
LDA(Latent Dirichlet Allocation)是一个优美的概率图模型,可以用来寻找文本的主题。最近系统的学习了一下这个模型,主要参考了《LDA八卦》和July的博客《通俗理解LDA主题模型》。本文主要对文本建模进行梳理,其中的涉…

自动文摘(Automatic document summarization)方法综述(二)——基于最优化的(optimization-based)方法
在上一篇博客中,我总结了基于中心(centroid-based)的方法和基于图(graph-based)方法。这两类方法的重心都集中在给文本单元打分上,也就是判断文本单元对原始文档的覆盖度(coverage)或…
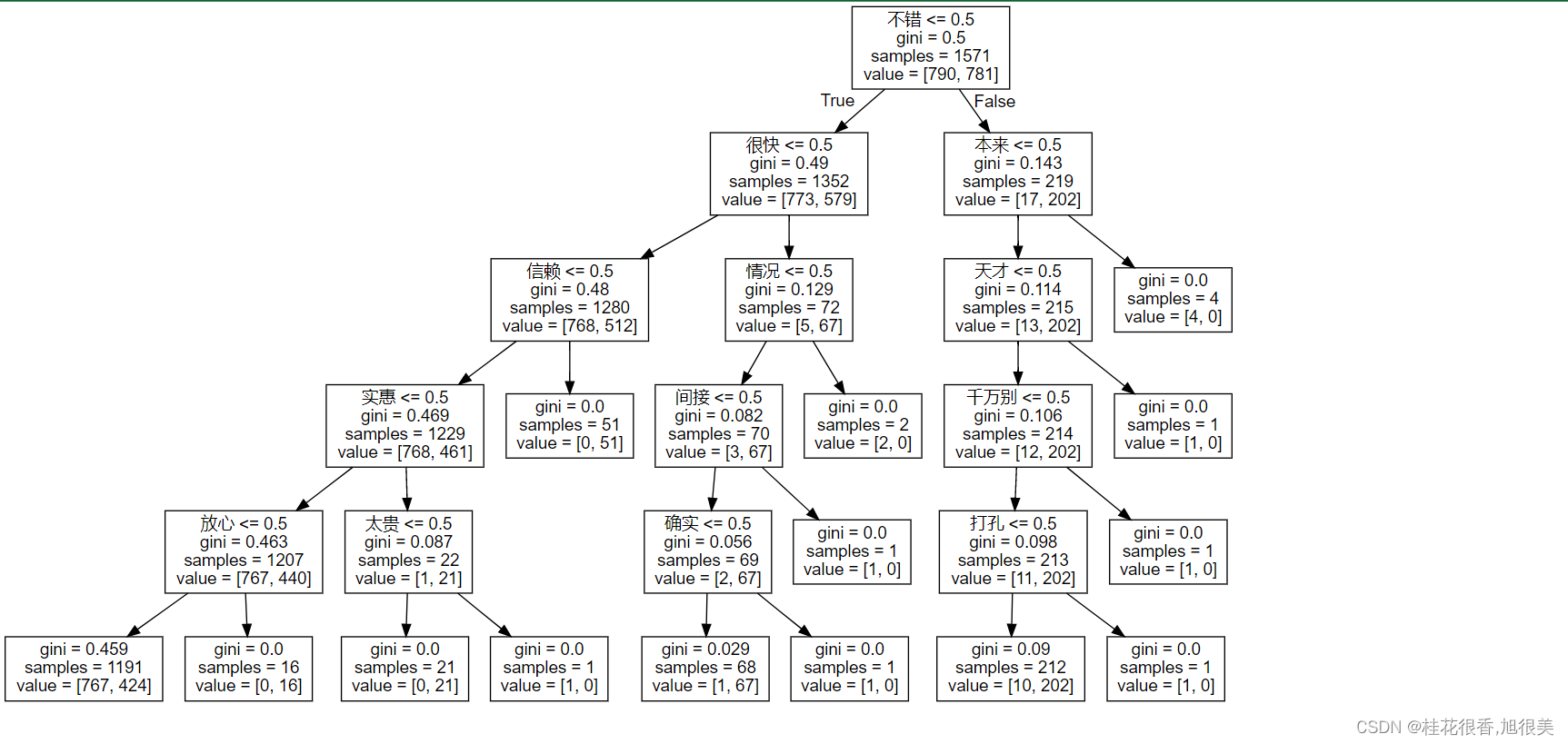

【论文学习】BiLSTM-CRF模型及pytorch代码详解
Bidirectional LSTM-CRF Models for Sequence Tagging
用于序列标注的双向LSTM-CRF模型
序列标注问题输入为特征序列,输出为类别序列。 大部分情况下,标签体系越复杂准确度也越高,但相应的训练时间也会增加。因此需要根据实际情况选择合适的…


论文笔记 IJCAI 2018|Constructing Narrative Event Evolutionary Graph for Script Event Prediction
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法2.1 构建记叙文事理图谱2.2 大规模图神经网络2.2.1 学习初始事件2.2.2 基于GGNN更新事件表示2.2.3 选择正确的后续事件4 实验5 总结1 简介
论文题目:Constructing Narrative Event Evolutionary Graph for Script E…

论文笔记 EMNLP 2019|Event Detection with Trigger-Aware Lattice Neural Network
文章目录1 简介1.1 动机1.2 创新2 方法2.1 分等级的表示学习2.2 Trigger-Aware 特征抽取2.3 序列标注3 实验4 总结1 简介
论文题目:EMNLP 2019 论文来源:Event Detection with Trigger-Aware Lattice Neural Network 论文链接:https://aclan…

论文笔记 ACL 2020|Cross-media Structured Common Space for Multimedia Event Extraction
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 文本事件抽取3.2 图像事件抽取3.3 跨媒体联合训练3.4 跨媒体联合推断4 实验5 总结1 简介
论文题目:Cross-media Structured Common Space for Multimedia Event Extraction 论文来源:ACL 2020 论文链…

论文笔记 中文信息学报 2019|基于联合标注和全局推理的篇章级事件抽取
文章目录1 简介1.1 动机2 方法3 实验1 简介
论文题目:基于联合标注和全局推理的篇章级事件抽取 论文来源:中文信息学报 2019 论文链接:https://kns.cnki.net/kcms/detail/detail.aspx?dbcodeCJFD&dbnameCJFDLAST2019& filenameMESS…
jieba源碼研讀筆記(十八) - 關鍵詞提取之TF-IDF使用示例
jieba源碼研讀筆記 (十八)- 關鍵詞提取之TF-IDF使用示例前言test/extract_tags.pytest/extract_tags_with_weight.py參考連結前言
jieba中除了給出TF-IDF算法實現外,還提供了它的使用示例。 使用示例在test這個資料夾底下,以下是…

NLP的基础任务及常见应用
NLP的两大核心任务:NLP NLU NLG
NLU(自然语言理解): NLG(自然语言生成): NLP的基础任务:
分词(前向最大匹配算法,后向最大匹配算法)词性标注&…

启英泰伦推出「离线自然说」,离线语音交互随意说,不需记忆词条
离线语音识别是指不需要依赖网络,在本地设备实现语音识别的过程,通常以端侧AI语音芯片作为载体来进行数据的采集、计算和决策。但是语音芯片的存储空间有限,通过传统的语音算法技术,最多也只能存储数百条词条,导致用户…

中文分词好用的pyhanLP包
HanLP: Han Language Processing 面向生产环境的多语种自然语言处理工具包(由一系列模型与算法组成的Java工具包),基于 TensorFlow 2.0,目标是普及落地最前沿的NLP技术。目前,基于深度学习的HanLP 2.0正处于alpha测试阶段,未来将实…
NLP系列项目三:Seq2Seq+Attention完成机器翻译
本项目尽可能复现Luong的attention模型,数据集小,只有一万多个句子的训练数据,所以训练出来的模型效果并不好。如果想训练一个好一点的模型,可以参考下面的资料。
课件
cs224d
论文
Learning Phrase Representations using RN…
jieba源碼研讀筆記(四) - 正則表達式
jieba源碼研讀筆記(四) - 正則表達式前言jieba/__init__.pyre_userdictre_engre_hanre_skipjieba/finalseg/__init__.pyre_hanre_skipjieba/posseg/__init__.py參考連結前言
jieba包含的三大功能:分詞、詞性標注及關鍵詞提取都需要用到正則表…

Transformer原理及代码实现解读
前言
2017横空出世的Transformer可谓是惊艳了所有人,再到2018年谷歌推出的BERT更是将其威力发挥到了极致,在NLP的11项下游任务中夺得SOTA结果,轰动了整个NLP领域。当然BERT取得的出色成绩并不是一蹴而就的,而是ELMO和GPT等预训练…

论文笔记 NAACL 2019|Event Detection without Triggers
文章目录1 简介1.1 动机1.2 创新2 方法2.1 输入2.2 单词和实体编码2.3 事件类型编码2.4 LSTM层2.5 注意力层2.6 输出层2.7 偏置loss函数3 实验3.1 多类别分类和二分类对比实验3.1.1 二分类3.1.2 多类别分类3.2 实验结果3.3 注意力向量分析3.4 loss中偏置的影响4 总结1 简介
论…

论元笔记 NAACL 2019|Adversarial Training for Weakly Supervised Event Detection
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 实例编码3.2 对抗训练3.2.1 辨别器3.2.2 生成器3.2.3 训练和实现细节3.3 弱监督场景的适应3.3.1 基于触发词的潜在实例发现3.3.2 半监督策略3.3.3 远程监督策略4 实验4.1 远程监督4.2 半监督4.3 人工评估4.4 例子研究5 总结…

论文笔记 EMNLP 2019|Cross-lingual Structure Transfer for Relation and Event Extraction
文章目录1 简介1.1 动机1.2 创新2 方法2.1 树结构的表示2.2 GCN编码2.3 在关系抽取中的应用2.4 在事件论元角色标注的应用3 实验4 总结1 简介
论文题目:Cross-lingual Structure Transfer for Relation and Event Extraction 论文来源:EMNLP 2019 论文链…
LLM 04-大模型的数据
LLM 03-大模型的数据 到目前为止,我们已经讨论了大型语言模型的行为(能力和损害)。现在,我们要剥开洋葱的第一层,开始讨论这些模型是如何构建的。任何机器学习方法的起点都是训练数据,因此这就是我们开始的…
NLP系列(5)_从朴素贝叶斯到N-gram语言模型
作者: 龙心尘 && 寒小阳 时间:2016年2月。 出处: http://blog.csdn.net/longxinchen_ml/article/details/50646528 http://blog.csdn.net/han_xiaoyang/article/details/50646667 声明:版权所有,转载请联系作者…
自动文摘(Automatic document summarization)方法综述(一)——基于中心的(Centroid-based)与基于图的(graph-based)方法
从Luhn1958年发表第一遍自动文摘论文开始,自动文摘(Automatic document summarization)一直是自然语言处理中最为活跃的分支。自动文摘希望通过计算机自动将冗长的文本压缩到规定长度内,同时保持原始文本主要信息不丢失。在信息爆…

论文笔记 ACL 2019|Exploring Pre-trained Language Models for Event Extraction and Generation
文章目录1 简介1.1 动机1.2 创新3 抽取模型3.1 触发词抽取3.2 论元抽取3.3 确定论元区间3.4 重新加权loss4 训练数据生成4.1 预处理4.2 事件生成4.2.1 论元替换4.2.2 重写附属token4.3 评分5 实验6 总结1 简介
论文题目:Exploring Pre-trained Language Models for…

文本分类中的词袋vs图vs序列
文本分类中的词袋vs图vs序列:质疑Text-graph的必要性和wide MLP的优势
摘要
图神经网络驱动了基于图的文本分类方法,成为了SOTA(state of the art)。本文展示了使用词袋(BoW)的宽多层感知器(MLP)在文本分类中优于基于图的模型TextGCN和HeteGCN…
一个完整推荐系统的设计实现
工业界完整推荐系统的设计。结论是: 没有某种算法能够完全解决问题, 多重算法交互设计, 才能解决特定场景的需求。下文也对之前的一些博文进行梳理,构成一个完整工业界推荐系统所具有的方方面面(主要以百度关键词搜索推…

NLP之自然语言处理入门方法
自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,包括:
1.句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。
2.信息抽…
Text-to-SQL小白入门(三)IRNet:引入中间表示SemQL
摘要
本文主要介绍了IRNet论文的基本信息,比如标题、摘要、数据集、结果&结论,以及论文中提出的不匹配问题和词汇问题以及对应的解决方案,重点学习了中间表示SemQL。
引言 学习论文时,可以先粗略看看论文标题-摘要-数据集-结…

《Improving BERT-Based Text Classification With Auxiliary Sentence and Domain Knowledge》论文笔记
模型
模型部分与Bert论文完全一致,只是为分类任务的输入样本构建了“辅助序列”——这种方法只适用于“单序列分类”,对于“语句相似性”等句对分类任务不适用。 上图输入部分的 aia_iai 表示的是人工构建的辅助序列的token。
作者提出三种构建“辅助…

nlp bert 模型蒸馏大全和工具
1. 各种蒸馏方案大全 2. 蒸馏工具
https://github.com/airaria/TextBrewer#quickstart
2.1 蒸馏步骤: 2.2. 方法:看起来比较简单
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig, DistillationCo…
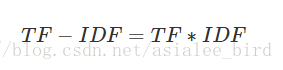
阅读——TF-IDF算法
博文TF-IDF算法介绍及实现主要介绍了TF-IDF,包括原理、不足、实战。阅读问题的提出中包含了对TF-IDF的拓展。 TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information …

逆向最大匹配法分词(补充)
def cut_word(sentence, word_dic):"""逆向最大匹配分词器sentence:待切分的句子word_dic:字典"""# 寻找字典中最大词的长度word_length_list [len(word) for word in word_dic]max_length max(word_length_list)# 创建…
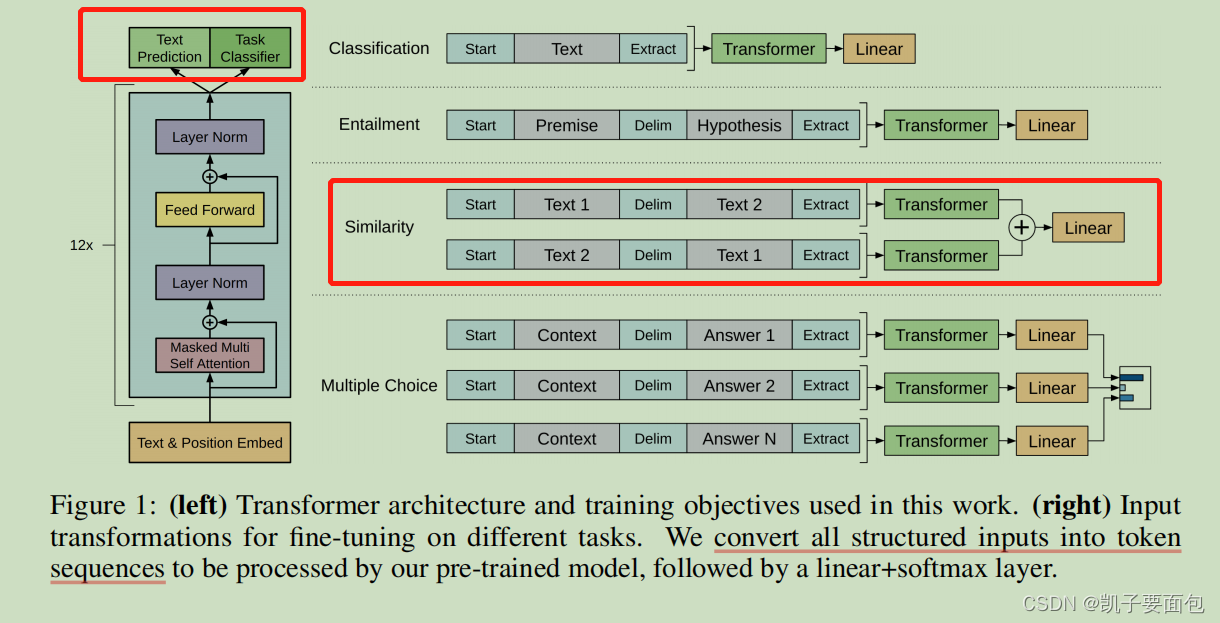
《Improving Language Understanding by Generative Pre-Training》论文笔记
引言
GPT(Generative Pre-Training) 受到 《Semi-Supervised Sequence Learning》与《Universal Language Model Fine-tuning for Text Classification》的启发,采用“预训练 Fine-tune” 两阶段的方式,在不降低模型效果的基础上…
天池NLP学习赛(1)赛题理解
天池NLP学习赛(1)赛题理解
题目
题目类型:新闻文本分类(字符识别问题)链接
数据: 赛题数据为新闻文本,并按照字符级别进行匿名处理,数字编码形式呈现。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教…
文件操作的常用技巧(持续更新)
目录 1. 统计文件的总行数2. 查看文件中的某一行3. 从文件中随机抽取若干行4. 划分文件&合并文件 1. 统计文件的总行数
使用 wc 命令:
wc -l filename | awk {print $1}使用 awk 命令:
awk END {print NR} filename使用 grep 命令:
g…

论文3:TextCNN总结
《Convolutional Neural Networks for Sentence Classification》
基于卷积神经网络的句子分类
作者:Yoon Kim(第一作者) 单位:New York University 会议:EMNLP2014 论文代码实现:https://github.com/lyj…

【AI视野·今日NLP 自然语言处理论文速览 第三十八期】Thu, 21 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 21 Sep 2023 Totally 57 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Chain-of-Verification Reduces Hallucination in Large Language Models Authors Shehzaad Dhuliawala, Mojt…

论文2:Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
从字符中生成嵌入:用于开放词表示的组合字符模型
论文复现代码:https://github.com/lyj157175/NLP_paper_reproduction 背景介绍 词向量的两个问题…

ChatGLM 大模型应用构建 Prompt 工程
文章目录 一、大模型简介1.1 大模型基础知识1.2 大模型分类 二、如何构建大模型应用2.1 To B、To C场景应用区别2.2 大模型在To B场景中的应用原则2.3 大模型应用技巧2.3.1 大模型应用技巧2.3.2 大模型的应用方法2.3.3 案例:车险问答系统 三、指令工程(p…
【论文学习】FastText总结
《 Bag of Tricks for Efficient Text Classification》
Fasttext: 对于高效率文本分类的一揽子技巧
论文背景:
文本分类是自然语言处理的重要任务,可以用于信息检索、网页搜索、文档分类等。基于深度学习的方法可以达到非常好的效果,但是…
jieba源碼研讀筆記(八) - 分詞函數入口cut及tokenizer函數
jieba源碼研讀筆記(八) - 分詞函數入口cut及tokenizer函數前言分詞函數cuttokenize函數參考連結前言
根據jieba文檔,jieba的分詞共包含三種模式,分別是:全模式、精確模式及搜索引擎模式。 其中的精確模式又分為不使用…

论文笔记 NAACL 2016|Joint Event Extraction via Recurrent Neural Networks
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 编码3.1.1 句子编码3.1.2 RNN编码3.2 预测3.2.1 触发词预测3.2.2 论元角色预测3.2.3 记忆向量3.2.4 训练3.3 词表示4 实验4.1 记忆单元4.2 词编码评测4.3 实验结果5 总结1 简介
论文题目:Joint Event Extractio…

Keras—embedding嵌入层的使用
最近在工作中进行了NLP的内容,使用的还是Keras中embedding的词嵌入来做的。
Keras中embedding层做一下介绍。
中文文档地址:https://keras.io/zh/layers/embeddings/
参数如下: 其中参数重点有input_dim,output_dim,非必选参数input_lengt…

自动文摘(Automatic document summarization)方法综述(三)——基于次模函数(submodular function)最大化的方法
自动文摘(Automatic document summarization)方法综述的第一篇文章(一)总结了基于中心的(Centroid-based)方法和基于图的(graph-based)方法,第二篇文章(二&am…

文献阅读:SimCSE:Simple Contrastive Learning of Sentence Embeddings
文献阅读:SimCSE:Simple Contrastive Learning of Sentence Embeddings 1. 文献内容简介2. 主要方法介绍3. 主要实验介绍 1. STS Experiment2. Downsteam Experiment 4. 讨论 1. loss function考察2. 其他正例构造方式考察3. 消解实验 5. 结论 & 思考…
暴露偏差(Exposure Bias)
暴露偏差(Exposure Bias)就是指训练时每个输入都来自于真实样本的标签,测试时输入却是来自上一个时刻的输出。
解决方案:通过概率选择,每次输入时以p的概率选择从真实数据输入,以(1-pÿ…
jieba源碼研讀筆記(十二) - 詞性標注(使用DAG有向無環圖+動態規劃)
jieba源碼研讀筆記(十二) - 詞性標注(使用DAG有向無環圖動態規劃)前言__cut_DAG_NO_HMM參考連結前言
在前篇中看到了POSTokenizer的詞性標注核心函數包括:__cut_DAG_NO_HMM及__cut,__cut_detail࿰…
jieba源碼研讀筆記(九) - 分詞之搜索引擎模式
jieba源碼研讀筆記(九) - 分詞之搜索引擎模式前言cut_for_search函數參考連結前言
jieba的分詞共包含三種模式,分別是:全模式、精確模式及搜索引擎模式。 其中精確模式(在jieba中為默認模式)又分為使用HMM…
NLP之隐马尔可夫模型
马尔可夫模型
在介绍隐马尔可夫模型之前,先来介绍马尔可夫模型。
我们知道,随机过程又称随机函数,是随时间而随机变化的过程。 马尔可夫模型(Markov model)描述了一类重要的随机过程。我们常常需要考察一个随机变量序…

G1D44-conlleval.perlargparseNER任务方法概述templateNER也有data imbalanced的问题吗
一、conlleval.perl
这个文件主要是用来评估crf的效果的。
二、argparse
argparse模块的作用是用于解析命令行参数。
三、NER方法概述
本来想搜一下feature-template,结果发现一篇妖魔版知乎hhhhh链接https://zhuanlan.zhihu.com/p/166496466
四、template
…
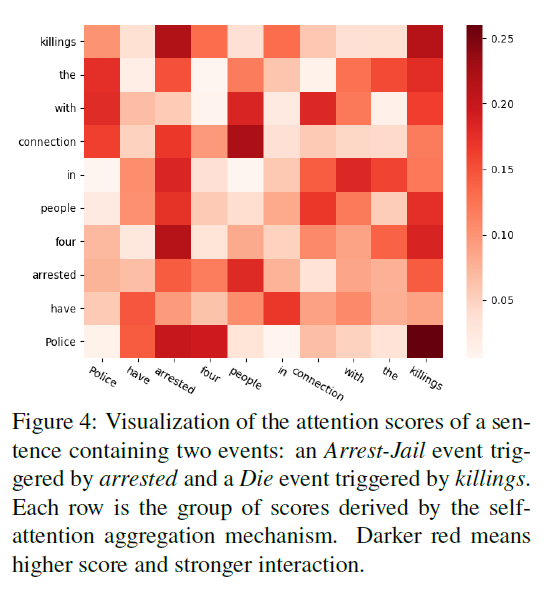
论文笔记 EMNLP 2018|Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation
文章目录1 简介1.1 动机1.2 创新2 背景知识3 方法3.1 word representation3.2 Syntactic Graph Convolution Network3.3 Self-Attention Trigger Classification3.4 Argument Classification3.5 Biased Loss Function4 实验5 总结1 简介
论文题目:Jointly Multiple…
jieba源碼研讀筆記(十一) - 詞性標注之POSTokenizer初探
jieba源碼研讀筆記(十一) - 詞性標注之POSTokenizer初探前言POSTokenizer類別初始化載入字典詞性標注核心函數詞性標注函數wrapper前言
前篇看了posseg/__init__.py檔的大架構,這裡將繼續介紹檔案中的POSTokenizer這個類別。 本篇僅介紹POST…

文献阅读:Universal Sentence Encoder
文献阅读:Universal Sentence Encoder 1. 文献内容简介2. 主要方法考察3. 实验结果梳理4. 结论 & 思考 文献链接:Universal Sentence Encoder
1. 文献内容简介
这篇文章算是考个古吧,前段时间看SNCSE(文献阅读:…

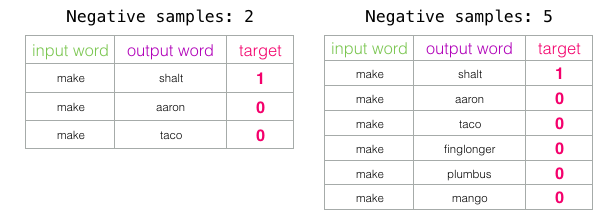
负采样:如何高效训练词向量
Negative Sampling
1.何为负采样
负采样是一种用于训练词嵌入模型的采样方法,特别适用于处理大规模词汇表的情况。负采样的目标是降低计算成本并改善模型的性能,同时有效地训练词向量。
2.为什么需要负采样
在传统的词嵌入模型中,如Word…

从Attention到Bert——2 transformer解读
从Attention到Bert——1 Attention解读 从Attention到Bert——3 BERT解读
1 为何引入Transformer 论文:Attention Is All You Need Transformer是谷歌在2017年发布的一个用来替代RNN和CNN的新的网络结构,Transformer本质上就是一个Attention结构&#x…
jieba源碼研讀筆記(二) - Python2/3相容
jieba源碼研讀筆記(二) - Python2/3相容前言_compat.py檔案get_module_res函數統一Python2/3函數的名稱strdecode函數resolve_filename函數參考連結前言
jieba的主程序是__init__.py,定義了cut, cut_for_search等用於分詞的函數。 在正式介紹…
jieba源碼研讀筆記(三) - 分詞之Tokenizer初探
jieba源碼研讀筆記(三) - 分詞之Tokenizer初探前言jieba/__init__.py中的Tokenizer類別類別架構__init__函數__repr__函數get_dict_file函數gen_pfdict函數initialize函數threading.LockLock與RLock的區別tempfiletempfile.gettempdirtempfile.mkstempos…

单步调试调用堆栈方法
在单步调试的过程中,vscode调用堆栈的部分会显示出各个函数以及调用的过程, 以前知道大概有这个功能,但是没用过,都是习惯了手动找函数,今天调试的时候用一下,确实非常地银性,非常地好用&#…
【pytorch模型实现6】FastText
FastText模型实现
NLP模型代码github仓库:https://github.com/lyj157175/Models
import torch
import torch.nn as nnclass FastText(nn.Module):def __init__(self, vocab_size, embedding_dim, max_len, num_label):super(FastText, self).__init__()self.embe…
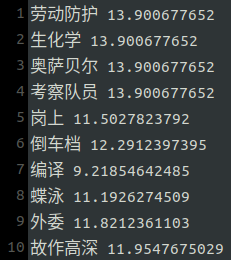
jieba关键词抽取(TF-IDF)与中文抽取式摘要
jieba关键词抽取有两种方法。一种是基于TF-IDF算法的关键词抽取,另一种是基于TextRank算法的关键词抽取。这里主要介绍TF-IDF。
TF-IDF TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种统计方法,用以评估一个词(关…

【AI视野·今日NLP 自然语言处理论文速览 第五十四期】Fri, 13 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 13 Oct 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models Authors Mengkang Hu, Yao M…

【AI视野·今日NLP 自然语言处理论文速览 第六十九期】Wed, 3 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 3 Jan 2024 Totally 24 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction Authors Zaratiana Ur…

文献阅读:Should You Mask 15% in Masked Language Modeling?
文献阅读:Should You Mask 15% in Masked Language Modeling? 1. 内容简介2. 实验考察 1. mask比例考察2. corruption & prediction3. 80-10-10原则考察4. mask选择考察 3. 结论 & 思考 文献链接:https://arxiv.org/pdf/2202.08005.pdf
1. 内…

从GPT到ChatGPT:我们离那个理想的AI时代到底还有多远?
写在前面
在2023年新年伊始,科技界最为爆火一款产品无疑是OpenAI公司出品的ChatGPT了,作为一名NLP领域从业者,似乎也好久没有看到如此热闹的技术出圈场景了。诚然从现象来看,无论从效果惊艳度、社会效应、商业价值、科技发展方向…
jieba源碼研讀筆記(一) - 分詞功能初探
jieba源碼研讀筆記(一) - 分詞功能初探前言jieba/__init__.pyTokenizer類別Tokenizer相關的全局函數全局函數_get_abs_path全局函數_replace_file正則表達式log相關函數並行分詞相關函數參考連結前言
jieba的分詞功能是由jieba這個模組本身及finalseg來…

一个简单的自然语言处理例子
例子是我学习的教程的一个例子,收集了一些客户对于饭店的评价,目标是将他们进行分类,分成好评和差评。 数据的前5项: 这里用到了一个之前没用到的包NLTK对我们的文本数据进行必要的处理,转化,使其变成能够…

花了一小时,拿python手搓了一个考研背单词软件
听说没有好用的电脑端背单词软件?只好麻烦一下,花了一小时,拿python手搓了一个考研背单词软件。 代码已经开源在我的github上,欢迎大家STAR! 其中,数据是存放在sqlite中,形近词跳转是根据jaro …

LangChain(0.0.339)官方文档三:Prompts上(自定义提示模板、使用实时特征或少量示例创建提示模板)
文章目录 一、 Prompt templates1.1 langchain_core.prompts1.2 PromptTemplate1.2.1 简介1.2.2 ICEL 1.3 ChatPromptTemplate1.3.1 使用role创建1.3.2 使用MessagePromptTemplate创建1.3.3 自定义MessagePromptTemplate1.3.3.1 自定义消息角色名1.3.3.2 自定义消息 1.3.4 LCEL…

NeurIPS-2022-多模态
1. Learning Distinct and Representative Modes for Image Captioning
2022 NeurIPSimage captioning:给定图像生成自然描述
即一张图片可以生成多个caption,希望这样可以从不同的角度去描述图片中的内容。
1.1 当前存在的问题
现有工作生成的image…

【AI视野·今日NLP 自然语言处理论文速览 第四十六期】Tue, 3 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 3 Oct 2023 (showing first 100 of 110 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Its MBR All the Way Down: Modern Generation Techniques Through the …

文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models
文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models 1. 文章简介2. 核心方法 1. Vanilla Self-Attention (V)2. Dense Synthesizer (D)3. Random Synthesizer (R)4. Factorized Model 1. Factorized Dense Synthesizer (FD)2. Fact…
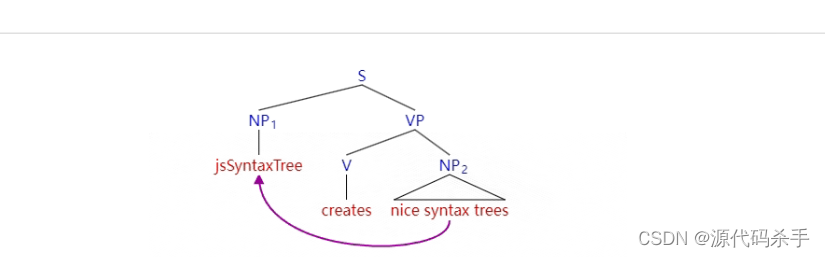
自然语言处理技术:NLP句法解析树与可视化方法
自然语言处理(Natural Language Processing,NLP)句法解析树是一种表示自然语言句子结构的图形化方式。它帮助将句子中的每个词汇和短语按照语法规则连接起来,形成一个树状结构,以便更好地理解句子的语法结构和含义。句法解析树对于理解句子的句法关系、依存关系以及语义角…

自然语言处理的多行业应用
在我们小时候,甚至是我们会走路或说话之前,就已经在察觉周围发出的声音了。我们倾听其他人发出的声响和声音。我们将声音组合成有意义的词语,例如“母亲”和“门”,并学习解读周围人的面部表情,以加深我们对词组的理解…
【从零开始实现意图识别】中文对话意图识别详解
前言
意图识别(Intent Recognition)是自然语言处理(NLP)中的一个重要任务,它旨在确定用户输入的语句中所表达的意图或目的。简单来说,意图识别就是对用户的话语进行语义理解,以便更好地回答用户…
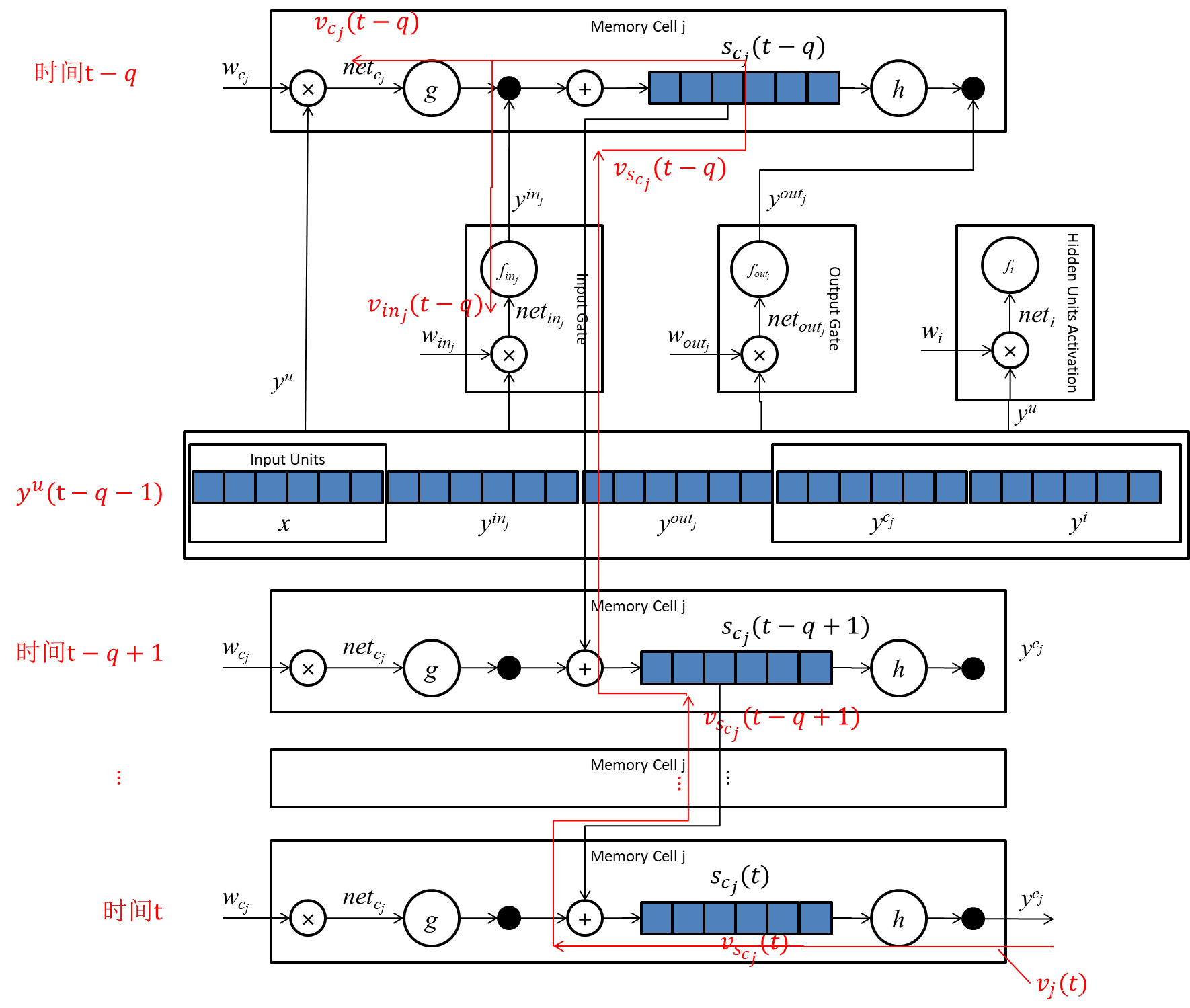
手搓GPT系列之 - 通过理解LSTM的反向传播过程,理解LSTM解决梯度消失的原理 - 逐条解释LSTM创始论文全部推导公式,配超多图帮助理解(下篇)
本文承接上篇上篇在此和中篇中篇在此,继续就Sepp Hochreiter 1997年的开山大作 Long Short-term Memory 中APPENDIX A.1和A.2所载的数学推导过程进行详细解读。希望可以帮助大家理解了这个推导过程,进而能顺利理解为什么那几个门的设置可以解决RNN里的梯…

能模仿韩寒小四写作的神奇循环神经网络
作者:寒小阳 && 龙心尘 时间:2016年4月 出处: http://blog.csdn.net/han_xiaoyang/article/details/51253274 http://blog.csdn.net/longxinchen_ml/article/details/51253526 声明:版权所有,转载请联系作…

自然语言处理学习笔记(八)———— 准确率
目录 1.准确率定义
2.混淆矩阵与TP/FN/FP/TN
3. 精确率
4.召回率
5.F1值
6.中文分词的P、R、F1计算
7.实现 1.准确率定义 准确率是用来衡量一个系统的准确程度的值,可以理解为一系列评测指标。当预测与答案的数量相等时,准确率指的是系统做出正确判…

Transformer回顾与细节
我们在《Seq2seq Attention模型详解》中,详细地回顾了以 RNN 为基础模块的Seq2seq模型。本文所讲述的Transformer也采用Seq2seq式的编码器-解码器结构,不过它摒弃了经典的 RNN,采用 self-Attention。由于并行计算、长时序建模、模型容量大等优…

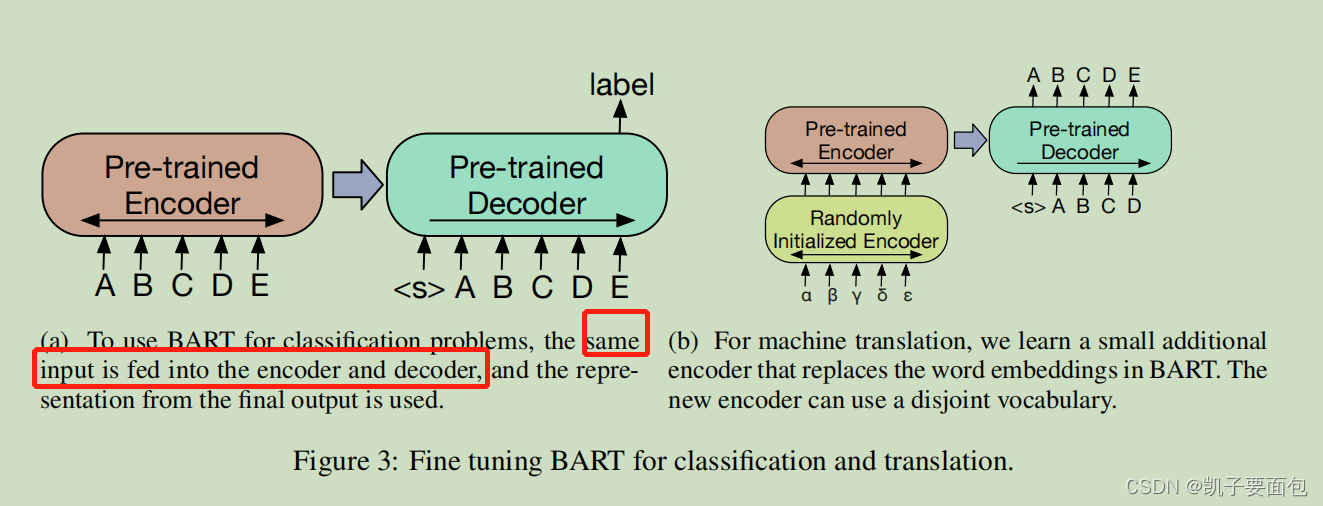
《BART: Denoising Sequence-to-Sequence Pre-training》论文笔记
模型结构
BART采用一种去噪自编码方法进行预训练,不同于BERT仅使用Transformer Encoder结构,BART使用Encoder-Decoder结构。Encoder类似BERT采用双向注意力,Decoder类似GPT采用Left2Right注意力。由于采用Seq2Seq结构,Encoder部分…
NLP-D18-POIROT很无语很多内容写上了都没被保存上
—0500以后任务都要严防死守啦!! 开始读论文!!!
一、POIROT:使用内核监听记录对齐攻击行为,实现网络威胁捕捉
(一)摘要: 1、原版 Cyber threat intelligenc…

NLP-D29-注意力机制在seq2seq中使用注意力
—0433 又是四点起床的一天。越来越清醒了。刚好也快放假了,完美过渡到居家状态,舒适。 今天的主要任务还是沐沐的课啦!还有多毕设答辩的精简,昨天讲了17分钟,太长了!!!先去写个日记…

NLP-D33-毕设答辩-《人类语言处理》04-05-Location-aware-attentionCTC大数据比赛报名答辩被从源头上暴
—0452虽然今天答辩,还是很早就起了,ppt还想改一遍,论文还想读一下。早上听了会《人类语言处理》04,就是补昨天的坑啦。讲到的是Location-aware attention,主要是说我们直接用attention做语音辨识的话,弹性…

看了这篇你还不懂BERT,那你就过来打死我吧
目录
1. Word Embedding. 1
1.1 基于共现矩阵的词向量... 1
1.2 基于语言模型的词向量... 2
2. RNN/LSTM/GRU.. 5
2.1 RNN.. 5
2.2 LSTM 通过门的机制来避免梯度消失... 6
2.3 GRU 把遗忘门和输入门合并成一个更新门... 6
3. seq2seq模型... 8
3.1 朴素的seq2seq模型.…

jieba源碼研讀筆記(六) - 分詞之精確模式(使用DAG有向無環圖+動態規劃)
jieba源碼研讀筆記(六) - 分詞之精確模式(使用DAG有向無環圖動態規劃)前言calc函數__cut_DAG_NO_HMM函數參考連結前言
本篇的主題是精確模式(不使用HMM,使用動態規劃),它是在Tokenizer這個類別中ÿ…
NLP-D46-nlp比赛D15
—0557昨天2点睡的(弄完12点啦,有点想熬夜hhh)早上5点多醒了,就醒了。
刚刚改了改程序,现在跑着; 自己去看论文啦!!!
2-不重要-已读 0-重要、需精读 1-重要、已读完 3-…
NLP-D50-nlp比赛D19-Deberta深入超级想做题+看论文新比赛++
—0724早上醒来就六点二十啦~~~吃完早饭就现在啦!!希望以后早上刷牙洗脸之类的能快点,尽快进入工作状态。 上午: 跑代码 学习原理 做任务3.1的inference 做任务3.2的inference
感觉最近一切都养成了很好的习惯,已经非…
jieba源碼研讀筆記(十六) - 關鍵詞提取之tfidf.py檔初探
jieba源碼研讀筆記(十六) - 關鍵詞提取之tfidf.py檔初探前言定義全局變數KeywordExtractor類別IDFLoader類別TFIDF類別前言
jieba支持使用兩種算法做關鍵詞提取,包括TF-IDF及TextRank。 其中TF-IDF算法主要是在jieba/analyse/tfidf.py這個檔…

NLP-D53-nlp比赛D22刷题D9《人类语言处理》p13深入Roberta量化D3
—0554已经读完三篇论文了,还算有收获,发现一篇很novel的,很喜欢。 现在开始刷题!!!
802区间和-离散化
我感觉这题还是很难理解的,而且二分又有点忘了。。 适用范围: “雷声大&…
NLP-D58-nlp比赛D27刷题D14读论文mathtype
—0612昨天晚上看The PHd. Grind 看到了大概一点,今天醒来就5点多了。要重整旗鼓,要乐观,要做自己喜欢的事情。最后要对这段旅程进行总结反思。 现在要读论文了! 在读的时候思考以下几个问题: 1、我在做的事情有什么价…

百度PaddleHub-ERNIE微调中文情感分析(文本分类)
PaddlePaddle-PaddleHub 飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。PaddleHu…

EMNLP 2023精选:Text-to-SQL任务的前沿进展(上篇)——正会论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…

RNN(电影评论情感分析: RNN循环网络原理及自然语言处 理NLP应用)
数据源:imdb.com 预处理
分词 词的数字化表示方法与词嵌入 更合理的方案 http://word2vec.googlecode.com/svn/trunk/
https://nlp.stanford.edu/projects/glove/
https://nlp.stanford.edu/projects/glove/ IMDB数据集获取与处理(非TF集成模式&#…
![[书生·浦语大模型实战营]——轻松玩转书生·浦语大模型趣味 Demo](https://img-blog.csdnimg.cn/direct/0c7f413061c645f199e18e38ff90515c.png)
[书生·浦语大模型实战营]——轻松玩转书生·浦语大模型趣味 Demo
Part1 大模型及InternLM模型简介
1.1 什么是大模型?
定义大模型通常指的是机器学习或人工智能领域中参数数量巨大、拥有庞大计算能力和参数规模的模型。这些模型利用大量数据进行训练,并且拥有数十亿甚至数千亿个参数。 发展大模型的出现和发展得益于增…

【文章学习】全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么?
原文:全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么? https://zhuanlan.zhihu.com/p/112719984
一、总体架构 二、query理解 三、提到的一些好的技术
知识蒸馏,利用soft target
Faiss库使用方法(一&am…
brat文本标注工具——安装
目录
一、Linux系统安装
1. centOS系统
2. Ubuntu系统
3. macOS系统
4.说明
二、Google Chrome安装
1. 打开命令行,切换到管理者权限
2. 安装依赖
3. 下载Google浏览器的安装包
4. 安装Google Chrome
三、yum更新
四、Apache安装
安装Apache
启动Apac…
最全中文停用词表(可直接复制)
最全的停用词表整理
词表名词表文件中文停用词表cn_stopwords.txt哈工大停用词表hit_stopwords.txt百度停用词表baidu_stopwords.txt机器智能实验室停用词库scu_stopwords.txt
以上停用词表链接:https://github.com/goto456/stopwords
以下是我常用的1893个停用词…

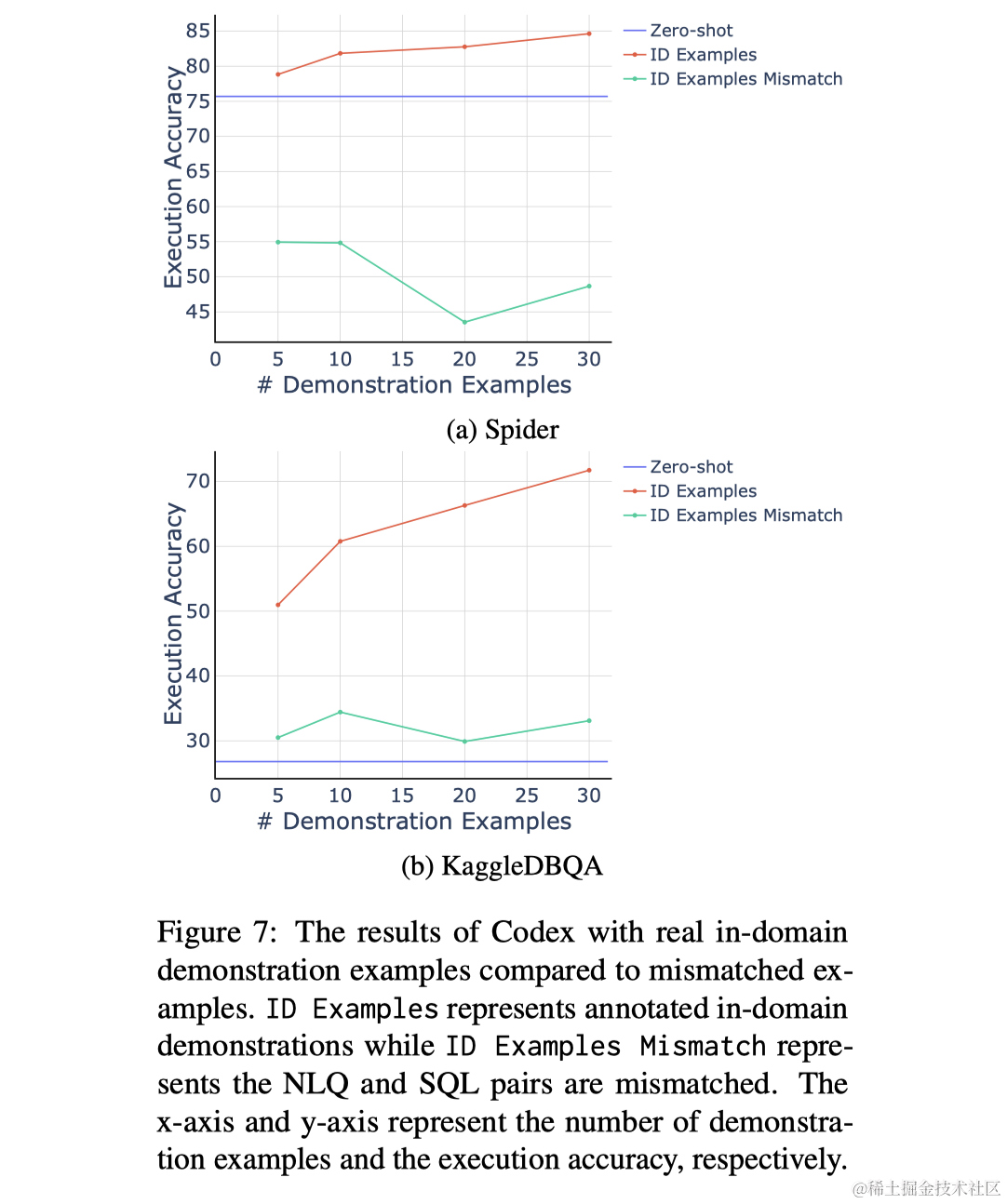
从领域外到领域内:LLM在Text-to-SQL任务中的演进之路
导语
本文介绍了ODIS框架,这是一种新颖的Text-to-SQL方法,它结合了领域外示例和合成生成的领域内示例,以提升大型语言模型在In-context Learning中的性能。
标题:Selective Demonstrations for Cross-domain Text-to-SQL会议&am…
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇--简洁版],支持Linux/Windows部署安装](https://img-blog.csdnimg.cn/img_convert/33d45a5081f5189406376336b54e5459.jpeg)
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇--简洁版],支持Linux/Windows部署安装
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲…
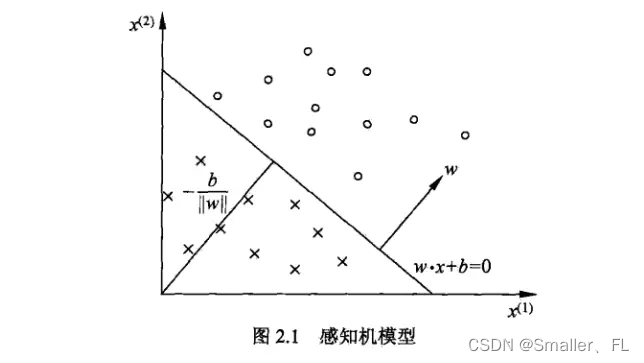
NLP深入学习(八):感知机学习
文章目录 0. 引言1. 感知机1.1 基本概念与结构1.2 学习策略 2. 感知机学习算法2.1 原始形式2.2 对偶形式 3. 参考 0. 引言
前情提要: 《NLP深入学习(一):jieba 工具包介绍》 《NLP深入学习(二):…
自然语言处理入门学习--切分算法
切分算法
分词算法的核心是速度。
1、完全切分
完全切分:找出一段文本中所有的分词。主要这实际上不是标准意义上的分词,因为这个算法会把单个字全部输出,并没有考虑到是否是有意义的词语序列。例如:“北京大学”切分得到的结果…

NLP成长计划(一)
Getting Set Up
需要安装的程序:
Anaconda 5.0.1 Python 3.6https://www.anaconda.com/download/ -- Python 3.6 可以更好地处理文本数据 -- Anacond 收集了流行的libraries以及packages.
XGboost
安装XGBoost:
conda install -c conda-forge xgboost…

「GPT」G、P、T分别是啥意思?
G意为Generative :生成式
比如,生成式的分类器(模型)包括---- generative classifiers: naive Bayes classifier and linear discriminant analysis
与之对应的为判别式----- discriminative model: logistic regression
P意为…

代码笔记 | bert-event-extraction
文章目录1 数据处理1.1 数据集1.2 预处理1.2.1 数据加载1.2.2 utiles2 模型2.1 触发词预测2.2 论元预测3 训练4 评测代码链接:https://github.com/nlpcl-lab/bert-event-extraction1 数据处理
1.1 数据集
数据集使用ACE 2005英文序列,数据集的解析过程…

【AI视野·今日NLP 自然语言处理论文速览 第四十八期】Thu, 5 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 5 Oct 2023 Totally 50 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Retrieval meets Long Context Large Language Models Authors Peng Xu, Wei Ping, Xianchao Wu, Lawrence McA…

【报错-已解决】Resource tagsets not found.
最近在接触nltk,已经在电脑里download nltk.data了,但程序还是报错Resource tagsets not found. 在电脑里查找tagset,发现tagset文件没有解压。 对tagset压缩包进行解压,并确认解压后的文件夹文件路径没有重复(tagsets)…
jieba源碼研讀筆記(十) - 詞性標注功能初探
jieba源碼研讀筆記(十) - 詞性標注功能初探前言jieba/posseg的目錄結構jieba/posseg/__init__.pyimport其它模組pair類別POSTokenizer類別POSTokenizer相關的全局變數及函數參考連結前言
jieba除了分詞,還包括了詞性標注及關鍵詞提取的功能。…

jieba源碼研讀筆記(五) - 分詞之全模式
jieba源碼研讀筆記(五) - 分詞之全模式前言get_DAG函數__cut_all函數參考連結前言
根據jieba文檔,jieba的分詞共包含三種模式,分別是:全模式、精確模式及搜索引擎模式。 其中的精確模式又分為不使用HMM兩種模式或使用…
FAQ 检索式问答系统学习记录
介绍
1. 背景
场景:假设有 一个 标准的问题库,此时有一个 新 query 进来,应该做什么操作? 灵魂三连问:
如何根据 这个 query,你怎么返回一个标准答案呢?如何从 问题库 里面找 答案࿱…

形式语言与自动机及其在NLP中的应用
摘要 形式语言与自动机是计算机科学的理论基础,对于计算机科学与技术专业人才的计算思维能力培养极其重要。本文首先从Chomsky谱系出发,对形式语言的概念和类别进行了阐述,然后按照形式文法与自动机之间的对应关系,介绍了四种自动…

SenticNet情感词典介绍
在进行情感分析时,一个好的情感词典能够让我们的工作事半功倍,较为出名的情感词典有SentiWordNet,General Inquirer等,这篇博客将介绍另外一个出色情感词典,SenticNet。
简介
当谈论SenticNet时,我们正在…
中文版GPT3——CPM(2.6B)微调长短文本生成(对应小说歌词)
CPM CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B。关于预训练模型的大量实验表明,更大的模型参数和更多的预训练数据,通常能…
2024年1月18日Arxiv最热NLP大模型论文:Large Language Models Are Neurosymbolic Reasoners
大语言模型化身符号逻辑大师,AAAI 2024见证文本游戏新纪元
引言:文本游戏中的符号推理挑战
在人工智能的众多应用场景中,符号推理能力的重要性不言而喻。符号推理涉及对符号和逻辑规则的理解与应用,这对于处理现实世界中的符号性…

Distilling the Knowledge in a Neural Network
论文地址
1. 学习记录 看完之后再看这个也不错: 论文笔记 《Distilling the Knowledge in a Neural Network》:https://luofanghao.github.io/blog/2016/07/20/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0%20%E3%80%8ADistilling%20the%20Knowledge%20in%20a…
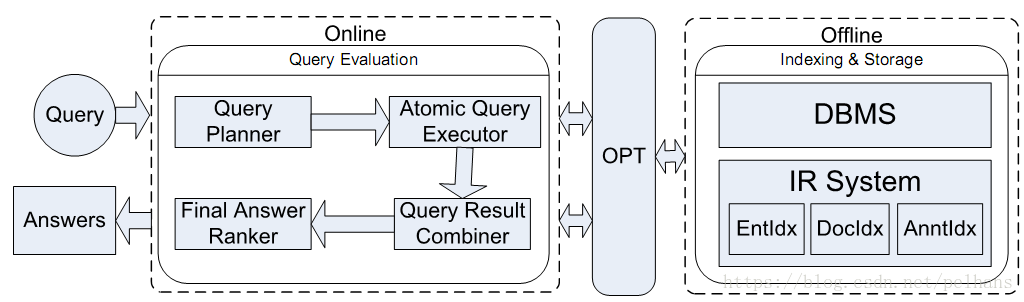
知识图谱入门 (八) 语义搜索
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节对语义搜索做一个简单的介绍,而后介绍语义数据搜索、混合搜索。该部分理解不深,后续会进一步补充。 语义搜索简介
什么是语义搜索,借用万维网…
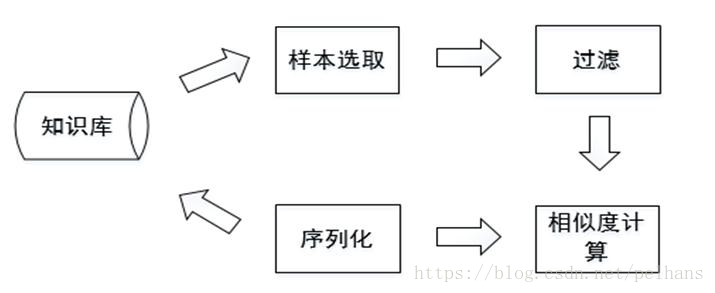
知识图谱入门 (六) 知识融合
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节主要介绍知识融合相关技术,首先介绍了什么是知识融合,其次对知识融合技术的流程做一个介绍并对知识融合常用工具做一个简单介绍。 知识融合简介
知识融合…
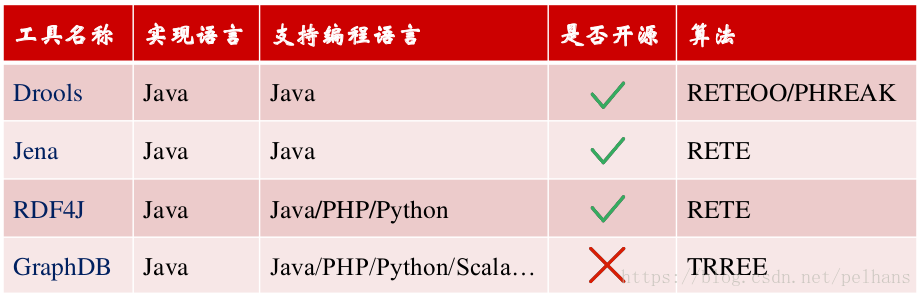
知识图谱入门 (七) 知识推理
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节对本体任务推理做一个简单的介绍,并介绍本体推理任务的分类。而后对本体推理的方法和工具做一个介绍。 知识推理简介
知识推理任务分类
所谓推理就是通过各种方法获…
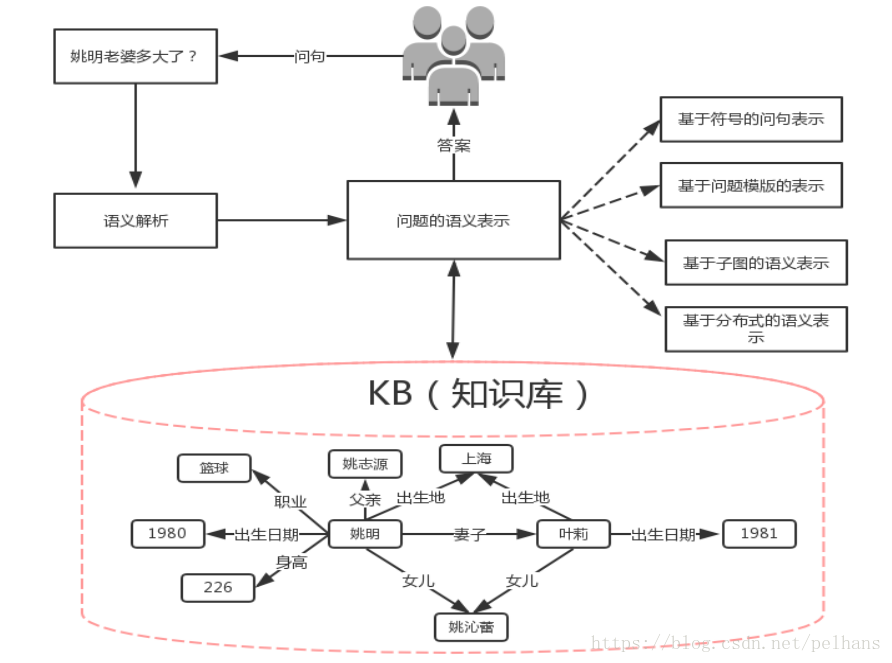
知识图谱入门 (一) 知识图谱与语义技术概览
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 知识图谱与语义技术概览。主要介绍知识表示、知识抽取、知识存储、知识融合、知识推理、知识众包、语义搜索、知识问答等内容。同时还包含一些典型的应用案例。若理解有偏差还请指正。…
知识图谱入门 (四) 知识挖掘
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节介绍了知识挖掘的相关技术,包含实体链接与消歧,知识规则挖掘,知识图谱表示学习。 知识挖掘
知识挖掘是指从数据中获取实体及新的实体链接和新…
知识图谱入门 (三) 知识抽取
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节介绍了针对结构化数据、非结构化数据、半结构化数据的知识抽取方法。 知识抽取的概念
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(结…

label-smoothing
标签平滑(label-smoothing)在one-hot的基础上,添加一个平滑系数ε ,使得最大预测与其它类别平均值之间差距的经验分布更加平滑。主要用于防止过拟合,增强模型的泛化能力。 Pytorch代码实现
import torchdef smooth_one_hot(true_labels: tor…

机器翻译的一些个人研究记录
机器翻译的发展 基于规则的机器翻译(70年代)
基于统计的机器翻译(1990年)
基于神经网络的机器翻译(2014年)
Google NMT 机器翻译框架
transformer机器翻译框架 lstmattention的机制实现 分词技术--自然…

TensorFlow2实战-系列教程11:RNN文本分类3
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 6、构建训练数据
所有的输入样本必须都是相同shape(文本长度,…
NLP中几个简单的,字符串相似度计算方法
文章目录 一、简单的需求二、技术需求:三、常见的几种简单技术四、几个示例1. 使用编辑距离 (Levenshtein Distance)2. 使用Jaccard相似度3. 使用jieba库进行分词以及结合余弦相似度来计算两个中文字符串相似度 一、简单的需求
最近在搞数据的治理工作,…
【第二课课后作业】书生·浦语大模型实战营-轻松玩转书生·浦语大模型趣味Demo
目录 轻松玩转书生浦语大模型趣味Demo课后作业1. 基础作业1.1 使用 InternLM-Chat-7B 模型生成 300 字的小故事:1.2 熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地 2. 进阶作业2.…

GPT-4发布:人工智能新高度,以图生文技术震撼,短时间内挤爆OpenAI模型付费系统
“GPT-4,起飞!”今日凌晨1点,OpenAI正式推出史上最强大的GPT-4文本生成AI系统
GPT-4:人工智能的新里程碑
你可能已经听说过GPT-3,它是一种能够生成自然语言文本的强大模型,可以用来回答问题、写文章、编程…

2016CCF 大数据与计算智能大赛——搜狗用户画像(NLP)
2016 CCF搜狗用户画像
队名:nice
排名: 66/894这个比赛本质上是一个自然语言处理(NLP)问题,或者更具体地就是文本分类(TC)问题。我们组的主要想法来自于自动化所宗成庆老师他们的一篇文章[Xia et al., 2012]以及网上一些博客的启发。
Brief introducti…

【AI视野·今日NLP 自然语言处理论文速览 第六十六期】Tue, 31 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 31 Oct 2023 (showing first 100 of 141 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
The Eval4NLP 2023 Shared Task on Prompting Large Language Models a…
NLP的tokenization
GPT3.5的tokenization流程如上图所示,以下是chatGPT对BPE算法的解释: BPE(Byte Pair Encoding)编码算法是一种基于统计的无监督分词方法,用于将文本分解为子词单元。它的原理如下: 1. 初始化:将…
Kaggle - LLM Science Exam(一):赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 deberta-v3-large 1k Wikiÿ…
python-词云生成
直接上代码!!!
import jieba.analyse
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGeneratorlyric =
f = open(./1.txt, r,encoding=utf-8)
for i in f:lyric += f.read()result = jieba.anal…
【HuggingFace文档学习】Bert的token分类与句分类
BERT特性:
BERT的嵌入是位置绝对(position absolute)的。BERT擅长于预测掩码token和NLU,但是不擅长下一文本生成。
1.BertForTokenClassification
一个用于token级分类的模型,可用于命名实体识别(NER)、部分语音标记…
ChatGPT“保姆级教程”——手把手教你1分钟快速制作思维导图(Markmap/Xmind+Markdown)
目录 前言使用ChatGPT生成markdown格式主题Markmap Markdown使用Markmap生成思维导图 Xmind Markdown使用Xmind生成思维导图 建议其它资料下载 前言
思维导图是一种强大的工具,它可以帮助我们整理和展现复杂的思维结构,提升我们的思考能力和组织能力。…

TinyBERT论文及代码详细解读
简介
TinyBERT是知识蒸馏的一种模型,于2020年由华为和华中科技大学来拟合提出。
常见的模型压缩技术主要分为:
量化权重减枝知识蒸馏
为了加快推理速度并减小模型大小,同时又保持精度,Tinybert首先提出了一种新颖的transforme…

从Attention到Bert——1 Attention解读
下一篇从Attention到Bert——2 transformer解读 文章目录1 Attention的发展历史2015-2017年2 Attention的原理3 Multi-Head Attention4 Self-Attention为什么需要self-attention什么是self-attention5 Position Embedding最早,attention诞生于CV领域,真正…
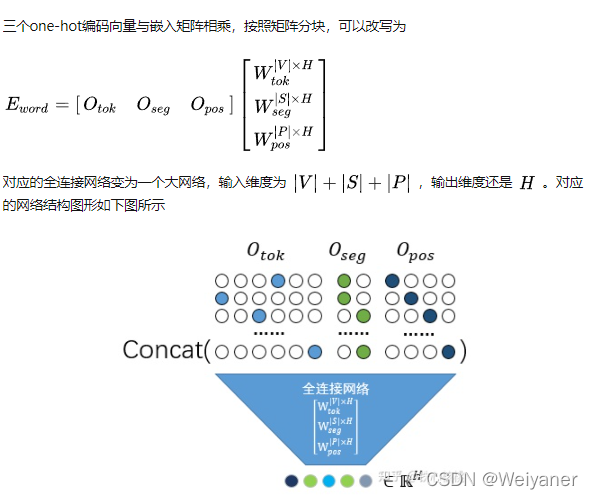
为什么Bert的三个Embedding可以进行相加,数学证明及代码
这是一个知乎上的经典问题,为什么 Bert 的三个 Embedding 可以进行相加?
其中,苏剑林老师的解释感觉很有意思: Embedding的数学本质,就是以one hot为输入的单层全连接。请参考: https://kexue.fm/archives/4122 也就…
AttributeError: module ‘hanlp.utils.rules‘ has no attribute ‘tokenize_english‘
附原文链接:http://t.csdnimg.cn/wVLib import hanlp tokenizer hanlp.utils.rules.tokenize_english tokenizer(Mr. Hankcs bought hankcs.com for 1.5 thousand dollars.) 改为: from hanlp.utils.lang.en.english_tokenizer import tokenize_eng…

【AI视野·今日NLP 自然语言处理论文速览 第五十五期】Mon, 16 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 16 Oct 2023 Totally 53 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming Au…
机器学习深度学习——NLP实战(自然语言推断——数据集)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——NLP实战(情感分析模型——textCNN实现) 📚订阅专栏:机器…

ChatGPT模型采样算法详解
ChatGPT模型采样算法详解
GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果语言模型(Cau…
大模型-迭代优化文本概括
迭代优化
在编写 Prompt 以使用 LLM 开发应用程序时,首先要有关于要完成的任务的想法,可以尝试编写第一个 Prompt,满足上一章说过的两个原则:清晰明确,并且给系统足够的时间思考。然后运行它并查看结果。如果第一次效…
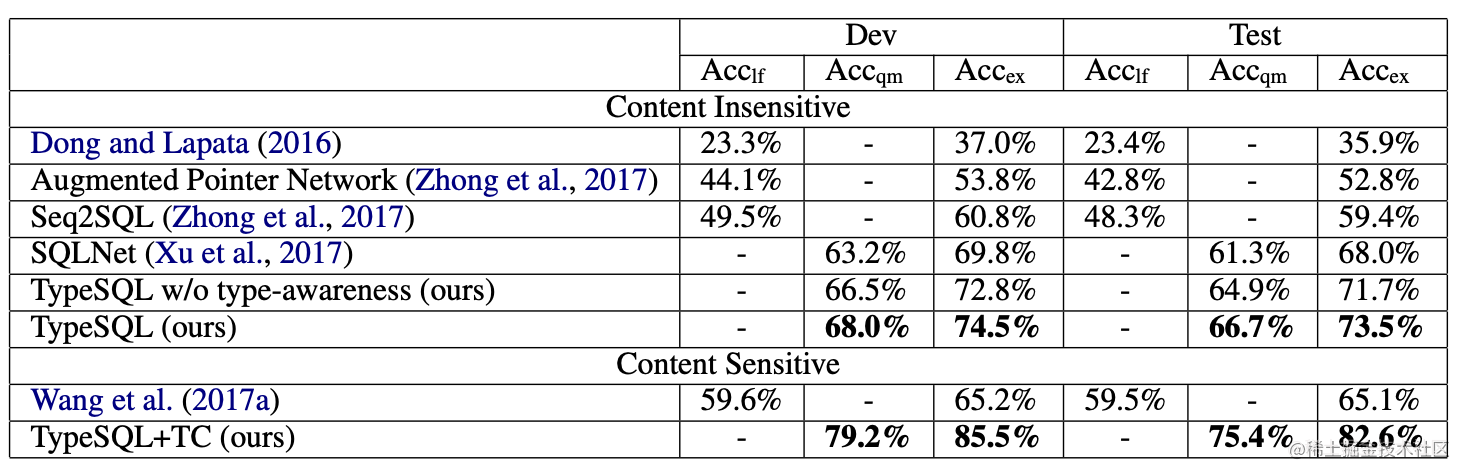
Text2SQL学习整理(三)SQLNet与TypeSQL模型
导语
上篇博客:Text2SQL学习整理(二):WikiSQL数据集介绍简要介绍了WikiSQL数据集的一些统计特性和数据集特点,同时简要概括了该数据集上一个baseline:seq2sql模型。本文将介绍seq2SQL模型后一个比较知名的…
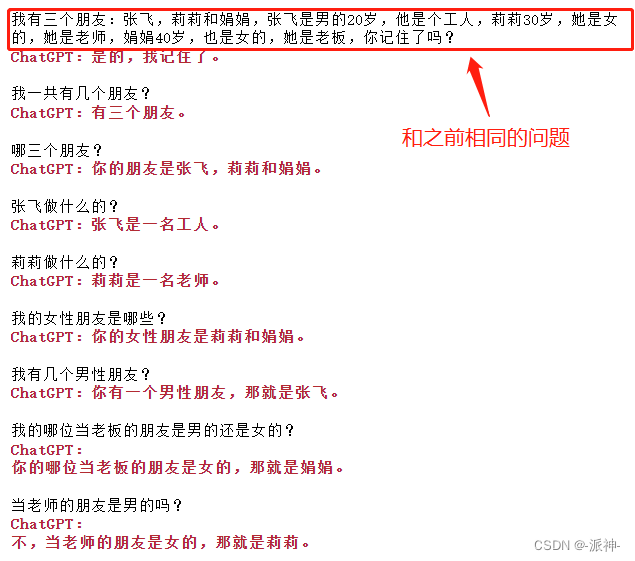
我让API版的ChatGPT长了记性!
OpenAI的API接口是基于请求/响应模式的,每次请求的上下文是独立的,不会被记录和保存。因此,ChatGPT机器人无法记录和理解上一次请求的内容,也不会把上下文信息带入到下一次请求中。请看下面我通过API调用的方式和ChatGPT的聊天记录…

从 ELMo 到 ChatGPT:历数 NLP 近 5 年必看大模型
目录AI21 LabsAlibabaAllen Institute for AIAmazonAnthropicBAAIBaiduBigScienceCohereDeepMindEleutherAIGoogleHuggingfaceiFLYTEKMetaMicrosoftNVidiaOpenAISalesforceTsinghua UniversityUC BerkeleyYandex持续更新中 ...参考团队博客: CSDN AI小组 先上 “万恶之源”&…

CS224W课程学习笔记(三):DeepWalk算法原理与说明
引言
什么是图嵌入? 图嵌入(Graph Embedding,也叫Network Embedding) 是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。…
Causal Language Modeling和Conditional Generation有什么区别
和ChatGPT一起学习!
因果语言建模(Causal Language Modeling,简称CLM)和条件生成(Conditional Generation)是自然语言处理(NLP)和深度学习中的两个相关概念。尽管它们在某种程度上有…
NLP论文解读:EMNLP 2020 Experience Grounds Language
来源:投稿 作者:Sally can wait 编辑:学姐 自然语言处理、乃至于人工智能最终要去往何方?功成名就的AI大牛们依然不停止思考这样抽象而宏大的问题,并积极引领着学界的思考方向。这篇文章的作者里,有深度学习…
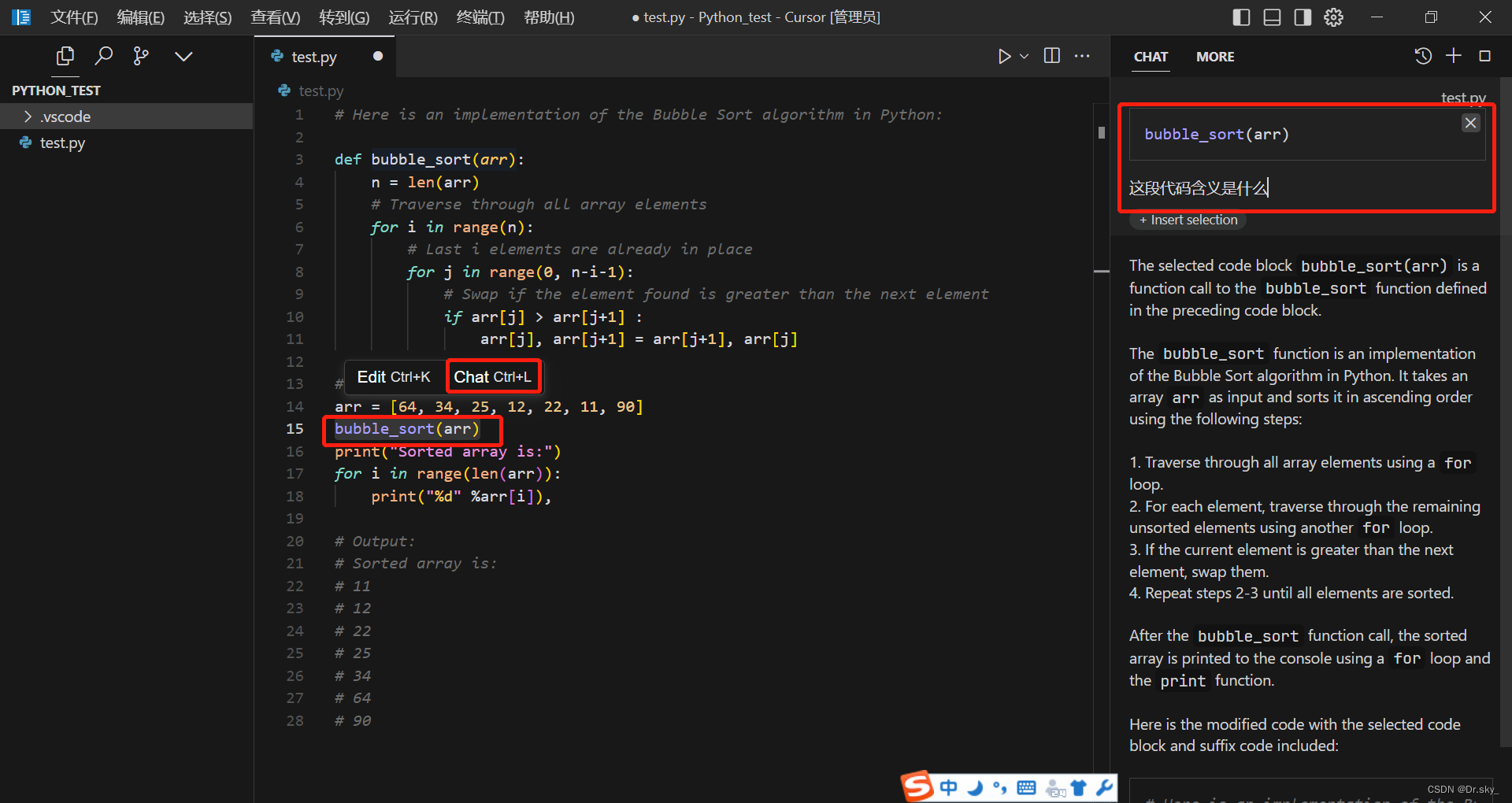
Chatgpt4快速写代码神器之Cursor
大家知道,用Chatgpt写代码,需要获得一定权限。最近发现了一款可以快速写代码的工具——Cursor,傻瓜式安装,只需关联Github即可正常使用,对本地电脑没有什么配置要求,写代码非常快,而且支持代码调…
AI 写的高考作文,你打几分?
又是一年高考时,高考真的是人生的一件大事,毕业这么多年,每次看到高考相关信息,还是会不由自主的点进来,其中语文的作文是每年大伙津津乐道的话题。
树先生今天就收到了某条小秘书的【邀请函】,邀请参与「…
NLP 作业:机器阅读理解(MRC)综述
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要是我的 NLP 作业——机器阅读理解的综述,内容很少涉及到模型的具体架构和相关理论的证明,而是注重于机器阅读理…
NLP自然语言处理介绍
自然语言处理(NLP,Natural Language Processing)是一门涉及计算机与人类语言之间交互的学科。它的目标是使计算机能够理解和生成人类语言,从而更好地处理和解析大量的文本数据。NLP不仅是人工智能领域中一个重要的分支,…


百度智能云正式上线Python SDK版本并全面开源!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…
NLP训练一个可以寻找相似度最匹配的句子的模型(LSI、LDA、TFIDF)
全套代码,不多解释,即插即用~ 英文句子预处理模块
# 英文句子处理模块
from nltk.corpus import stopwords as pw
import sys
import re
cacheStopWordspw.words("english")def English_processing(sentence):if sentence:senten…
前端JS如何实现对复杂文本进行句子分割,将每句话拆分出来?
文章目录 切割句子背景简介前端如何使用NLP?技术实现 切割句子背景简介 开发中遇到一种场景,在做文本翻译这块需求时,需要对输入的原文进行一句一句话的拆分出来,传给后台,获取每句话的翻译结果,便于实现页…

NLP成长计划(二)
Setup
假设您已经完成了(一)所需的设置。
在本讲座中,我们将使用 Gensim和NLTK,这两个广泛使用的Python自然语言处理库。 如果我们想要能够对文本进行分类,我们需要能够根据文章、段落、句子和文本的其他主体所包含的…
神经网络语言模型(NNLM)/word2vec学习
在学习这块的时候卡在了对于训练目标的确定上,目标函数是什么?随时函数又改怎么确定?主要的难点在于像推荐算法、图片识别等模型均有明显的目标去训练,什么是高潜用户?那张图片上面有一只狗,但是语言模型的目标较为抽象…
【NLTK系列01】:nltk库介绍
一、说明 NLTK是个啥?它是个复杂的应用库,可以实现基本预料库操作,比如,、将文章分词成独立token,等操作。从词统计、标记化、词干提取、词性标记,停用词收集,包括语义索引和依赖关系解析等。
…
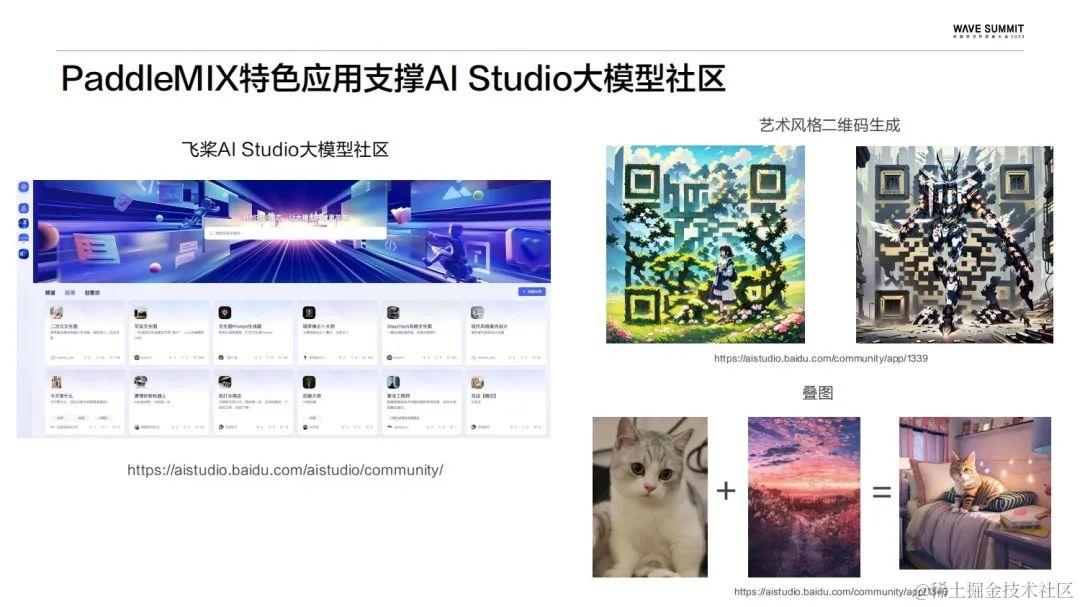
飞桨大模型套件:一站式体验,性能极致,生态兼容
在Wave Summit 2023深度学习开发者大会上,来自百度的资深研发工程师贺思俊和王冠中带来的分享主题是:飞桨大模型套件,一站式体验,性能极致,生态兼容。 大语言模型套件PaddleNLP
众所周知PaddleNLP并不是一个全新的模型…

【2021年新书推荐】Getting Started with Google BERT
各位好,此账号的目的在于为各位想努力提升自己的程序员分享一些全球最新的技术类图书信息,今天带来的是2021年1月由Packt出版社最新出版的一本关于NLP的书,涉及的架构为Google的BERT。
Getting Started with Google BERT 作者:Sudharsan Rav…
亲测可用国产GPT人工智能
分享一些靠谱、可用、可以白嫖的GPT大模型。配合大模型,工作效率都会极大提升。
清华大学ChatGLM
官网:
智谱清言中国版对话语言模型,与GLM大模型进行对话。https://chatglm.cn/开源的、支持中英双语的1300亿参数的对话语言模型࿰…

清华大学ChatGLM-6B部署运行
一、模型介绍
开源项目:
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构&…

第三章(1):自然语言处理概述:应用、历史和未来
第三章(1):自然语言处理概述:应用、历史和未来 目录第三章(1):自然语言处理概述:应用、历史和未来1. 自然语言处理概述:应用、历史和未来1.1 主要应用1.2 历史1.3 NLP的新…
《Deep learning Based Text Classification:A comprehensive Review》文本综述
介绍
深度学习综述年年有,今年特别多。随着深度学习在机器学习领域的快速发展,对每个任务进行算法的总结对于之后的发展是有益的。综述可以梳理发展脉络,对比算法好坏,并为以后的研究方向进行启发。本文是在NLP领域中重要的任务-…
nltk download所需包
众所周知,nltk需要download一些文件才能用,但由于网络不通畅,经常下载不下来。官方链接在这里:点击官方链接
我已经帮大家下载好了必备的几个文件,资源在这里,不必担心网络问题,仅需0积分&…
自然语言处理入门学习(二)--字典树
字典树
1、字典树
字典树:trie树,用树结构来描述词典。
树状结构每条边代表一个字符,字符串是一条路径节点可以存储value单词对应的是路径
字典树相对于普通树的结构来说,就是类似带权重的树,只是权重不是数字&…
用于 LLM 的公开的数值数据
用于 LLM 的公开的数值数据
这个存储库包含了用于训练 OpenAI 的大型语言模型的一部分公开的数值数据。这些数据已经被处理成符合 OpenAI 的数据管道格式。此外,我们还提供了一个 Python 脚本,用于将原始的表格数据转换成适合训练的格式。
数据来源
这…
自然语言处理从入门到应用——自然语言处理(Natural Language Processing,NLP)基础知识
分类目录:《自然语言处理从入门到应用》总目录 自然语言通常指的是人类语言,是人类思维的载体和交流的基本工具,也是人类区别于动物的根本标志,更是人类智能发展的外在体现形式之一。自然语言处理(Natural Language Pr…
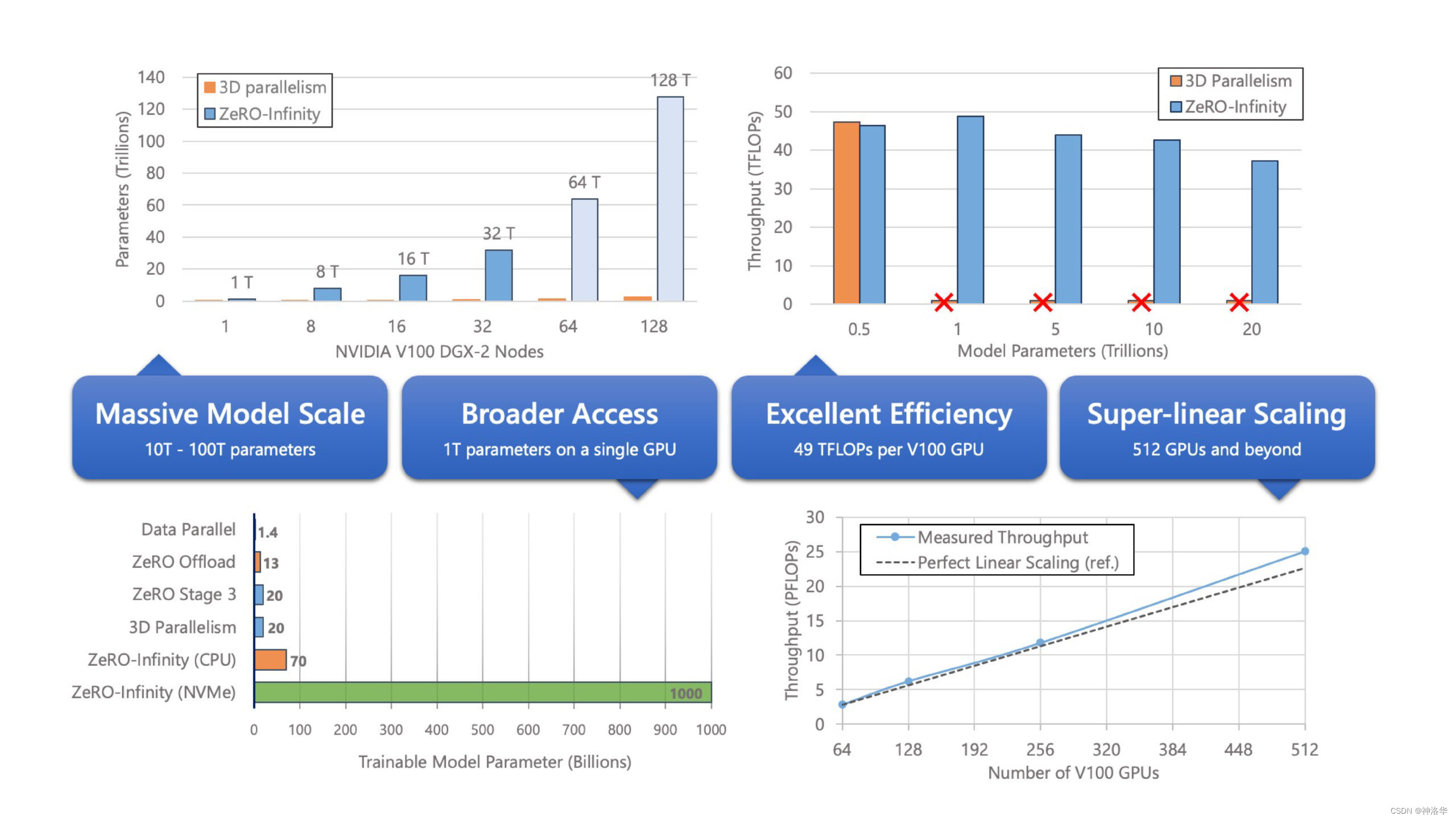
DeepSpeed教程
DeepSpeed github地址、DeepSpeed 官网 、DeepSpeed API文档、huggingface DeepSpeed文档、知乎deepspeed入门教程、微软deepspeed博客 文章目录 一、DeepSpeed简介和安装1.1 ZREO简介1.2 DeepSpeed简介1.3 DeepSpeed安装 二、使用DeepSpeed启动训练2.1 命令行参数配置2.2 多GP…

NLP文本分类--词向量
1.基于规则,对于要提取的分类维护一个dict,在dict里面保存需要提取的关键词,存在关键词的对应标记为分类;(缺点,不断的去维护词典) 2.基于机器学习:HMM(分词最常用的),CRF,SVM,LDA,C…

文本纠错--N-gram--Macbert模型的调用以及对返回结果的处理
文本根据词典进行纠错 输入一段可能带有错误信息的文字, 通过词典来检测其中可能错误的词。 例如:有句子如下:中央人民政府驻澳门特别行政区联络办公室1日在机关大楼设灵堂 有词典如下:中国人民,中央人民&#x…

基于neo4图数据库的简易对话系统
文章目录 一、环境二、思路第一步:输入问句第二步:针对问句进行分析,包括意图识别和实体识别第三步:问句转化第四步:问题回答的模板设计 三、代码解读1. 项目结构2. 数据说明3. 主文件kbqa_test.py解读4. entity_extra…
【Bert、T5、GPT】fine tune transformers 文本分类/情感分析
【Bert、T5、GPT】fine tune transformers 文本分类/情感分析 0、前言text classificationemotions 数据集data visualization analysisdataset to dataframelabel analysistext length analysis text > tokenstokenize the whole dataset fine-tune transformersdistilbert…
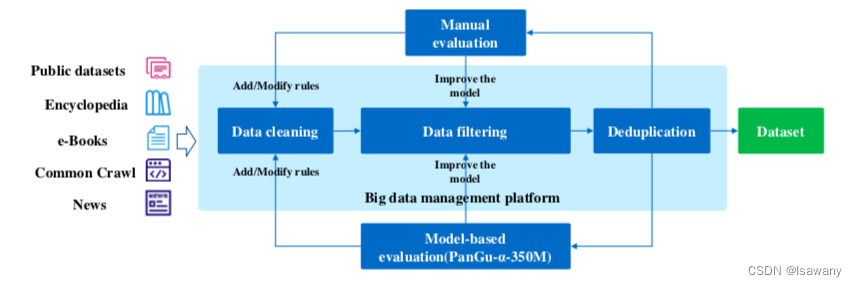
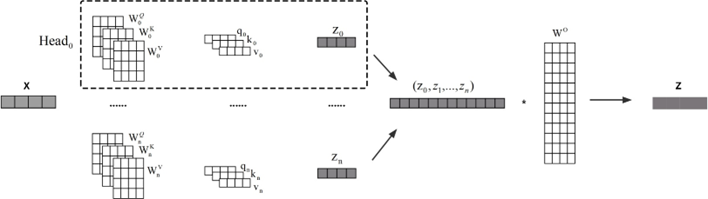
论文笔记--PANGU-α
论文笔记--PANGU-α: LARGE-SCALE AUTOREGRESSIVE PRETRAINED CHINESE LANGUAGE MODELS WITH AUTO-PARALLEL COMPUTATION 1. 文章简介2. 文章概括3 文章重点技术3.1 Transformer架构3.2 数据集3.2.1 数据清洗和过滤3.2.2 数据去重3.2.3 数据质量评估 4. 文章亮点5. 原文传送门6…
吴恩达 ChatGPT Prompt Engineering for Developers 系列课程笔记--03 Iterative
03 Iterative
本节主要通过代码来讲解如何在迭代中找到合适的prompt。对于初学者来说,第一次使用Prompt不一定得到语气的结果,开发者可以采用下述流程进行迭代优化:
给出清晰、具体的指令如果结果不正确,分析原因调整prompt重复…

NeurIPS 2020 | MiniLM:通用预训练模型压缩方法
基本信息
机构: 微软研究院
作者: Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, Ming Zhou
论文地址: https://arxiv.org/abs/2002.10957
论文代码: https://github.com/microsoft/unilm/tree/master/minilm
摘要…
ACL2020论文阅读笔记:BART
背景
题目: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 机构:Facebook AI 作者:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Moha…

ICML 2020论文笔记:地表最强文本摘要生成模型PEGASUS(天马)
文章目录背景摘要介绍模型预训练目标GSG预训练语料和下游任务实验结果消融研究Larger模型效果处理低资源数据集人工评测总结:Google发布天马-地表最强文本摘要生成模型,打败人类,我只要1000个样本)
背景
机构:Google Research 作者…
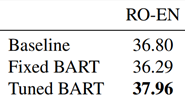
深度学习实战19(进阶版)-SpeakGPT的本地实现部署测试,基于ChatGPT在自己的平台实现SpeakGPT功能
大家好,我是微学AI,今天给大家带来SpeakGPT的本地实现,在自己的网页部署,可随时随地通过语音进行问答,本项目项目是基于ChatGPT的语音版,我称之为SpeakGPT。
ChatGPT最近大火,其实在去年12月份…

ICLR2020论文阅读笔记reformer: THE EFFICIENT TRANSFORMER
0. 背景
机构:Google Research 、U.C. Berkeley 作者:Nikita Kitaev、Łukasz Kaiser、Anselm Levskaya 论文地址:https://arxiv.org/abs/2001.04451 收录会议:ICLR2020 论文代码:https://github.com/google/trax/tre…
ChatGPT的Reward模块的替代方案
Reward Model 是用 Policy Model 的预测结果 再人工标注 得到的训练数据 训练的,这个训练 Reward Model 数据也可以是text-generation格式的。
替代方案1
Policy Model 的预测结果 再人工标注 得到的(本来给Reward Model的)训练数据 直接用…
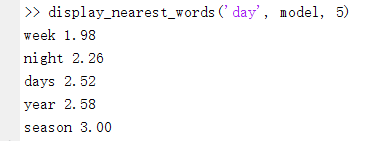
Hinton神经网络公开课编程题2--神经概率语言模型(NNLM)
Hinton神经网络公开课编程题2--神经概率语言模型(NNLM) 注:这只是一个小白做作业的总结感悟,并没有什么高大上的东西,甚至可能很low,错误很多。如果有错误欢迎指正这周的编程题主要是实现一个神经概率语言模…

OpenAI-ChatGPT最新官方接口《聊天交互多轮对话》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(二)(附源码)
目录Chat completions Beta 聊天交互前言Introduction 导言Response format 提示格式Managing tokensCounting tokens for chat API calls 为聊天API调用标记计数Instructing chat models 指导聊天模型Chat vs Completions 聊天与完成FAQ 问与答其它资料下载Chat completions B…
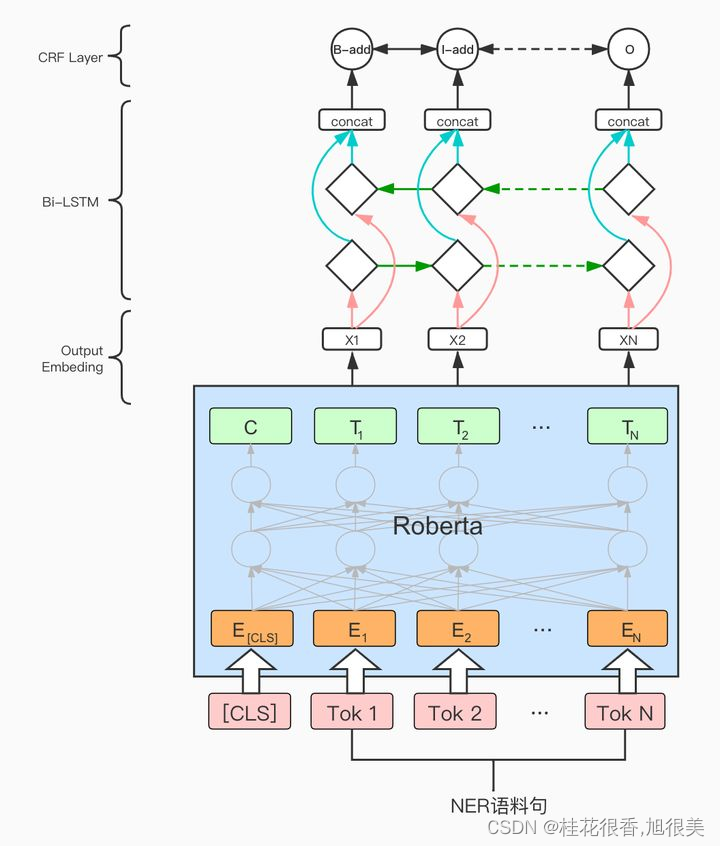
bert 和crf设置不同学习率(pytorch)
做ner 经典模式 bert crf,但是bert 和crf 的学习率不同:你的CRF层的学习率可能不够大 # 初始化模型参数优化器# config.learning_rate 3e-5no_decay [bias, LayerNorm.weight]optimizer_grouped_parameters [{params: [p for n, p in model.named_pa…
SentenceTransformers
SentenceTransformers 是一个可以用于句子、文本和图像嵌入的Python库。 可以为 100 多种语言计算文本的嵌入并且可以轻松地将它们用于语义文本相似性、语义搜索和同义词挖掘等常见任务。
论文: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
…
限制训练时GPU显存使用量
Pytorch
import torch
# 限制0号设备的显存的使用量为0.5,就是半张卡那么多,比如12G卡,设置0.5就是6G。
torch.cuda.set_per_process_memory_fraction(0.5, 0)
torch.cuda.empty_cache()
# 计算一下总内存有多少。
total_memory torch.cuda…

tf2.0做LSTM情感分析(二分类、2020李宏毅hw4)
前言
这段时间在做李宏毅ML/DL网课的第四次作业(2020),李老师讲得真的很棒,如果想自学的话我把课程链接放在这儿李宏毅2020网课,里面所有作业的数据集也放在这里:所有作业数据集,提取码&#x…

OpenAI-ChatGPT最新官方接口《嵌入向量式文本转换》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(五)(附源码)
Embeddings 嵌入向量式文本转换前言Overview 概述What are embeddings? 什么是嵌入?How to get embeddings 如何获取嵌入python代码示例cURL代码示例Embedding models 嵌入模型Second-generation models 第二代模型First-generation models (not recommended) 第一…
知识图谱入门 (九) 知识问答
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节对知识问答的概念做一个概述并介绍KBQA实现过程中存在的挑战,而后对知识问答主流方法做一个介绍。 知识问答简介
问答系统的历史如下图所示: 可以看出&am…
【视频】超越BERT的最强中文NLP预训练模型艾尼ERNIE官方揭秘
分章节视频链接:http://abcxueyuan.cloud.baidu.com/#/course_detail?id15076&courseId15076完整视频链接:http://play.itdks.com/watch/8591895
艾尼(ERNIE)是目前NLP领域的最强中文预训练模型。
百度资深研发工程师龙老师…

NLP系列(4)_朴素贝叶斯实战与进阶
作者: 寒小阳 && 龙心尘 时间:2016年2月。 出处:http://blog.csdn.net/han_xiaoyang/article/details/50629608 http://blog.csdn.net/longxinchen_ml/article/details/50629613 声明:版权所有,转载请联系作者…

NLP系列(3)_用朴素贝叶斯进行文本分类(下)
作者: 龙心尘 && 寒小阳 时间:2016年2月。 出处: http://blog.csdn.net/longxinchen_ml/article/details/50629110 http://blog.csdn.net/han_xiaoyang/article/details/50629587 声明:版权所有,转载请联系作者…
![[NLP] SentenceTransformers使用介绍](https://img-blog.csdnimg.cn/b1132f4d07904512bc5382d4135d7f68.png)
[NLP] SentenceTransformers使用介绍
SentenceTransformers 是一个可以用于句子、文本和图像嵌入的Python库。 可以为 100 多种语言计算文本的嵌入并且可以轻松地将它们用于语义文本相似性、语义搜索和同义词挖掘等常见任务。
该框架基于 PyTorch 和 Transformers,并提供了大量针对各种任务的预训练模型…
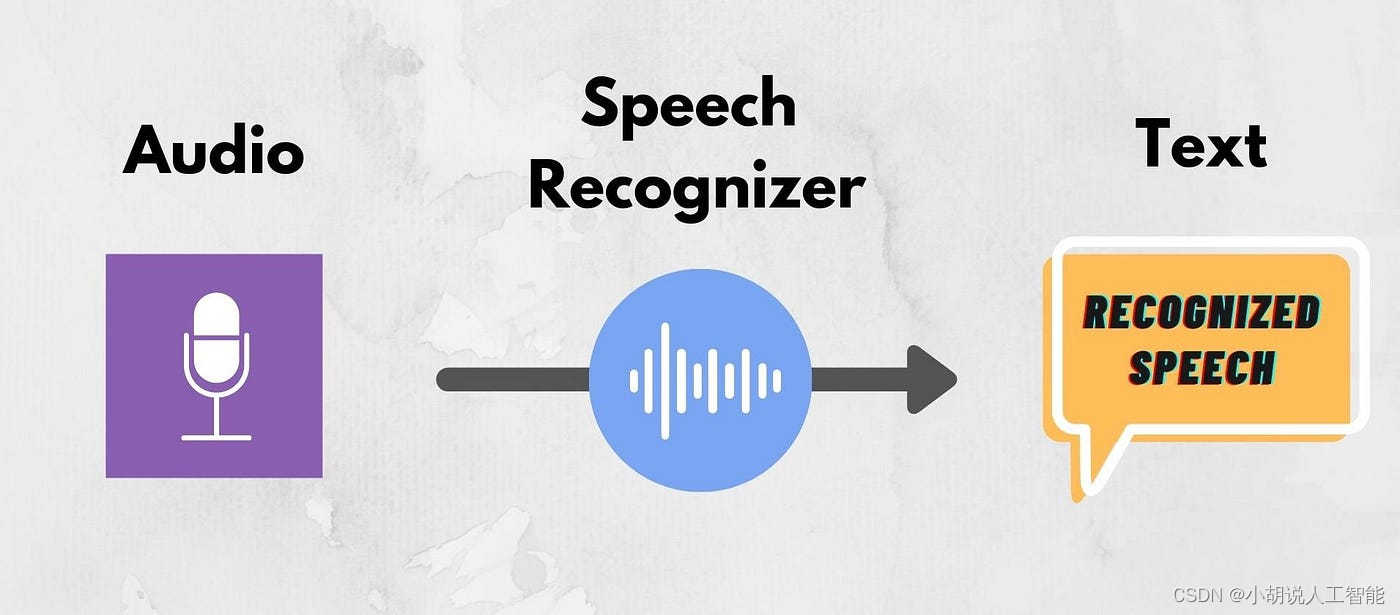
OpenAI-ChatGPT最新官方接口《语音智能转文本》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(六)(附源码)
Speech to text 语音智能转文本 Introduction 导言Quickstart 快速开始Transcriptions 转录python代码cURL代码 Translations 翻译python代码cURL代码 Supported languages 支持的语言Longer inputs 长文件输入Prompting 提示其它资料下载 Speech to text 语音转文本 Learn how…

基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍
一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…

ChatGLM-6B 中文对话模型复现、调用模块、微调及部署实现(更新中)
ChatGLM-6B-PT
一、前言
近期,清华开源了其中文对话大模型的小参数量版本 ChatGLM-6B(GitHub地址:https://github.com/THUDM/ChatGLM-6B)。其不仅可以单卡部署在个人电脑上,甚至 INT4 量化还可以最低部署到 6G 显存的…

【文本聚类】一篇文章弄懂三种聚类算法(K-Means,Agglomerative,DBSCAN)
概述
▶ 常用的聚类方法
核心思想常见算法划分聚类将给定的数据集,采用分裂法划分为K个类K-Means, CLARANS层级聚类根据数据点之间的相似度创建一颗有层次的树Agglomerative(聚合), Divisive(分裂)密度聚类当一片区域内的数据点的密度大于某个阀值,则认…
Transformer Encoder-Decoer 结构回顾
有关于Transformer、BERT及其各种变体的详细介绍请参照笔者另一篇博客:最火的几个全网络预训练模型梳理整合(BERT、ALBERT、XLNet详解)。
本文基于对T5一文的理解,再重新回顾一下有关于auto-encoder、auto-regressive等常见概念&…

【文本分类】基于两种分类器实现影评的情感分析(SVM,KNN)
支持向量机(Support Vector Machine, SVM)
当线性不可分时,就进行升维;接着就可以使用线性分类器了理论上来说,对任何分类问题,SVM都可以通过选择合适的核函数来完成核函数的选择直接影响到 SV…

NLTK载入自己的语料库
假如自定义语料库(loli.txt)的完整文件路径如下:
Users/samarua/Documents/NLP自然语言处理/自定义语料/loli.txt语料内容假设为:
loli loli loliPlaintextCorpusReader 纯文本语料库阅读器
from nltk.corpus import PlaintextCorpusReader corpus_ro…

文献阅读:AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization
AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization 1. 内容简介2. 原理 & 模型结构3. 实验 1. 模型预训练语料 & 数据处理2. 中文语料下的finetune实验 1. 分类任务中效果2. 阅读理解任务中效果3. sota模型对比 3. 英文语料下的finetune实验 1. 分…
NLP笔记:中文分词工具简介
中文分词工具简介 0. 引言1. jieba分词 1. jieba分词的基本用法2. jieba分词的进阶版用法 1. 全模式的分词2. 自定义领域词表加入 3. 使用jieba进行关键词抽取 1. tf-idf关键词抽取2. TextRank关键词抽取 2. pyltp分词 1. 分词模块调用方法2. pos模块调用方法3. ner模块调用方…
小型中文版聊天机器人
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、简单介绍与参考鸣谢
二、数据集介绍
三、数据预处理
1、重复标点符号表达
2、英文标点符号变为中文标点符号
3、繁…
baichuan-7B: 开源可商用支持中英文的最好大模型
背景
baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。
基于 Transformer 结构,在大约1.2万亿 tokens 上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。
在标准的中文和英文权威 benchmark(C-…
LLM系列 | 11: LangChain危矣?亲测ChatGPT函数调用功能:以天气问答为例
简介
春水碧于天,画船听雨眠。小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖五连鞭的小男孩。紧接前面几篇ChatGPT Prompt工程和应用系列文章:
04:ChatGPT Prompt编写指南05:如何优化ChatGPT Prompt?06:C…
Elasticsearch:使用 Elasticsearch 矢量搜索和 FastAPI 构建文本搜索应用程序
在我的文章 “Elastic:开发者上手指南” 的 “NLP - 自然语言处理及矢量搜索”,我对 Elastic Stack 所提供的矢量搜索有大量的描述。其中很多的方法需要使用到 huggingface.co 及 Elastic 的机器学习。这个对于许多的开发者来说,意味着付费使…


【NAACL 2019】《 Adversarial Domain Adaptation Using Artificial Titlesfor Abstractive Title Generation》
【NAACL 2019】《 Adversarial Domain Adaptation Using Artificial Titlesfor Abstractive Title Generation》阅读笔记
英文标题:Adversarial Domain Adaptation Using Artificial Titlesfor Abstractive Title Generation 中文翻译:利用人工标题生成…

【ArXiv 2020】Tinybert: Distilling bert for natural language understanding
这篇文章基于语义空间嵌入和掩码语言模型来给 NLU 任务做增强,具体的做法是:
首先利用BERT的分词器将序列中的单词分为多个词块(word pieces),BERT有两大分词器,BasicTokenizer 和 WordpieceTokenizer&…

【ACL 2021】《 DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations》
【ACL 2021】《 DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations》阅读笔记
英文标题:DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations 中文翻译:DeCLUTR:无监督文本表示的深度…
【COLING 2018】Sequence-to-sequence data augmentation for dialogue language understanding
基于 seq-seq 生成模型的对话语言理解 DA
这篇文章的应用场景十分符合序列标注任务能用到的 DA 技术,核心是 Seq2Seq模型:输入一种表述的句子,生成不同表述的新句子。为了进一步鼓励多样化生成,我们把一种新的多样性等级嵌入到话…
【EMNLP2021】Data Augmentation for Cross-Domain Named Entity Recognition
链接: https://arxiv.org/abs/2109.01758 代码:https://github.com/RiTUAL-UH/style_NER. Abs& Intro 本文研究了通过数据投影将高资源域的数据投影至低资源域。具体来说,我们提出了一种新的神经架构,通过学习模式(…



spacy 用已经token化,分词的list 列表作为输入
2022/1/11更新 针对新版3.0处理
import spacy
nlp spacy.load(en_core_web_sm)
from spacy.tokens import Doc
doc Doc(nlp.vocab, words[Conceptually, cream, skimming, has, two, basic, dimensions, -, product, and, geography, .])
# Tagger(doc)
for name,tool in n…

使用padlle hub进行BERT Fine-Tune 中文-文本分类/蕴含 下游任务
使用padlle hub进行BERT Fine-Tune 中文-文本分类/蕴含 下游任务写在前面1.相关技术PaddleHub:预训练模型:Bert_chinese_L-12_H-768_A-12Bert下游任务2.使用步骤-以文本蕴含为例环境准备数据处理数据集解压数据集数据集展示处理数据集自定义Hub数据集PaddleHub分类数…

达观杯文本处理模型实践
tf-idflr
采用前文处理的tf-idf文件进行简单的模型预测,没有加入交叉验证。 代码如下: 这里用到了前几篇文章中处理的数据,用pickle读取即可,当时之所以分批保存到不同的pickle文件是因为内存不够直接存在一个文件中内存报错&…
用Stanford Parse(智能语言处理)去实现分词器
昨天研究学习了一下 Stanford Parse ,想利用 Stanford Parse 智能切词的效果结合到lucene 分词器中的想法;由于项目时间
仓促,部分研究没有完成。代码还存在bug,希望有这方面想法的小伙伴们,能完善。。 lucene版本&a…
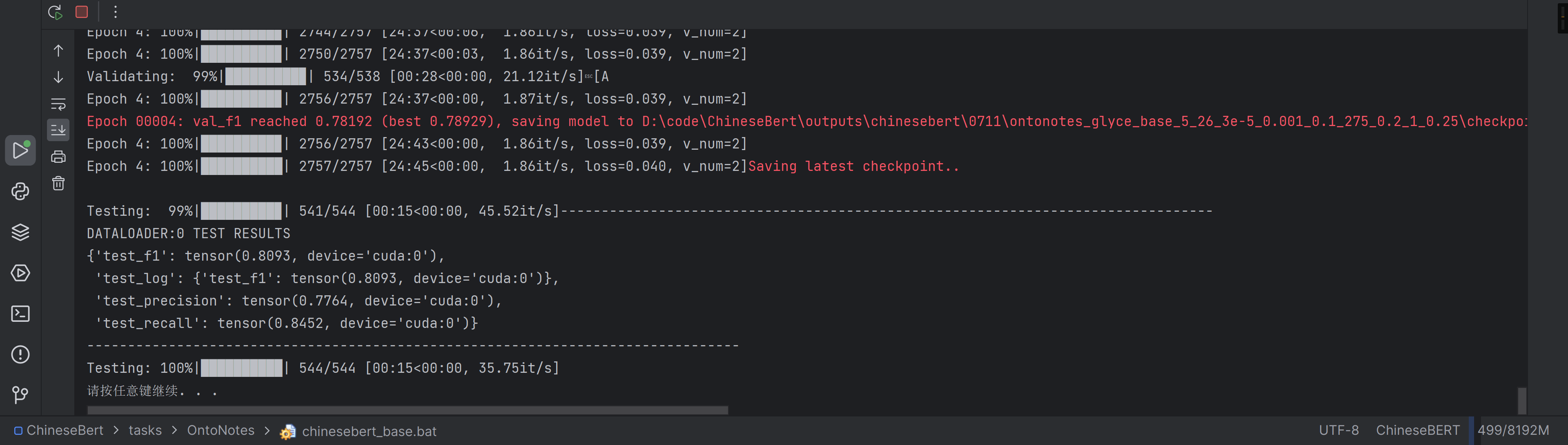
复现论文ChineseBERT(ONTONOTES数据集)
记录一下自己复现论文《ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information》的过程,最近感觉老在调包,一天下来感觉什么也没干,就直播记录一下跑模型的过程吧
事前说明,这是跑项目的实况,如…
nlp中文本相似度计算问题
文章的目的:文本相似度计算一直是nlp中常见的问题,本文的目标是总结并对比文本相似度计算方法。当然文本的相似度计算会有进一步的应用,比如文本的分类、聚类等。 文章结构:本文先介绍最直接的字面距离相似度度量,而后…

【论文学习】ALBERT
目录简介ALBERT三大改进简介
为了加速计算,以及克服hidden size 、hidden layer等超参数值增大,导致模型退化的问题,ALBERT(A Lite BERT)提出来两种参数优化的技术——“embedding layer分解、跨层参数共享”…

《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》论文笔记
引言
《Semi-supervised Sequence Learning》
《Semi-supervised Sequence Learning》论文中提出了两种预训练方法,来提升LSTM模型的泛化能力。一种预训练方法,作者称为“sequence autoencoder”,本质就是一种“seq2seq”模型结构ÿ…
自然语言处理nlp 数据集下载地址
代表性的数据集、基准(预训练)模型、语料库、排行榜。本文选择一系列有一定代表性的任务对应的数据集,做为测试基准的数据集。这些数据集会覆盖不同的任务、数据量、任务难度。
中文数据集下载
中文语言理解测评基准: https://www.cluebenchmarks…

阅读理解机器问答系统
机器问答系统流程如下图所示: 具体过程:
(1)准备知识库,可以从维基百科或者百度百科中获取,知识库主要是存储实体与实体介绍文本,也就是百科中的词条与词条介绍。
(2)流…

Synthtext 数据集
Synth text 数据集官网下载的主要包含图像文件夹和gt.mat标注文件,共85万(858750)多张图片数据。该数据集中包含了词级别标注、字符级别标注和文本识别内容,可用于文本检测和文本识别模型。
1、mat格式标注文件读取,采…
自己用的停用词(2955个)
停用词多就是好啊,先记下来,以后增加的话再增 、
老
有时
以前
。
一下
要不然
──
者
dont
〈
等到
反过来说
〉
一一
《
》
古来
your
准备
往往
而
「
」
怎
挨个
without
『
』
【
these
‐
】
逐渐
再者
–
—
would
〔
就是
怕
―
〕
‖
〖
甚至
…

![[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记](https://img-blog.csdnimg.cn/9d909061f81a4c58a4cd7c9a0c40e1d4.png)
[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记
[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记
motivation:
大多数知识库问答方法都是基于语义分析的。在本文中,作者解决了由多个实体和关系组成的复杂语义解析的学习向量表示问题。以前的工作主要集中在为一个问题选择…

【coling 2020】Attentively Embracing Noise for Robust Latent Representation in BERT
原文链接:https://aclanthology.org/2020.coling-main.311.pdf intro
本文针对ASR转化成文本之后的文本分类任务进行鲁棒性研究。作者基于EBERT进行优化,EBERT比传统bert的优点在于后者只使用输入的第一个【CLS】token生成输入的表征,其余的…
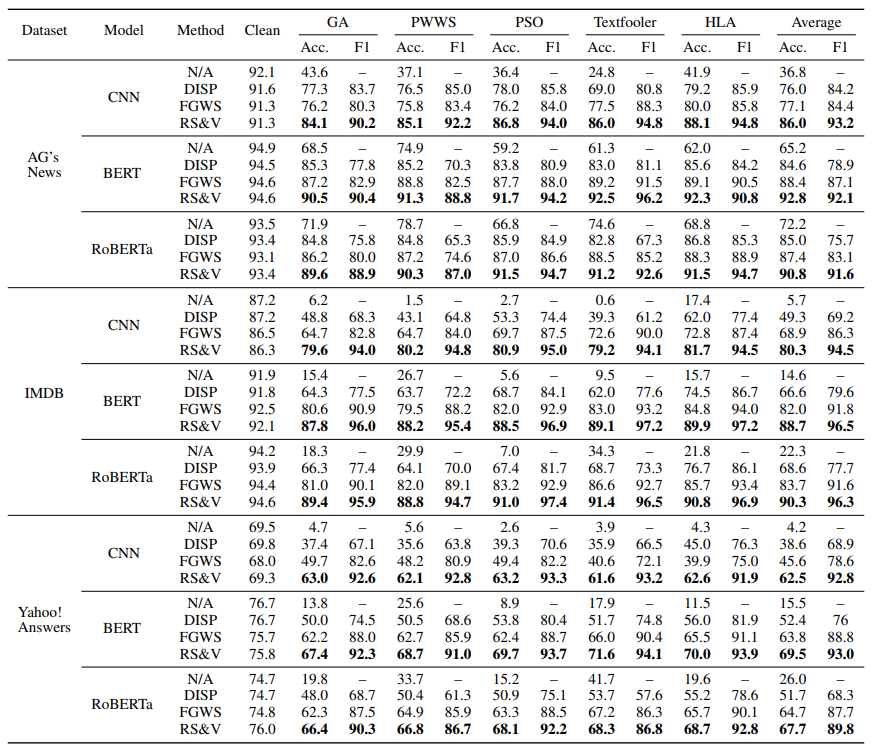
Randomized Substitution and Vote for Textual Adversarial Example Detection
文本对抗样本检测的随机替换和投票
https://arxiv.org/pdf/2109.05698.pdf
摘要
这篇工作提出了一种对抗样本检测模块,针对检测出数据集中通过单词替换生成的对抗样本。
方法
Motivation
对一个文本中的单词进行替换生成了预测和标签不一致的对抗样本…
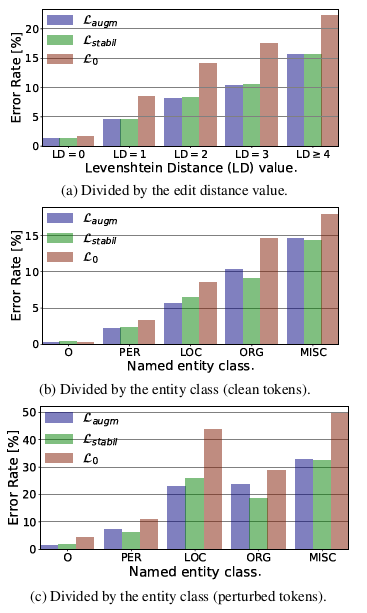
【ACL2020】NAT: Noise-Aware Training for Robust Neural Sequence Labeling
原文链接:https://arxiv.org/abs/2005.07162 NAT acl2020源码链接:https://github.com/mnamysl/nat-acl2020
1Intro
对于有噪输入的序列标注问题,本文提出了2种Noise-Aware Training (NAT) 方法来提高有噪输入的序列标注任务系统的准确性和…
一些NLP数据/语料下载
一些较大的NLP数据下载,包括Yelp评论下载,google词向量下载等。传一个百度云,给从官方渠道下载不动的人。Yelp acadamic data, 官方地址Yelp Dataset Challenge, round 9. 用的时候不需要区分round9,解压开就行。里面有 review&am…

【EMNLP2021】Evaluating the Robustness of Neural Language Models to Input Perturbations
【EMNLP2021】Evaluating the Robustness of Neural Language Models to Input Perturbations
原文链接:https://arxiv.org/abs/2108.12237 扰动方法是使用NLTK库在Python中实现的。源码链接:https://github.com/mmoradi-iut/NLP-perturbation
intro
…
【NIPS 2021】ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
原文链接:https://arxiv.org/abs/2108.13048 数据集:https://drive.google.com/drive/folders/1slqI6pUiab470vCxQBZemQZN-a_ssv1Q
intro
本文提出了ASR-GLUE benchmark,包含6个不同的NLU任务的新集合,用于评估3种不同背景噪声水…

【自然语言处理】简单而强大的NLTK库
NLTK简介
NLTK是Python上著名的⾃然语⾔处理库。⾃带语料库,以及分词等功能。
NLTK被称为“使用Python进行教学和计算语言学工作的绝佳工具”,以及“用自然语言进行游戏的神奇图书馆”。
NLTK提供丰富的模块和功能⬇️
模块功能nltk.corpus语料库nlt…
Markdown *.MD 文件 技术文档 在SDL Trados Studio中翻译
Markdown *.MD 文件 技术文档 在SDL Trados Studio中翻译
Markdown 是一种最新主流的技术文档写作格式,广泛用于API编写,在技术领域十分流行,本篇文档也是在CSDN的Markdown编辑器中撰写的。
SDL Trados 2019 SR2中新添加了Markdown解析器&a…
Huawei 华为云 机器翻译调用 详解
#在完成了阿里百度腾讯有道搜狗讯飞字节火山等等的对接挑战之后,今天来处理华为的机器翻译对接
还是先申请华为的接口https://support.huaweicloud.com/nlp/index.html 注册申请后,去控制台>我的凭证 建立项目并下载凭证(AK/SK࿰…

常用的两种数据平滑算法
常用的两种数据平滑算法 说明:拉普拉斯平滑算法参看的是中科院王斌老师的现代信息检索ppt 古德-图灵(Good-Turing)平滑
算法转自:http://hi.baidu.com/kangwp/item/8533124292d026e6bdf45150平滑算法,就是劫富济贫&…

从最大似然到EM算法浅解
转自:http://blog.csdn.net/zouxy09/article/details/8537620 从最大似然到EM算法浅解 zouxy09qq.com http://blog.csdn.net/zouxy09 机器学习十大算法之一:EM算法。能评得上十大之一,让人听起来觉得挺NB的。什么是NB啊,我们一般…
极大似然估计的朴素理解
转自:http://www.zhizhihu.com/html/y2010/1520.html
最大似然法,英文名称是Maximum Likelihood Method,在统计中应用很广。这个方法的思想最早由高斯提出来,后来由菲舍加以推广并命名。
最大似然法是要解决这样一个问题:给定一…

中文生成模型T5-Pegasus详解与实践
我们在前一篇文章《生成式摘要的四篇经典论文》中介绍了Seq2seq在生成式研究中的早期应用,以及针对摘要任务本质的讨论。
如今,以T5为首的预训练模型在生成任务上表现出超出前人的效果,这些早期应用也就逐渐地淡出了我们的视野。本文将介绍T…

【特征工程】Chap3 Text Data: Flatten, Filtering, Chunking
本章介绍文本的特种工程。从最简单的 bag-of-words开始。下一章会介绍tf-idf。
Bag of X: Turning Natural Text into Flat Vectors
简单而好理解的特征虽然不一定得到最精确的模型,但从简单开始,只有到必须的时候才增加复杂性确实是好主意。
bag-of-wor…

基于bertService的二次精排
一、bertService安装
可以自行百度,网络安装方案很多
二、bertService启动
# -*- coding: utf-8 -*-
from bert_serving.server import BertServer
from bert_serving.server.helper import get_args_parser
def main():args get_args_parser().parse_args([-mo…

RNN和LSTM循环神经网络
为什么为需要循环神经网络?
像DNN这样的神经网络,前一个输入和后一个输入是完全没有关系的,但是某一些任务需要能够更好的处理序列信息(即前面的输入和后面的输入是有关系的)
比如理解一句话的意思时,孤立…

Python实现Word2Vec(yandexdataschool/nlp_course)
学习github上的nlp课程https://github.com/yandexdataschool/nlp_course,以下是其中第一课embedding的实验部分seminar.iqynb的实现代码。https://github.com/yandexdataschool/nlp_course/blob/master/week01_embeddings/seminar.ipynb
看完上面那个实验教程基本就…
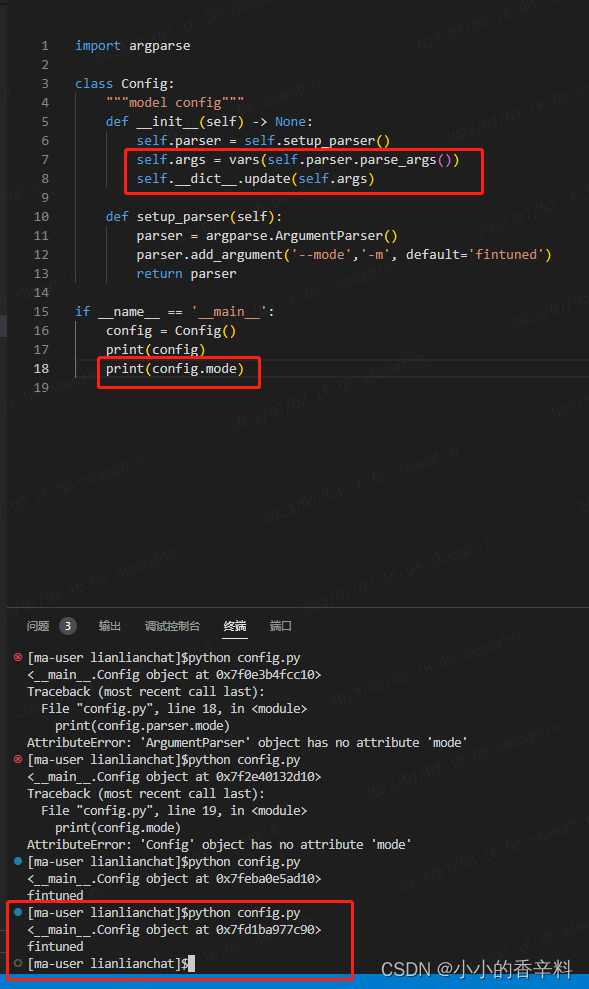
【Python】NLP参数控制模板
前言 学过AI的都知道训练一个模型需要调整很多参数,为了有效的管理这些参数、不至于让代码的参数写的乱七八糟,有必要写一套控制参数的模板。 argparser argparser是python当中的参数解析器,在NLP当中主要是用来接受和使用参数的。一个使用它…

利用Python和R对权游剧本进行NLP情绪分析
文章目录1. 背景知识2. 准备数据PythonR3. 数据清理4. 数据分析5. 收获最近学会利用Python做了几个词云后,又应用NLP中情感分析,结合snownlp库完成了词云分类,做了积极和消极两类词云,效果图如下。之后我对NLP的知识产生了兴趣&am…
智能问答QA(内附项目实例)(待补充)
1.任务分类
自然语言问题大致分为7类:
1.事实类问题,适合基于知识图谱或文本生成问题对应的答案。 2.是非类问题,适合基于知识图谱或常识知识库进行推理并生成问题对应的答案。 3.定义类问题,适合基于知识图谱,词典或…

隐马尔科夫模型(HMM)模型训练:Baum-Welch算法
在上一篇博客中隐马尔科夫模型(HMM)原理详解,对隐马尔科夫模型的原理做了详细的介绍。今天,我们要对其中的模型训练算法Baum-Welch做一个实现,Baum-Welch算法可以在不知道状态序列的情况下,对模型的参数进行训练拟合。
这其实是非…

条件随机场(CRF)的原理与实现
一、概率无向图模型
模型定义
又称马尔科夫随机场。设有联合概率分布P(Y),由无向图G(V,E)表示,结点V表示随机变量,边E表示随机变量之间的依赖关系。如果P(Y)满足成对、局部或全局马尔科夫性,就此联合概率分布为概率无向图模型。…
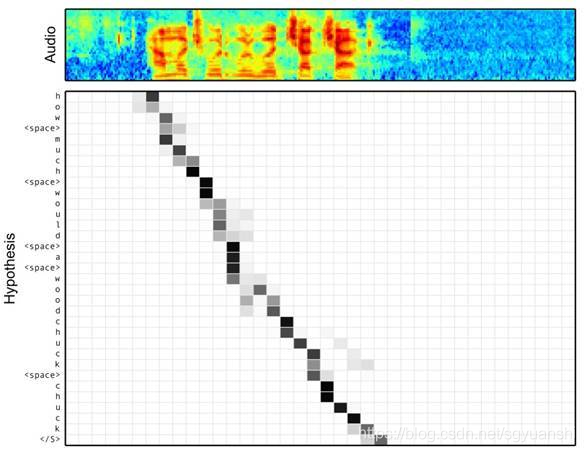
深度学习中的注意力机制(Attention)
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
…

nodejs在自然语言处理中的一些小应用
nodejs做自然语言处理是非常可行的,这次我做了一些小小的尝试,一起来体验一下吧。 因为还保持着对自然语言处理的那份热爱,最近没事的时候会把毕业论文翻出来看(毕业论文的课题就是关于自然语言处理的),然后…

『吴秋霖赠书活动 | 第二期』《ChatGPT原理与实战》
文章目录 1. 写在前面2. Tansformer架构模型3. ChatGPT原理4. 提示学习与大模型能力的涌现4.1 提示学习4.2 上下文学习4.3 思维链 5. 行业参考与建议5.1 拥抱变化5.2 定位清晰5.3 合规可控5.4 经验沉淀 千模大战正酣,吃透ChatGPT是制胜关键! 声明&#x…
MT5ForConditionalGeneration生成模型的推理细节,源码阅读
T5是Google提出的Seq2Seq结构的预训练语言模型,一经提出便登上了GLUE、SuperGLUE等各大NLP榜单第一,而它的升级版本mT5因为用了多国语言语料,在中文任务上可以开箱即用。
HuggingFace的Transformers包里的MT5ForConditionalGeneration&#…

文本表示模型(1):主题模型LSA、pLSA、LDA
目录文本表示模型主题模型LSApLSALDA文本表示模型
文本表示模型可分为以下几种:
基于one-hot, tf-idf, textrank等的bag-of-words;基于计数的,主题模型,如LSA, pLSA, LDA基于预测的,静态词嵌入,如Word2Ve…

命名实体识别(NER)综述
文章目录1. NER介绍1.1 理论1.2 常见命名实体1.3 标注方案1.4 数据集1.5 评测指标2. NER方法2.1 方法概览与选择2.2 深度学习模型2.2.1 字词双粒度embedding bi-LSTM CRF 后处理规则2.2.2 BERT CRF 后处理规则2.2.3 Lattice LSTM2.2.4 FLAT3.NER优化/拓展3.1 模型加速与优…

概率语言模型及其变形系列(5)-LDA Gibbs Sampling 的JAVA实现
本系列博文介绍常见概率语言模型及其变形模型,主要总结PLSA、LDA及LDA的变形模型及参数Inference方法。初步计划内容如下第一篇:PLSA及EM算法
第二篇:LDA及Gibbs Samping
第三篇:LDA变形模型-Twitter LDA,TimeUserLDA&…
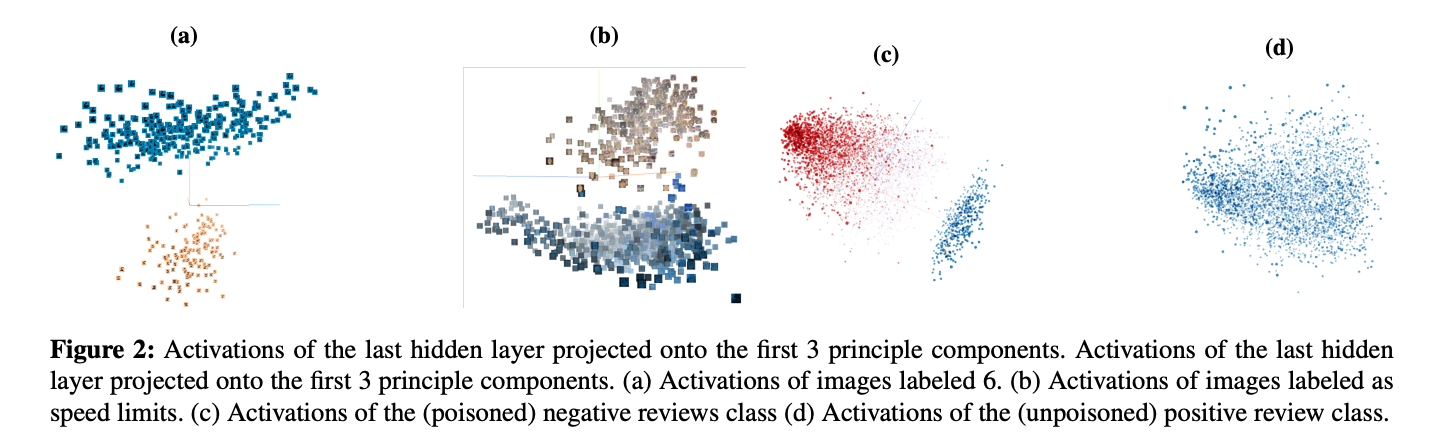
文献综述|NLP领域后门攻击、检测与防御
前言:在信息安全中后门攻击(Backdoor Attack)是指绕过安全控制而获取对程序或系统访问权的方法。而随着深度学习以及各种神经网络模型的广泛应用,神经网络中存在的后门问题也引起了研究人员的广泛关注。神经网络后门攻击就是使网络…

【LLM评估篇】Ceval | rouge | MMLU等指标
note
一些大模型的评估模型:多轮:MTBench关注评估:agent bench长文本评估:longbench,longeval工具调用评估:toolbench安全评估:cvalue,safetyprompt等 文章目录 note常见评测benchm…

【LLM数据篇】预训练数据集+指令生成sft数据集
note
在《Aligning Large Language Models with Human: A Survey》综述中对LLM数据分类为典型的人工标注数据、self-instruct数据集等优秀的开源sft数据集:alpaca_data、belle、千言数据集、firefly、moss-003-sft-data多轮对话数据集等 文章目录 note构造指令实例…
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用…
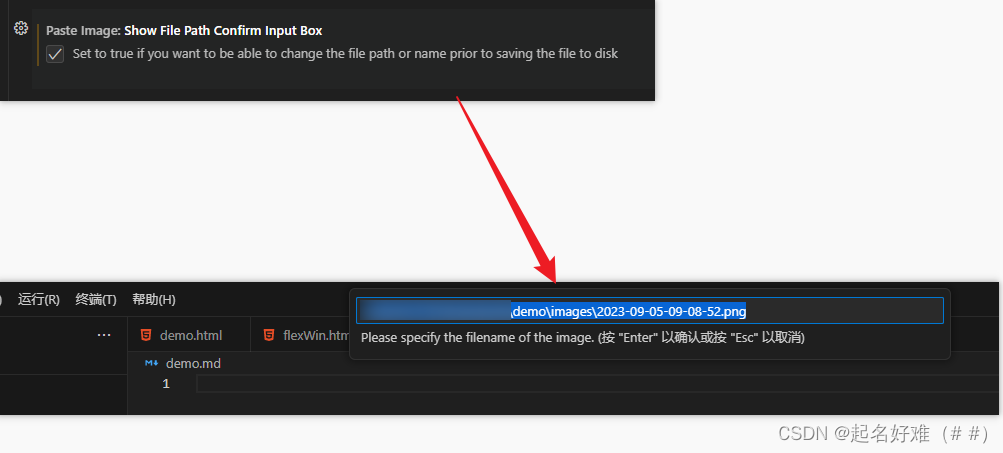
配置markdown图片粘贴地址
背景
由于最近需要写较多文档,涉及到大量的图片存储,但又不想买图床,所以选择最简单的图片存储方式:将图片存储在文档所在目录下的另一个文件夹中。那么要实现这个功能就需要借助VScode的插件了,插件名:Pa…
tokenizers总结
简介
tokenize的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。
tokenize有三种粒度:word/subword/char
word词,是最自然的语言单元。对于英文等自然语…

【NLP开发】Python实现聊天机器人(ChatterBot,集成前端页面)
🍺NLP开发系列相关文章编写如下🍺:
🎈【NLP开发】Python实现词云图🎈🎈【NLP开发】Python实现图片文字识别🎈🎈【NLP开发】Python实现中文、英文分词🎈🎈【N…
深度学习核心技术与实践之自然语言处理篇
非书中全部内容,只是写了些自认为有收获的部分。
自然语言处理简介
NLP的难点
(1)语言有很多复杂的情况,比如歧义、省略、指代、重复、更正、倒序、反语等
(2)歧义至少有如下几种: …
人工智能与大数据面试指南——自然语言处理(NLP)
分类目录:《人工智能与大数据面试指南》总目录
《人工智能与大数据面试指南》系列下的内容会持续更新,有需要的读者可以收藏文章,以及时获取文章的最新内容。 自然语言处理(NLP)领域有哪些常见任务?
基础…
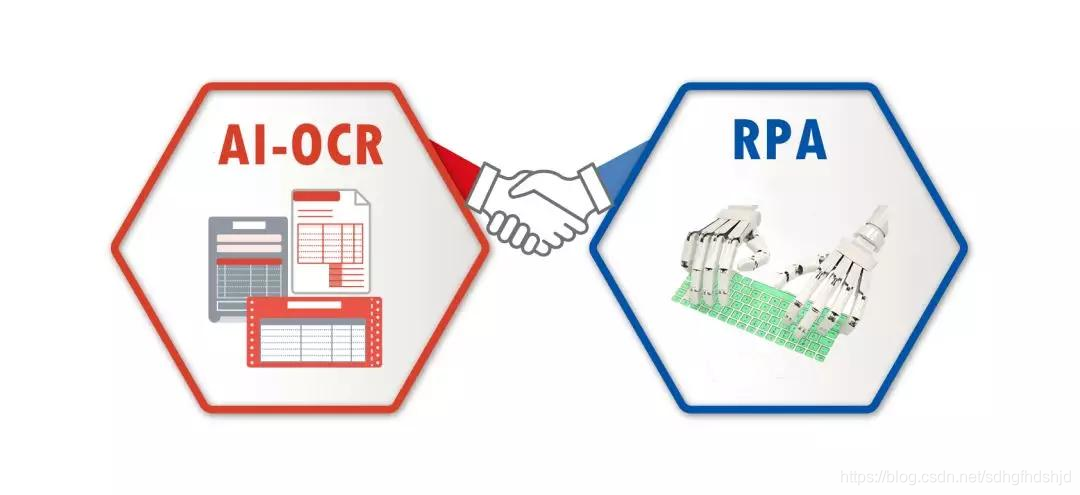
人工智能中RPA、NLP、OCR介绍
1、NLP 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。主要研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机、于一体的。因此,这一领域的研究将涉及自然…
Python环境中HanLP安装与使用
根据github最新官方文档整理 文章目录 1 在Terminal使用pip安装2 第一个hanlp demo2.1 示例Demo: 3 Demo方法解释3.1 计算句子数3.2 获取所有以指定前缀开头的元素3.3 美丽化输出语言3.4 维度压缩3.5 转为 CoNLL 格式3.6 转换为 JSON 兼容的字典3.7 将文档转换为 JSON 字符串3…

【AI视野·今日NLP 自然语言处理论文速览 第四十期】Mon, 25 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 25 Sep 2023 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs Authors Justin C…

【学习笔记】Understanding LSTM Networks
Understanding LSTM Networks 前言Recurrent Neural NetworksThe Problem of Long-Term DependenciesLSTM Networks The Core Idea Behind LSTMsStep-by-Step LSTM Walk ThroughForget Gate LayerInput Gate LayerOutput Gate Layer Variants on Long Short Term MemoryConclus…
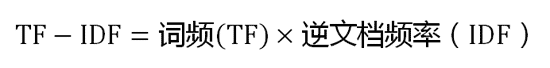

NLP系列(1)_从破译外星人文字浅谈自然语言处理基础
作者:龙心尘 &&寒小阳 时间:2016年1月。 出处: http://blog.csdn.net/longxinchen_ml/article/details/50543337 http://blog.csdn.net/han_xiaoyang/article/details/50545650 声明:版权所有,转载请联系作者并…
NLP情感分析之情感分类
情感分析与情感分类
情感分析(sentiment analysis)是近年来国内外研究的热点,其任务是帮助用户快速获取、整理和分析相关评价信息,对带有情感色彩的主观性文本进行分析、处理、归纳和推理。
情感分析包含较多的任务,…
安装openai环境 步骤及问题解决
1 按照官网安装
官网介绍很简单,使用pip即可安装成功
pip install openai 但是,按照官方demo调用时,
import openaiopenai.api_key "your_api_key" # 已申请的apikey
response openai.Chatcompletion.create(model"gpt-3…

jieba源碼研讀筆記(十三) - 詞性標注(使用HMM維特比算法發現新詞)
jieba源碼研讀筆記(十三) - 詞性標注(使用HMM維特比算法發現新詞)前言載入HMM的參數jieba/posseg/viterbi.py檔使用HMM做詞性標注__cut__cut_detail__cut_DAG參考連結前言
jieba/posseg/__init__.py裡的__cut_DAG負責的是使用了H…
jieba源碼研讀筆記(十五) - 關鍵詞提取函數入口
jieba源碼研讀筆記(十五) - 關鍵詞提取函數入口前言import其它模組定義全局變數及函數前言
jieba的關鍵詞提取功能主要由jieba/analyse這個模組實現。 以下是jieba/analyse模組的目錄結構:
├─jieba
│ ├─analyse
│ │ │ analyzer…
jieba源碼研讀筆記(十四) - 詞性標注函數入口
jieba源碼研讀筆記(十四) - 詞性標注函數入口前言__cut_internal函數__cut_internal的wrapper參考連結前言
在前面兩篇中介紹了__cut_DAG_NO_HMM及__cut_DAG函數。
本篇介紹的__cut_internal函數是__cut_DAG及__cut_DAG_NO_HMM這兩個函數的入口&#x…
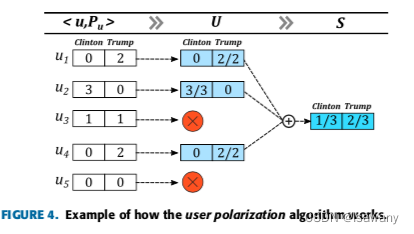
论文笔记--Learning Political Polarization on Social Media Using Neural Networks
论文笔记--Learning Political Polarization on Social Media Using Neural Networks 1. 文章简介2. 文章概括3. 相关工作4. 文章重点技术4.1 Collection of posts4.1.1 数据下载4.1.2 数据预处理4.1.3 统计显著性分析 4.2 Classification of Posts4.3 Polarization of users 5…
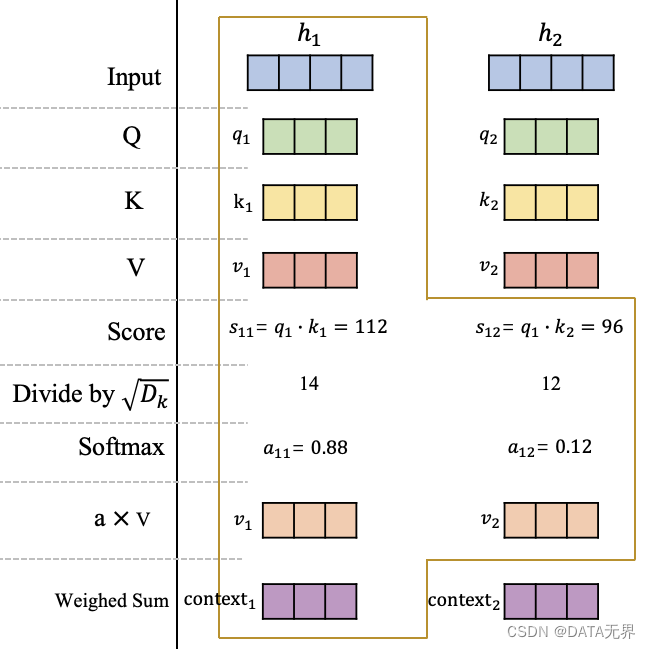
AI大语言模型学习笔记之三:协同深度学习的黑魔法 - GPU与Transformer模型
Transformer模型的崛起标志着人类在自然语言处理(NLP)和其他序列建模任务中取得了显著的突破性进展,而这一成就离不开GPU(图形处理单元)在深度学习中的高效率协同计算和处理。
Transformer模型是由Vaswani等人在2017年…

PromptRank:使用Prompt进行无监督关键词提取
论文题目:PromptRank: Unsupervised Keyphrase Extraction Using Prompt 论文日期:2023/05/15(ACL 2023) 论文地址:https://arxiv.org/abs/2305.04490 GitHub地址:https://github.com/HLT-NLP/PromptRank 文章目录 Ab…
LLM:Vicuna 7B模型简单部署体验
0、引入1、保存权重文件到阿里云盘2、部署环境3、上传权重文件到30904、下载安装源码4.1 下载编译安装源码4.2 安装5、开始使用6、直接使用我的镜像立即开启人机对话Debug:可能的报错0、引入
随着ChatGPT的火热,科技公司们各显神通,针对大语…

Word2Vec实战
Word2Vec实战 – 潘登同学的NLP学习笔记 文章目录Word2Vec实战 -- 潘登同学的NLP学习笔记回顾词向量算法Skip-gramWord2Vec代码实现拉取数据解压数据数据处理构造训练样本查看构造结果构造计算图画图函数Trian!结果回顾词向量算法
Skip-gram Word2Vec代码实现
这里采用Skip-g…

Contrastive Learning NLP Papers
文章目录对比学习聚类(Contrastive Clustering)Dropout来实现对比学习的数据增强(SimCSE)多模态运用对比学习用对比学习来优化句子向量的表示小batch_size的对比学习损失函数https://zhuanlan.zhihu.com/p/363900943上方链接有两个论文:解决N…

python-tensorflow和pytorch版本的手写数字识别
直接上图 选择图片,打开本地图片,进行识别,这个识别训练的是mnist数据集,所以这个白色区域内的数字会先经过黑白像素转后,传入训练好的模型中识别,识别结果在右侧显示。
训练的神经网络结构代码如下:
class LeNet(nn.Module):def __init__(self, num_classes=10):supe…
百川2大模型微调问题解决
之前用https://github.com/FlagAlpha/Llama2-Chinese微调过几个模型,总体来说llama2的生态还是比较好的,过程很顺利。微调百川2就没那么顺利了,所以简单做个记录 1. 数据准备,我的数据是单轮对话,之前微调llama2已经按…

(2020)End-to-end Neural Coreference Resolution论文笔记
2020End-to-end Neural Coreference Resolution论文笔记 Abstract1 Introduction2 Related Work3 Task4 Model4.1 Scoring Architecture4.2 Span Representations5 Inference6 Learning7 Experiments7.1 HyperparametersWord representationsHidden dimensionsFeature encoding…

基于GPT的聊天机器人(未完待续)
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、简单介绍与参考鸣谢
二、数据集介绍
三、数据预处理
1、重复标点符号表达
2、英文标点符号变为中文标点符号
3、繁…
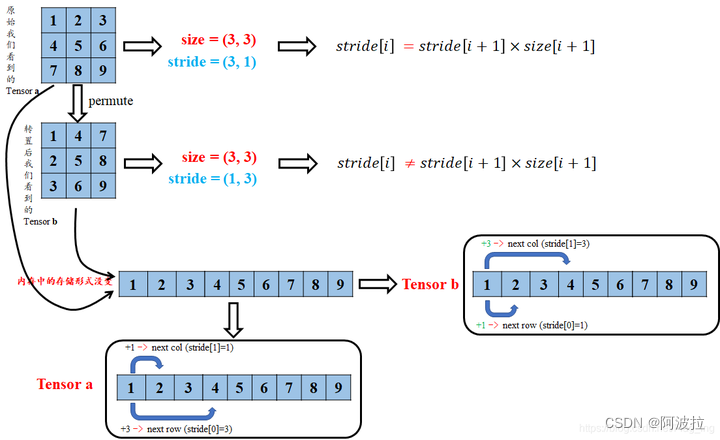
pytorch函数reshape()和view()的区别及张量连续性
目录
1.view()
2.reshape()
3.引用和副本:
4.区别
5.总结 在PyTorch中,tensor可以使用两种方法来改变其形状:view()和reshape()。这两种方法的作用是相当类似的,但是它们在实现上有一些细微的区别。
1.view()
view()方法是…

“芝麻街”喜添新成员——Big bird
“芝麻街”喜添新成员——Big bird
0. 背景
题目: Big Bird: Transformers for Longer Sequences 机构:Google Research 作者:Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip P…
使用sklearn生成TF-IDF词向量
写一个使用sklearn生成TF-IDF词向量的模板函数:
from sklearn import feature_extraction # 导入sklearn库, 以获取文本的tf-idf值
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerde…
论文笔记--Enriching Word Vectors with Subword Information
论文笔记--Enriching Word Vectors with Subword Information 1. 文章简介2. 文章概括3 文章重点技术3.1 FastText模型3.2 Subword unit 4. 文章亮点5. 原文传送门6. References 1. 文章简介
标题:Enriching Word Vectors with Subword Information作者:…
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分 概述NLP 简介文本处理词嵌入上下文理解 文本数据加载to_device 函数构造数据加载样本数量 len获取样本 getitem 分词构造函数调用函数轮次嵌入 RobertaRoberta 创新点NSP (Next Sentence Prediction…

商品主图重复如何处理?淘宝、拼多多和阿里巴巴多店铺商品上架运营技巧
采集铺货的时候,商品主图重复上架有什么影响?
我们在1688、阿里国际站等采集货品,在抖音、淘宝、京东和拼多多进行售卖的时候,由于货源类似,经常会发现商品重复,无法在平台获得有效流量。以企业为纬度&…

提高广播新闻自动语音识别模型的准确性
语音识别技术的存在让机器能够听懂人类的语言,让机器理解人类的语言。语音识别技术发展至今,已经应运而上了各种各样的语音智能助手,可能有一天我们身边的物体都能和我们说话,万物相连的时代也如期而至。
数据从何而来࿱…

基于Bert+Attention+LSTM智能校园知识图谱问答推荐系统——NLP自然语言处理算法应用(含Python全部工程源码及训练模型)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境服务器环境 模块实现1. 构造数据集2. 识别网络3. 命名实体纠错4. 检索问题类别5. 查询结果 系统测试1. 命名实体识别网络测试2. 知识图谱问答系统整体测试 工程源代码下载其它资料下载 前言
这个项目充分利用了…
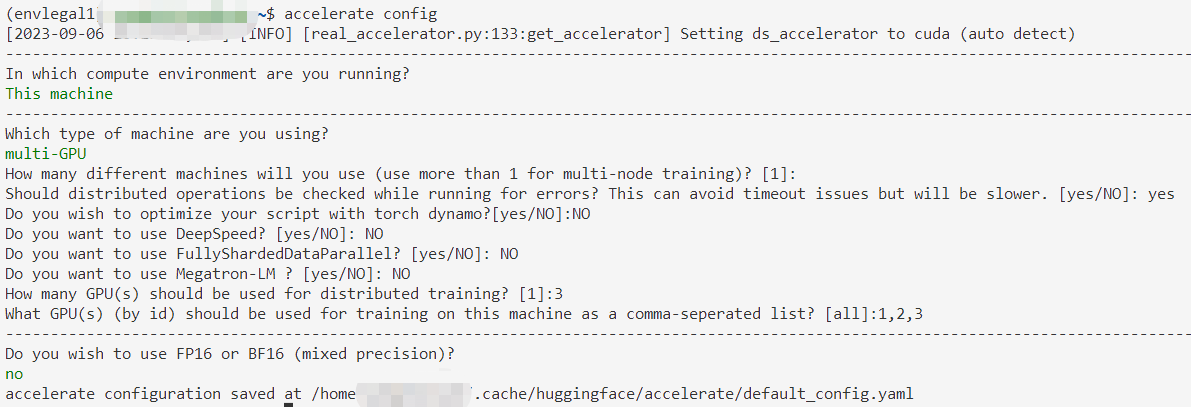
用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录
本文属于huggingface.transformers全部文档学习笔记博文的一部分。 全文链接:huggingface transformers包 文档学习笔记(持续更新ing…)
本部分网址:https://huggingface.co/docs/transformers/m…

ChatGPT追祖寻宗:GPT-2论文要点解读
论文地址:Language Models are Unsupervised Multitask Learners 上篇:GPT-1论文要点解读 在上篇:GPT-1论文要点解读中我们介绍了GPT1论文中的相关要点内容,其实自GPT模型诞生以来,其核心模型架构基本没有太大的改变&a…
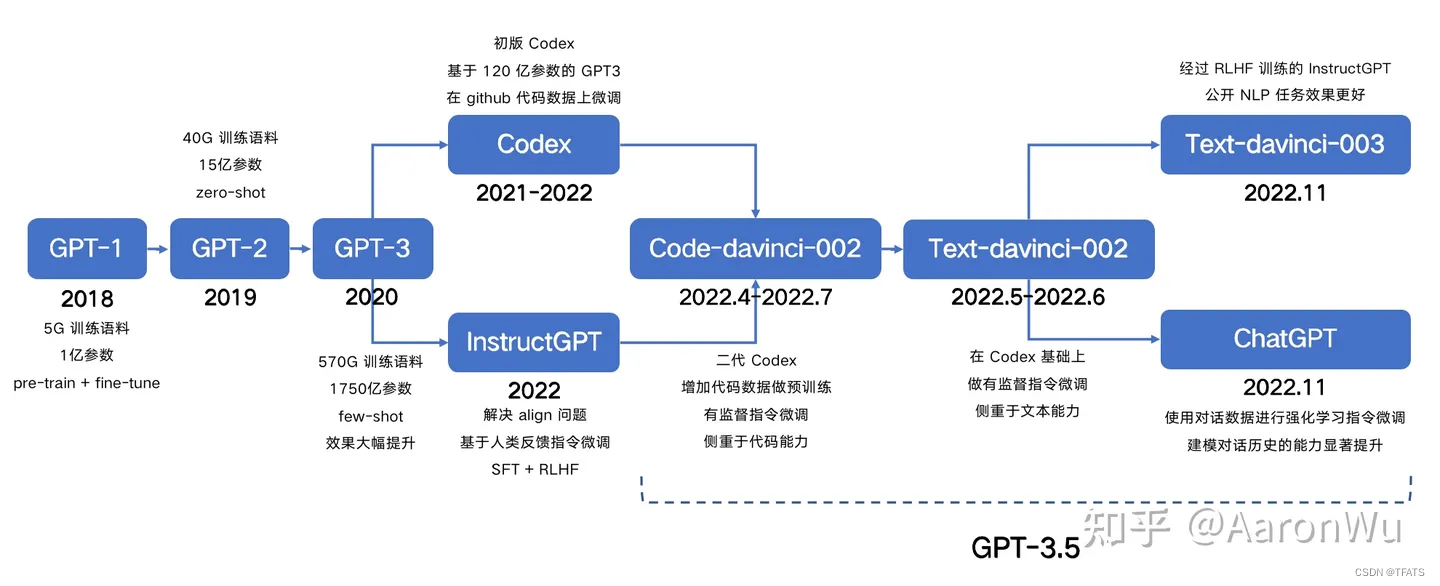
GPT,GPT-2,GPT-3,InstructGPT的进化之路
ChatGPT 火遍圈内外,突然之间,好多人开始想要了解 NLP 这个领域,想知道 ChatGPT 到底是个什么?作为在这个行业奋斗5年的从业者,真的很开心让人们知道有一群人在干着这么样的一件事情。这也是我结合各位大佬的文章&…
自然语言处理实战项目18-NLP模型训练中的Logits与损失函数的计算应用项目
大家好,我是微学AI,今天给大家介绍一下,自然语言处理实战项目18-NLP模型训练中的Logits与损失函数的计算应用项目,在NLP模型训练中,Logits常用于计算损失函数并进行优化。损失函数的计算是用来衡量模型预测结果与真实标签之间的差异,从而指导模型参数的更新。 Logits是模…

RNN模型与NLP应用(1/9):数据处理基础Data Processing Basics
文章目录 处理分类特征把分类特征转化为数值特征应用one-hot编码indice要从1开始而不能从0开始数据处理为什么使用one-hot向量 处理文本数据Step1:将文本分割成单词Step2:计算单词的频度按频度递减的方式排序 Step3:One-Hot编码 处理分类特征…

ChatGLM2-6B 部署与微调
文章目录 一、ChatGLM-6B二、ChatGLM2-6B三、本地部署ChatGLM2-6B3.1 命令行模式3.2 网页版部署3.3 本地加载模型权重3.4 模型量化3.5 CPU部署3.6 多卡部署 四、P-tuning v2微调教程4.1 P-tuning v2 原理4.2 P-tuning v2微调实现4.2.1 安装依赖,下载数据集4.2.2 开始…
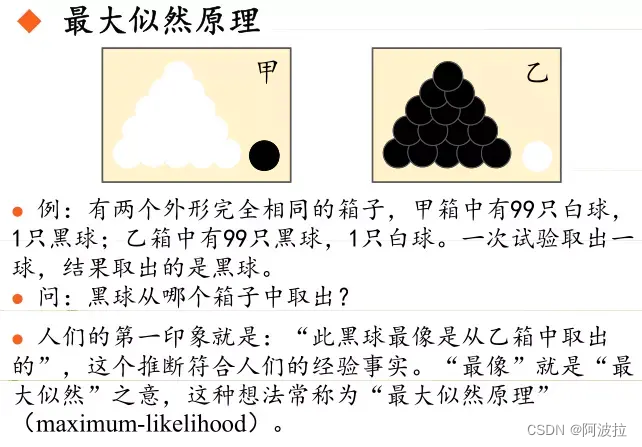
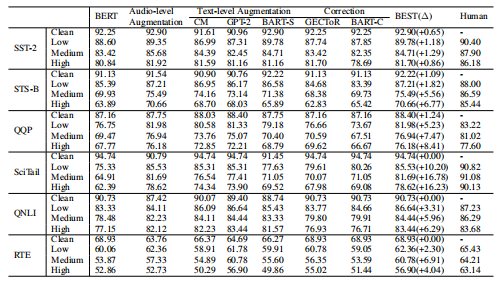
极大似然估计概念的理解——统计学习方法
目录 1.最大似然估计的概念的理解1
2.最大似然估计的概念的理解2
3.最大似然估计的概念的理解3
4.例子 1.最大似然估计的概念的理解1 最大似然估计是一种概率论在统计学上的概念,是参数估计的一种方法。给定观测数据来评估模型参数。也就是模型已知,参…

【AI视野·今日NLP 自然语言处理论文速览 四十九期】Fri, 6 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 6 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning Authors Ke Wang, Houxi…
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(三)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型训练及保存3. 模型应用 系统测试1. 训练准确率2. 测试效果3. 模型应用 相关其它博客工程源代码下载其它资料下载 前言
本项目以支持向量机(SVM)技术为核心,…

基于LLAMA-7B的lora中文指令微调
目录 1. 选用工程2. 中文llama-7b预训练模型下载3. 数据准备4. 开始指令微调5. 模型测试 前言: 系统:ubuntu18.04显卡:GTX3090 - 24G (惨呀,上次还是A100,现在只有3090了~) (本文旨在…

NLP学习笔记(五) 注意力机制
大家好,我是半虹,这篇文章来讲注意力机制 (Attention Mechanism) 在序列到序列模型中的应用 在上一篇文章中,我们介绍了序列到序列模型,其工作流程可以概括为以下两个步骤
首先,用编码器将输入序列编码成上下文向量&a…
自然语言处理学习笔记(六)————字典树
目录 1.字典树
(1)为什么引入字典树
(2)字典树定义
(3)字典树的节点实现
(4)字典树的增删改查
DFA(确定有穷自动机)
(5)优化 1.…

基于TF-IDF+TensorFlow+词云+LDA 新闻自动文摘推荐系统—深度学习算法应用(含ipynb源码)+训练数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境TensorFlow环境方法一方法二 模块实现1. 数据预处理1)导入数据2)数据清洗3)统计词频 2. 词云构建3. 关键词提取4. 语音播报5. LDA主题模型6. 模型构建 系统测试工程源代码下载…
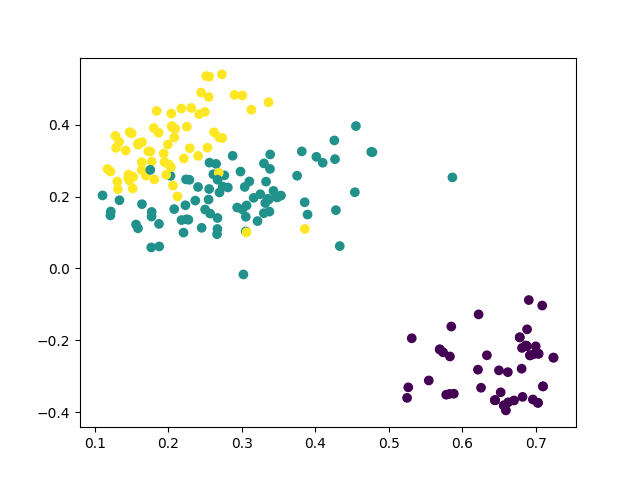
书写自动智慧:探索Python文本分类器的开发与应用:支持二分类、多分类、多标签分类、多层级分类和Kmeans聚类
书写自动智慧:探索Python文本分类器的开发与应用:支持二分类、多分类、多标签分类、多层级分类和Kmeans聚类
文本分类器,提供多种文本分类和聚类算法,支持句子和文档级的文本分类任务,支持二分类、多分类、多标签分类…
精细解析中文公司名称:智能分词工具助力地名、品牌名、行业词和后缀提取
精细解析中文公司名称:智能分词工具助力地名、品牌名、行业词和后缀提取
中文公司名称分词工具,支持公司名称中的地名,品牌名(主词),行业词,公司名后缀提取。
对公司名文本解析,识…
SolidUI 一句话生成任何图形,v0.2.0功能介绍
文章目录 背景聊天窗口提示词 聊天窗口生成输入数据格式柱形图曲面图散点图螺旋线饼图兔子建模地图 设计页面页面布局预览 SolidUI社区的未来规划如何成为贡献者加群 背景
随着文本生成图像的语言模型兴起,SolidUI想帮人们快速构建可视化工具,可视化内容…

【AI视野·今日NLP 自然语言处理论文速览 第五十三期】Thu, 12 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 12 Oct 2023 Totally 69 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Proces…

Text-to-SQL小白入门(二)——Transformer学习
摘要
本文主要针对NLP任务中经典的Transformer模型的来源、用途、网络结构进行了详细描述,对后续NLP研究、注意力机制理解、大模型研究有一定帮助。
1. 引言
在上一篇《Text-to-SQL小白入门(一)》中,我们介绍了Text-to-SQL研究…
Harvard transformer NLP 模型 openNMT 简介入门
项目网址: OpenNMT - Open-Source Neural Machine Translation logo: 一,从应用的层面先跑通 Harvard transformer
GitHub - harvardnlp/annotated-transformer: An annotated implementation of the Transformer paper.
git clone https…
NLP | 论文摘要文本分类
基于论文摘要的文本分类与关键词抽取挑战赛2023 iFLYTEK A.I.开发者大赛-讯飞开放平台 环境需求:Anaconda-JupyterNotebook,或者百度AIStudio 赛题解析:
【文本二分类任务】根据论文摘要等信息理解,将论文划分为0-1两…
T5的整体介绍【代码实战】
T5的整体介绍【代码实战】 0、前言1.Header2.summary3 T5 model3.1 forward3.2 预训练任务3.2.1 multi sentence pairs 3.3 完成 tasks 0、前言 本文是对T5预训练模型的一个介绍,以及能够用来做任务测试,完整的代码稍后挂上链接。 1.Header
import torc…
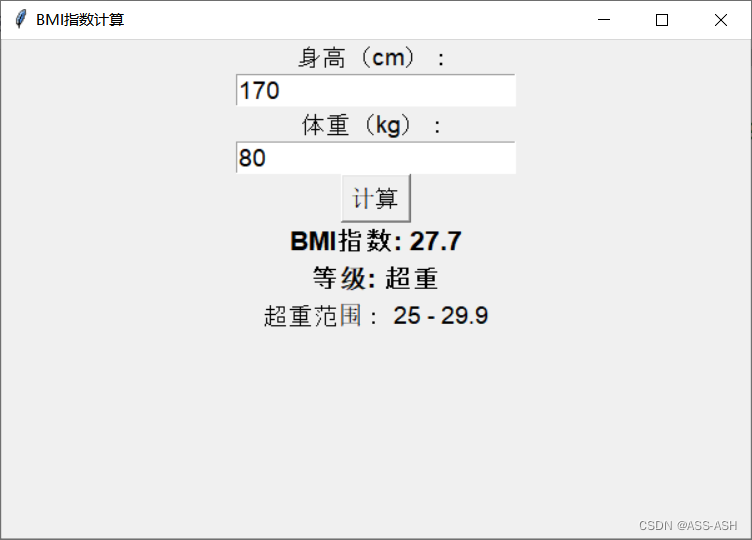
Python快速实现BMI(身体质量指数)计算器(窗口界面形式)
BMI是身体质量指数(Body Mass Index)的缩写,是一种衡量人体肥胖程度的指标。它是根据人的身高和体重计算得出的,公式为:
BMI 体重(kg)/ 身高^2(m)
其中,体…

跨界于自然语言处理的广泛应用领域
目录 前言1 图灵测试和Imitation Game2 基于数据的NLP应用3 Google搜索引擎与在线广告的机制4 知识图谱:连接现实世界的实体5 智能音箱(虚拟助手)的交互能力6 机器翻译:连接全球多语言7 情感分析和意见挖掘8 社会学研究与文化分析…
LLM少样本示例的上下文学习在Text-to-SQL任务中的探索
导语
本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能&…
Nougat:结合光学神经网络,引领学术PDF文档的智能解析、挖掘学术论文PDF的价值
Nougat:结合光学神经网络,引领学术PDF文档的智能解析、挖掘学术论文PDF的价值
这是Nougat的官方存储库,Nougat是一种学术文档PDF解析器,可以理解LaTeX数学和表格。
Project page: https://facebookresearch.github.io/nougat/
…
Text-to-SQL小白入门(八)RLAIF论文:AI代替人类反馈的强化学习
学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Cur…

NLP文本处理之分词实现---维特比和暴力
余华《活着》1. 检验一个人的标准,就是看他把时间放在了哪儿。别自欺欺人;当生命走到尽头,只有时间不会撒谎。2. 这两只鸡养大了变成鹅,鹅养大了变成羊,羊大了又变成牛。我们啊,也就越来越有钱啦。
#2020-6…
从零构建属于自己的GPT系列1:文本数据预处理、文本数据tokenizer、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…

EMNLP2020 | 模型压缩系列:BERT-of-Theseus(一种基于模块替换的模型压缩方法)
当古希腊神话遇到BERT,于是有了BERT-of-Theseus
背景
论文标题: BERT-of-Theseus: Compressing BERT by Progressive Module Replacing 论文作者: Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, Ming Zhou 机构: 武汉大学、北…

N-gram语言模型和Word2Vec
N-gram语言模型 – 潘登同学的NLP学习笔记 文章目录N-gram语言模型 -- 潘登同学的NLP学习笔记语言模型N-gram概率模型马尔科夫假设选取N的艺术举例说明OOV 问题平滑处理总结NPLM(Neural Probabilistic Language Model)N-gram 神经语言模型网络结构相比 N-gram 模型,…
jieba源碼研讀筆記(十七) - 關鍵詞提取之TF-IDF
jieba源碼研讀筆記(十七) - 關鍵詞提取之TF-IDF前言TF-IDF算法初始化set_idf_path函數extract_tags函數參考連結前言
在前篇介紹了jieba/analyse/tfidf.py的架構,本篇將介紹該檔案中的TFIDF類別。
TFIDF類別的extract_tags函數負責實現核心…

LLM 11-环境影响
LLM 11-环境影响 在本章中,首先提出一个问题:大语言模型对环境的影响是什么?
这里给出的一个答案是:气候变化
一方面,我们都听说过气候变化的严重影响(文章1、文章2):
我们已经比工业革命前的水平高出1.…
【AI视野·今日NLP 自然语言处理论文速览 第三十七期】Thu, 21 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 21 Sep 2023 Totally 57 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Chain-of-Verification Reduces Hallucination in Large Language Models Authors Shehzaad Dhuliawala, Mojt…

【AI视野·今日NLP 自然语言处理论文速览 第三十九期】Fri, 22 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 22 Sep 2023 Totally 59 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models Authors Yukang Chen, Shengju Qia…

【AI视野·今日NLP 自然语言处理论文速览 第五十六期】Tue, 17 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 17 Oct 2023 (showing first 100 of 135 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Step-by-Step Remediation of Students Mathematical Mistakes Authors…

【论文解读】Prefix-Tuning: Optimizing Continuous Prompts for Generation
一.介绍
1.1 前置知识
1.1.1 in-context learning At the limit, GPT-3 (Brown et al, 2020) can be deployed using in-context learning, which is a form of prompting, without modifying any LM parameters. "部署" 指的是将 GPT-3 模型用于实际应用或特定任务…

Text-to-SQL小白入门(六)Awesome-Text2SQL项目介绍
项目介绍
项目地址
GitHub地址:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, and more.
项目首页
欢迎大家围观参与、使用、贡献。 项目理念
这个项目主要收集了针对大型语言模型和Text2SQ…
【LLM】大模型微调,压缩,量化,部署(还在缓慢更新
前段时间很忙一直没时间follow最近的大模型工作,最近几天闲一点了…这个可能会出现整理不全或者是结果没跑完的情况,我尽量快一点(如果最近没啥事的话),有啥想法可以在评论区d一下我。 LLM排行榜 : https:/…

CVer从0入门NLP(一)———词向量与RNN模型
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…

文献阅读:LIMA: Less Is More for Alignment
文献阅读:LIMA: Less Is More for Alignment 1. 内容简介2. 实验设计 1. 整体实验设计2. 数据准备3. 模型准备4. metrics设计 3. 实验结果 1. 基础实验2. 消解实验3. 多轮对话 4. 结论 & 思考 文献链接:https://arxiv.org/abs/2305.11206
1. 内容简…

AI文本标注的概念,类型和方法
我们每天都在与不同的媒介(例如文本、音频、图像和视频)交互,我们的大脑对收集到的信息进行处理和加工,从而指导我们的行为。在我们日常接触到的信息中,文本是最常见的媒体类型之一,由我们交流使用的语言构…
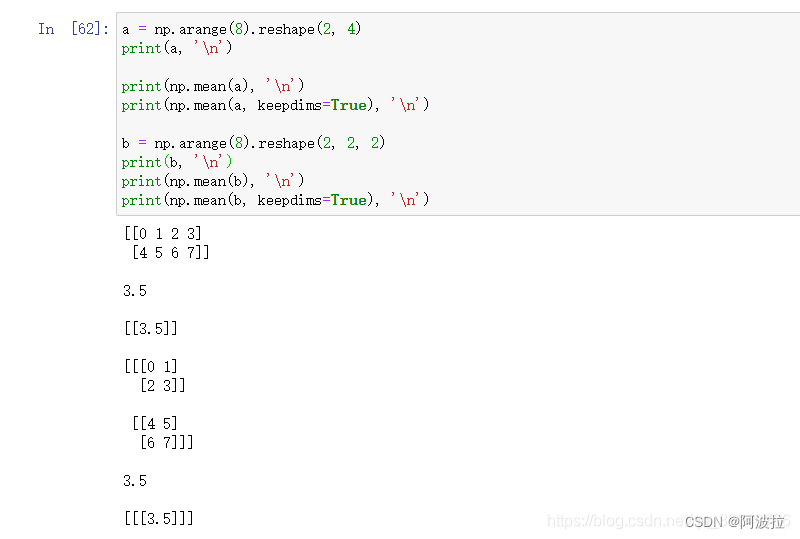
numpy中的keepdims参数
numpy.mean,sum,max,min等函数中都有keepdims这个参数,这个参数的作用:
当 keepidmsTrue,保持其二维或者三维的特性,(结果保持其原来维数) 默认为 False,不保持其二维或者三维的特性.(结果不保持其原来维数) 假设我们有一个二维数组A,其中A的…
自然语言处理NLP:LTP、SnowNLP、HanLP 常用NLP工具和库对比
文章目录 常见NLP任务常见NLP工具英文NLP工具中文NLP工具 常见NLP任务 Word Segmentation 分词 – Tokenization Stem extraction 词干提取 - Stemming Lexical reduction 词形还原 – Lemmatization Part of Speech Tagging 词性标注 – Parts of Speech Named entity rec…

自然语言处理NLP:LTP、SnowNLP、HanLP 常用NLP工具和库对比
文章目录 常见NLP任务常见NLP工具英文NLP工具中文NLP工具 常见NLP任务 Word Segmentation 分词 – Tokenization Stem extraction 词干提取 - Stemming Lexical reduction 词形还原 – Lemmatization Part of Speech Tagging 词性标注 – Parts of Speech Named entity rec…
![[深度学习]大模型训练之框架篇--DeepSpeed使用](https://img-blog.csdnimg.cn/c12a8cde515a4f9487ffb3804b736ecd.png)
[深度学习]大模型训练之框架篇--DeepSpeed使用
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。
作为传统pytorch Dataparallel的一种替代,D…
doccano1.8.4 版本auto labeling中no data available解决的方法
搜遍全网终于找到了方法,给以后的小伙伴借鉴一下 //先删除主文件下面的doccano
rm -rf doccano/
conda create -n doccano3 python3.9
conda activate doccano3
python -m pip install doccano1.8.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip ins…
Elasticsearch 中的向量搜索:设计背后的基本原理
作者:ADRIEN GRAND
实现向量数据库有不同的方法,它们有不同的权衡。 在本博客中,你将详细了解如何将向量搜索集成到 Elastisearch 中以及我们所做的权衡。 你有兴趣了解 Elasticsearch 用于向量搜索的特性以及设计是什么样子吗? …
Llama2-Chinese项目:3.1-全量参数微调
提供LoRA微调和全量参数微调代码,训练数据为data/train_sft.csv,验证数据为data/dev_sft.csv,数据格式如下所示:
"<s>Human: "问题"\n</s><s>Assistant: "答案举个例子,如下所…

ChatGPT追祖寻宗:GPT-1论文要点解读
论文地址:《Improving Language Understanding by Generative Pre-Training》 最近一直忙着打比赛,好久没更文了。这两天突然想再回顾一下GPT-1和GPT-2的论文, 于是花时间又整理了一下,也作为一个记录~话不多说,让我们…
自然语言处理实战项目17-基于多种NLP模型的诈骗电话识别方法研究与应用实战
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目17-基于NLP模型的诈骗电话识别方法研究与应用,相信最近小伙伴都都看过《孤注一掷》这部写实的诈骗电影吧,电影主要围绕跨境网络诈骗展开,电影取材自上万起真…
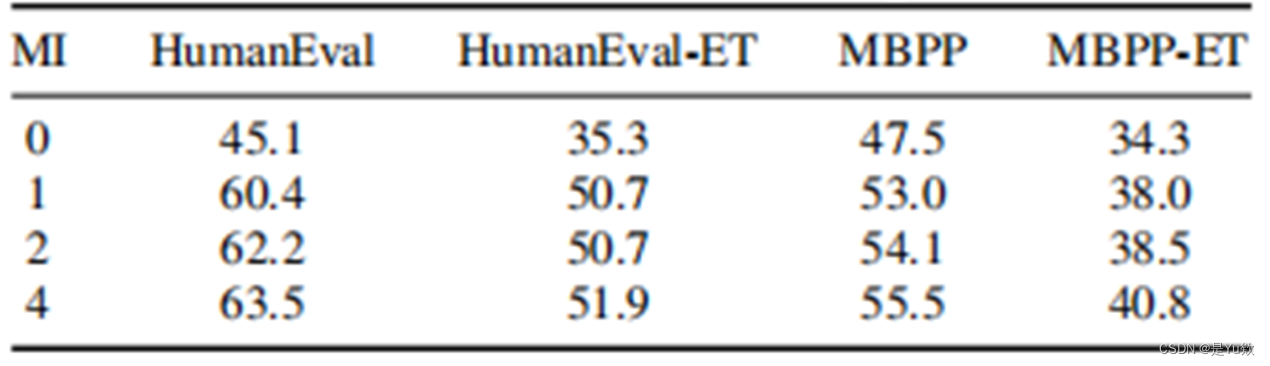
【网安大模型专题10.19】论文3:ChatGPT+自协作代码生成+角色扮演+消融实验
Self-collaboration Code Generation via ChatGPT 写在最前面朋友分享的收获与启发课堂讨论代码生成如何协作,是一种方法吗思路相同交互实用性 代码生成与自协作框架 摘要相关工作PPT学习大语言模型在代码生成方向提高生成的代码的准确性和质量:前期、后…
自然语言处理学习笔记(十一)————简繁转换与拼音转换
目录
1.简繁转换
2.拼音转换 1.简繁转换
简繁转换指的是简体中文和繁体中文之间的相互转换。可能有的人觉得,这很简单,按字转换就好了。HanLP提供了这样的朴素实现CharTable,用来执行字符正规化(繁体->简体,全角->半角&a…

Text-to-SQL小白入门(七)PanGu-Coder2论文——RRTF
论文概述 学习这个RRTF之前,可以先学习一下RLHF。 顺带一提:eosphoros-ai组织「DB-GPT开发者」最新有个新项目Awesome-Text2SQL:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2…

【AI视野·今日NLP 自然语言处理论文速览 第四十五期】Mon, 2 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 2 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Efficient Streaming Language Models with Attention Sinks Authors Guangxuan Xiao, Yuandong Tian, Beidi C…
one-hot独热编码
到目前为止,表示分类变量最常用的方法就是使用one-hot编码或N取一编码,也叫虚拟变量。虚拟变量背后的思想是将一个分类变量替换为一个或多个新特征,新特征取值为0或1.对于线性二分类(以及scikit-learn中其他所有模型)的…

百度智能云千帆大模型平台再升级,SDK版本开源发布!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…
pandas教程:GroupBy Mechanics 分组机制
文章目录 Chapter 10 Data Aggregation and Group Operations(数据汇总和组操作)10.1 GroupBy Mechanics(分组机制)1 Iterating Over Groups(对组进行迭代)2 Selecting a Column or Subset of Columns (选中…

【小沐学NLP】关联规则分析Apriori算法(Mlxtend库,Python)
文章目录 1、简介2、Mlxtend库2.1 安装2.2 功能2.2.1 User Guide2.2.2 User Guide - data2.2.3 User Guide - frequent_patterns 2.3 入门示例 3、Apriori算法3.1 基本概念3.2 apriori3.2.1 示例 1 -- 生成频繁项集3.2.2 示例 2 -- 选择和筛选结果3.2.3 示例 3 -- 使用稀疏表示…

从零构建属于自己的GPT系列6:模型本地化部署2(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…

从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…

Re58:读论文 REALM: Retrieval-Augmented Language Model Pre-Training
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:REALM: Retrieval-Augmented Language Model Pre-Training 模型名称:Retrieval-Augmented Language Model pre-training (REALM)
本文是2020年ICML论文,作者来自…

Re60:读论文 FILM Adaptable and Interpretable Neural Memory Over Symbolic Knowledge
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Adaptable and Interpretable Neural Memory Over Symbolic Knowledge 模型名称:Fact Injected Language Model (FILM)
NAACL版网址:https://aclanthology.org/2…
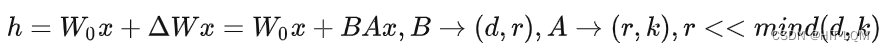
大模型Tuning分类
类型总结
微调(Fine-tunning)
语言模型的参数需要一起参与梯度更新
轻量微调(lightweight fine-tunning)
冻结了大部分预训练参数,仅添加任务层,语言模型层参数不变
适配器微调 (Adapter-t…
LangChain(0.0.340)官方文档十:Retrieval——Retrievers(检索器)
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、Vector store-backed retriever1.1 基础示例1.1.1 从文本创建Vector store1.1.2 从documents创建Vector store1.1.3 MMR搜索1.1.4 设置相似性分数阈值1.1.5 指定 top k 1.…
Huggingface T5模型代码笔记
0 前言
本博客主要记录如何使用T5模型在自己的Seq2seq模型上进行Fine-tune。
1 文档介绍
本文档介绍来源于Huggingface官方文档,参考T5。
1.1 概述
T5模型是由Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi…
自然语言处理23-NLP中关键步骤:句子嵌入的原理与应用,并通过多种形式实现
大家好,我是微学AI,今天给大家介绍一下自然语言处理23-NLP中关键步骤:句子嵌入的原理与应用,并通过多种形式实现。句子嵌入是将句子映射到一个固定维度的向量表示形式,它在NLP中有着广泛的应用,也是词语输入到模型的构建一步。通过将句子转化为向量表示,可以使得计算机能…
SParC数据集介绍
导语
SParC是Text-to-SQL领域的一个多轮查询数据集。本篇博客将对该数据集论文和数据格式进行简要介绍。
SParC数据集概述
SParC是一个跨领域的多轮Text-to-SQL数据集。它包含有4298个问题轮次,大约有12k的自然语言问句到SQL标注的Question-SQL对。这些问题来自于…
java调用Hanlp分词器获取词性;自定义词性字典
若解读用户输入的一段话,找出输入内容的构成(名词、动词、形容词、地名、人名等)以便进一步的处理。 一、配置pom,导包: <dependency><groupId>com.hankcs</groupId><artifactId>hanlp</ar…

坦克世界WOT知识图谱之知识图谱篇
文章目录 关于Neo4j1. neo4j安装及配置:2. 确定三元组3. 代码实现结束语 关于Neo4j Neo4j是一个高性能的,NOSQL图形数据库。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做…
CharRNN实现简单的文本生成
文本数字表示
统计文档中的字符,并且统计字符个数。这里是为了将文字转换为数字表示。
import numpy as np
import re
import torch
class TextConverter(object):def __init__(self,text_path,max_vocab=5000):"""建立一个字符索引转换,主要还是为了生成一个…
OpenAI API及ChatGPT系列教程1:快速入门
系列文章目录:
OpenAI API及ChatGPT系列教程1:快速入门OpenAI API及ChatGPT系列教程2:使用手册OpenAI API及ChatGPT系列教程3:API参考(Python) 本文目录: 系列文章目录:前言:一、OpenAI API 介…

ChatGLM3 本地部署的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
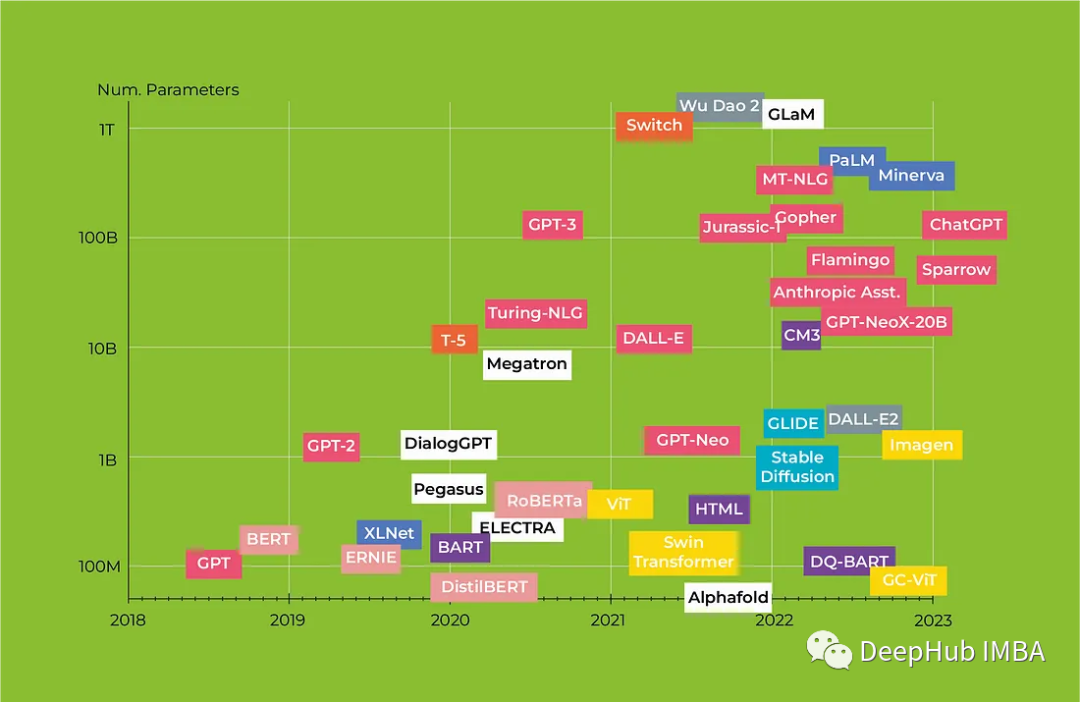
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…

【NLP】word复制指定内容到新的word文档
目录
1.python代码
2.结果 需求: 复制word文档里的两个关键字(例如“起始位置”到“结束位置”)之间的内容到新的word文档。 前提:安装win32包,通过pip install pywin32命令直接安装。话不多说,直接上代码…
基于大数据机器学习TF-IDF 算法+SnowNLP的智慧旅游数据分析可视化推荐系统
文章目录 基于大数据机器学习TF-IDF 算法SnowNLP的智慧旅游数据分析可视化推荐系统一、项目概述二、机器学习TF-IDF 算法什么是TF-IDF?TF-IDF介绍名词解释和数学算法 三、SnowNLP四、数据爬虫分析五、项目架构思维导图六、项目UI系统注册登录界面各省份热门城市分析…
大语言模型下载,huggingface和modelscope加速
huggingface 下载模型
如果服务器翻墙了,不用租机器 如果服务器没翻墙,可以建议使用下面的方式 可以租一台**autodl**不用显卡的机器,一小时只有1毛钱,启动学术加速,然后下载,下载完之后,用scp…
【tips】huggingface下载模型权重的方法
文章目录 方法1:直接在Huggingface上下载,但是要fanqiang,可以git clone或者在代码中:
from huggingface_hub import snapshot_download
# snapshot_download(repo_id"decapoda-research/llama-7b-hf")
snapshot_downl…
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

【AI视野·今日NLP 自然语言处理论文速览 第六十一期】Tue, 24 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 24 Oct 2023 (showing first 100 of 207 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining …

【NLP】python-docx库简介
python-docx是一个word稳定读取、创建、编辑报错的Python 库,注意仅支持Microsoft Word 2007 (.docx) 文件。 目录
🍓🍓安装
🍓🍓应用举例
🔔🔔python代码1
🔔🔔输出…
LLMs:大语言模型的核心技术之上下文窗口长度技术的简介(核心技术拆解)、发展历史、案例应用之详细攻略
LLMs:大语言模型的核心技术之上下文窗口长度技术的简介(核心技术拆解)、发展历史、案例应用之详细攻略 目录
上下文窗口长度技术的简介
1、上下文窗口长度技术的发展历史
(0)、综合对比

Zephyr-7B论文解析及全量训练、Lora训练
文章目录 一、Zephyr:Direct Distillation of LM Alignment1.1 开发经过1.1.1 Zephyr-7B-alpha1.1.2 Zephyr-7B-beta 1.2 摘要1.3 相关工作1.4 算法1.4.1 蒸馏监督微调(dSFT)1.4.2 基于偏好的AI反馈 (AIF)1.4.3 直接蒸馏偏好优化&…
主题模型LDA教程:一致性得分coherence score方法对比(umass、c_v、uci)
文章目录 主题建模潜在迪利克雷分配(LDA)一致性得分 coherence score1. CV 一致性得分2. UMass 一致性得分3. UCI 一致性得分4. Word2vec 一致性得分5. 选择最佳一致性得分 主题建模
主题建模是一种机器学习和自然语言处理技术,用于确定文档…

【论文复现】QuestEval:《QuestEval: Summarization Asks for Fact-based Evaluation》
以下是复现论文《QuestEval: Summarization Asks for Fact-based Evaluation》(NAACL 2021)代码https://github.com/ThomasScialom/QuestEval/的流程记录: 在服务器上conda创建虚拟环境questeval(python版本于readme保持一致&…
GPT-4:论文阅读笔记
GPT-4的输入和输出:输入的内容是文本或图片,输出的内容是文本。因此,GPT-4是一种输入端多模态的模型。GPT-4的效果:在真实世界中还是比不上人类,但是在很多专业性的任务上已经达到了人类的水平,甚至超过人类…

【LLM】chatglm3的agent应用和微调实践
note
知识库和微调并不是冲突的,它们是两种相辅相成的行业解决方案。开发者可以同时使用两种方案来优化模型。例如: 使用微调的技术微调ChatGLM3-6B大模型模拟客服的回答的语气和基础的客服思维。接着,外挂知识库将最新的问答数据外挂给Chat…
使用 Python 和 NLTK 进行文本摘要
一、说明 文本摘要是一种自然语言处理技术,允许用户将大量文本总结为小块,而不会丢失任何重要信息。本文介绍NLP中使用Gensim和Sumy实现文本摘要的步骤。 二、为什么要总结文本? 互联网包含大量信息,而且每秒都在增加。文本摘要可…
Encoder、Decoder和Encoder-Decoder
首先LLM有3种架构:Encoder-only、Decoder-only、encode-decode
整体情况
1、Encoder将可变长度的输入序列编码成一个固定长度的向量,比如在bert中应用的encoder,其实是输入和输出是等长的向量。通常情况下,encoder是用来提取特征…
自然语言处理(NLP)练习题
问题:什么是自然语言处理(NLP)? 答案:自然语言处理(NLP)是一种人工智能技术,旨在让计算机理解和处理人类语言。NLP涉及语言学、计算机科学和人工智能等多个领域,旨在开发…
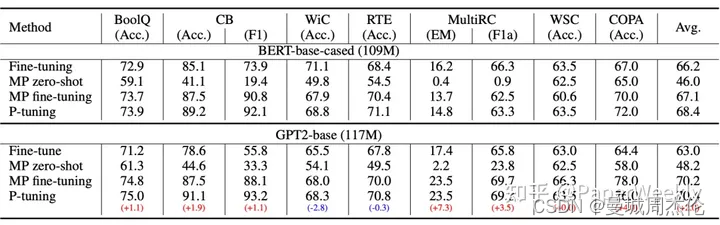
第十三章P-tuing系列之P-tuning V1
项目地址: P-Tuning
论文地址: [2103.10385] GPT Understands, Too (arxiv.org) 理论基础
正如果上一节介绍LoRA(自然语言处理: 第十二章LoRA解读_lora自然英语处理-CSDN博客)一样,本次介绍的在21年由清华团推提出来的 P-Tuning V1系列也属于PEFT(参数高效微调系列)里的一种&…
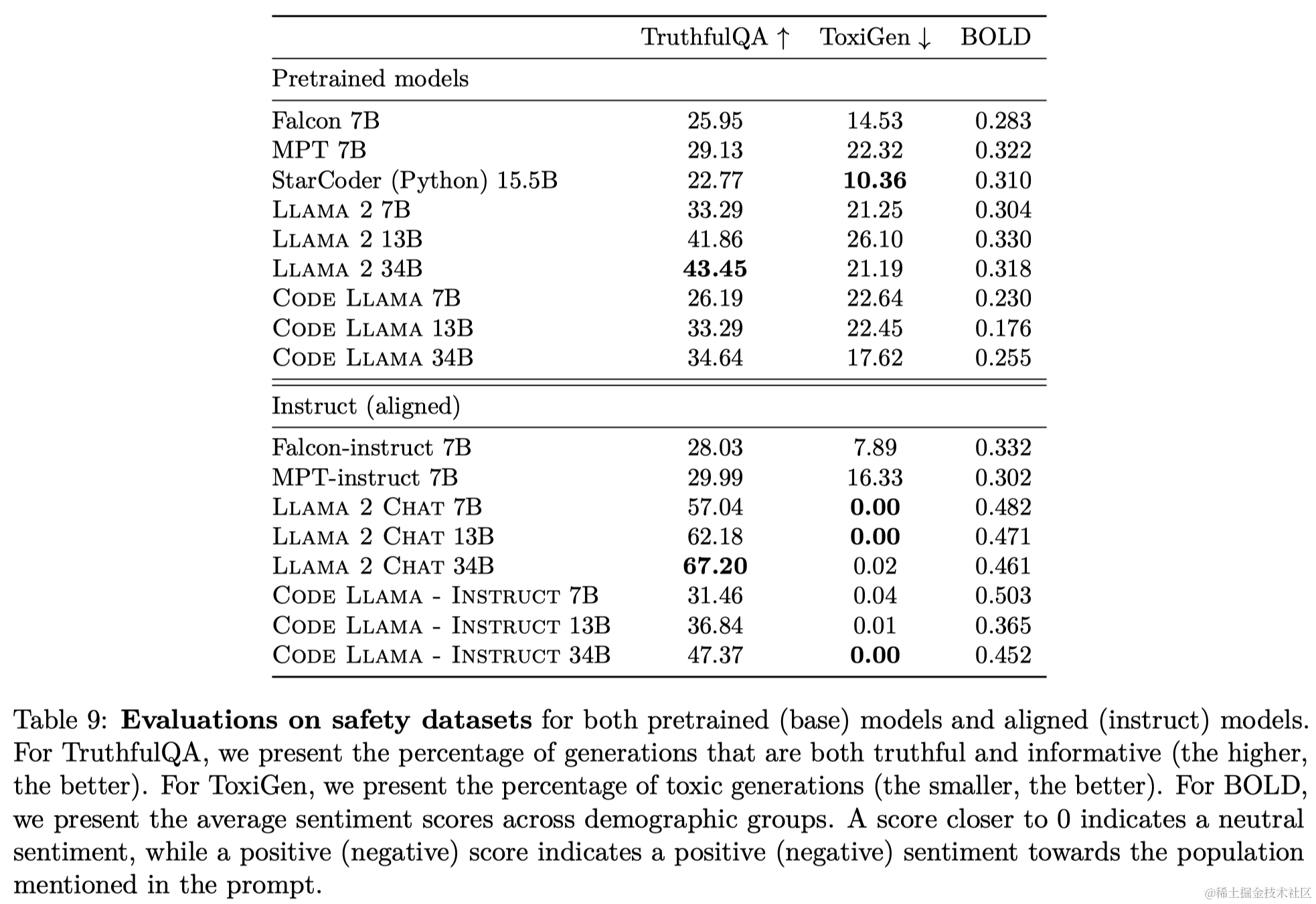
论文笔记:Code Llama: Open Foundation Models for Code
导语
Code Llama是开源模型Llama 2在代码领域的一个专有模型,作者通过在代码数据集上进行进一步训练得到了了适用于该领域的专有模型,并在测试基准中超过了同等参数规模的其他公开模型。
链接:https://arxiv.org/abs/2308.12950机构&#x…
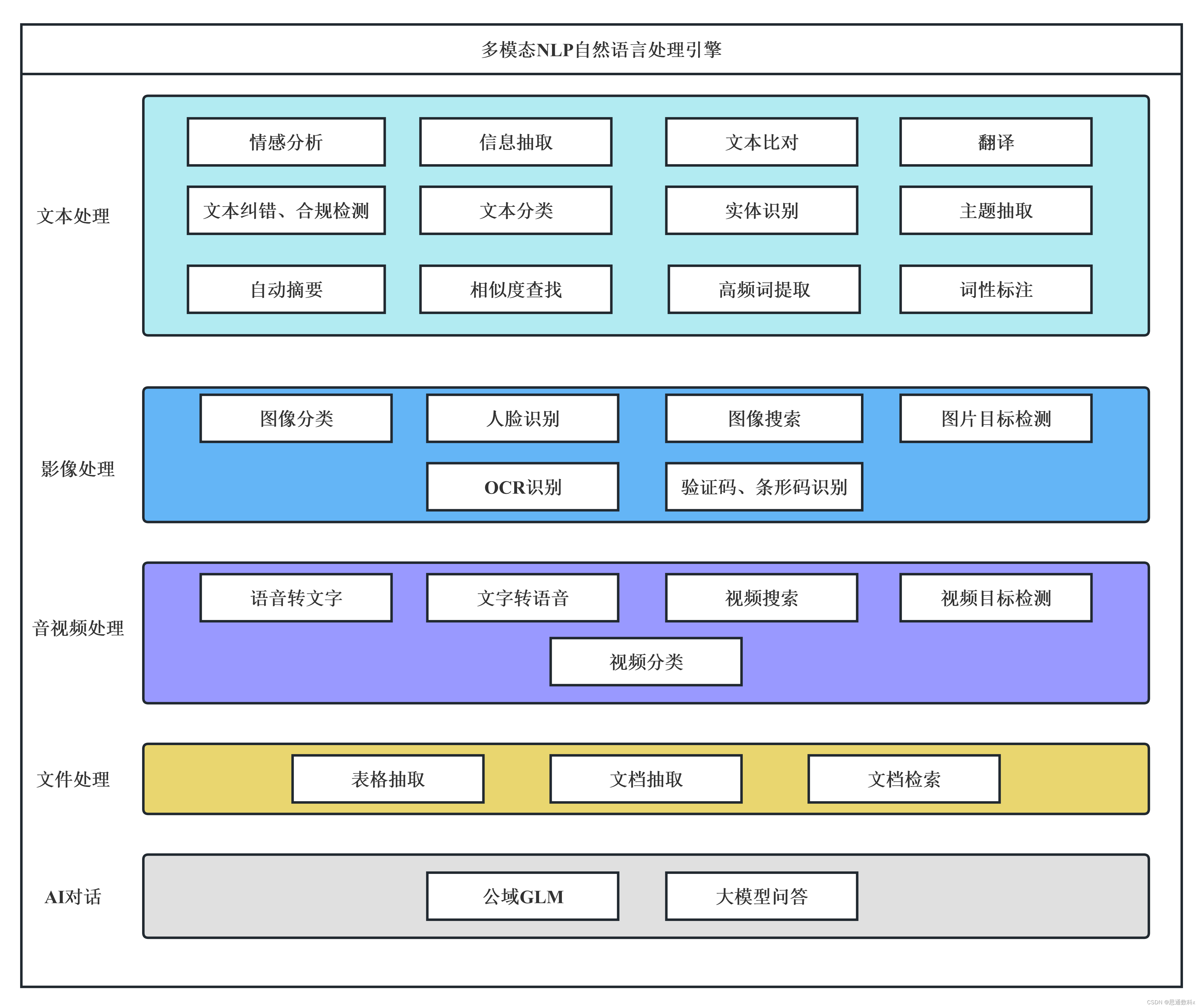
案例介绍:信息抽取技术在汽车销售与分销策略中的应用与实践
一、引言
在当今竞争激烈的汽车制造业中,成功的销售策略、市场营销和分销网络的构建是确保品牌立足市场的关键。作为一名经验丰富的项目经理,我曾领导一个专注于汽车销售和分销的项目,该项目深入挖掘市场数据,运用先进的信息抽取…

深入探索Transformer时代下的NLP革新
《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》主要聚焦于如何使用Python编程语言以及深度学习框架如PyTorch和TensorFlow来构建、训练和调整用于自然语言处理任务的深度神经网络架构,特别是以Transformer为核心模型的架构。
书中详细介绍了Transf…
自然语言处理: 第十三章P-tuing系列之P-tuning V1
项目地址: P-Tuning
论文地址: [2103.10385] GPT Understands, Too (arxiv.org) 理论基础
正如果上一节介绍LoRA(自然语言处理: 第十二章LoRA解读_lora自然英语处理-CSDN博客)一样,本次介绍的在21年由清华团推提出来的 P-Tuning V1系列也属于PEFT(参数高效微调系列)里的一种&…
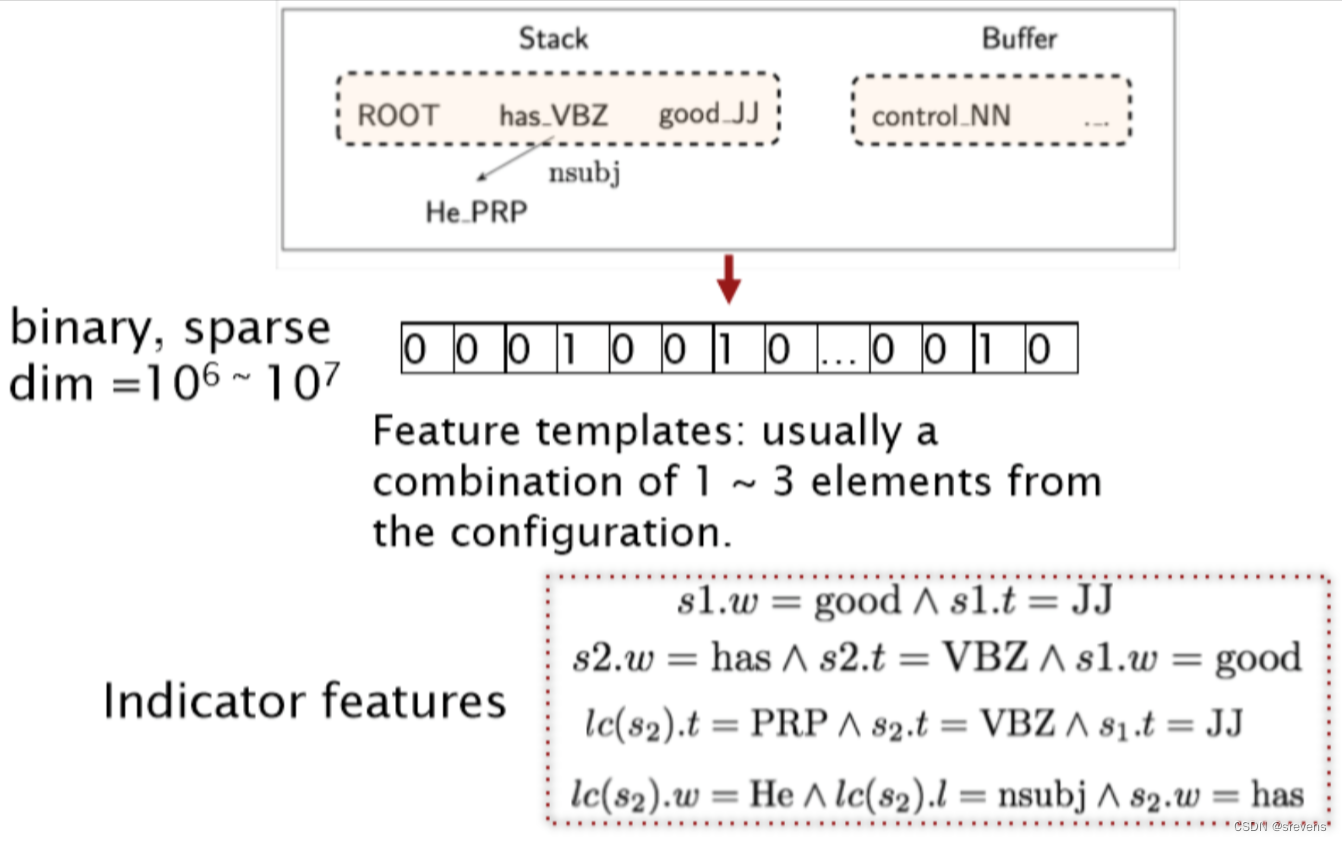
NLP - 依存句法分析、句子歧义
1. 语言结构的两种观点
Constituency phrase struct grammar context-free grammars(CFGs)Dependency structure
对于context-free grammars(CFGs)
短语结构(Constituency):短语结构语法是一种描述语言结构的方法,它将句子划…
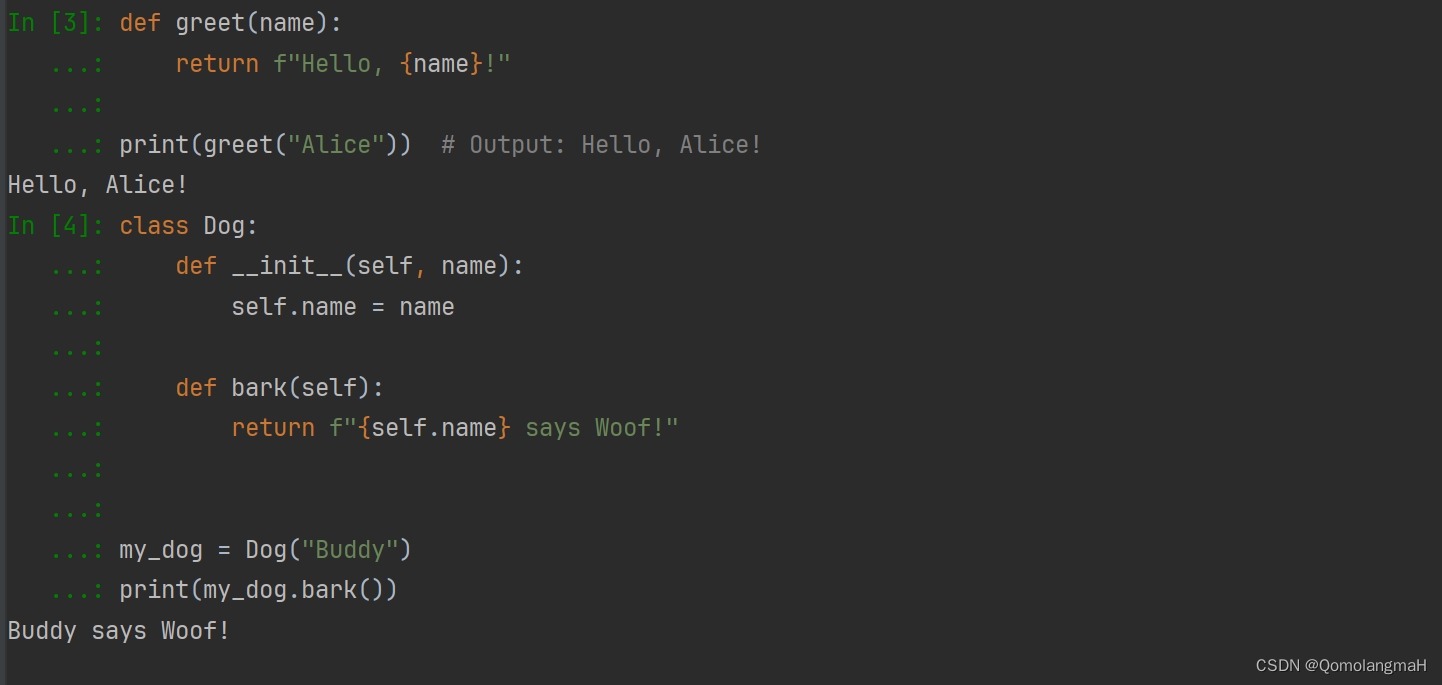
【自然语言处理】NLP入门(五):1、正则表达式与Python中的实现(5):字符串常用方法:对齐方式、大小写转换详解
文章目录 一、前言二、正则表达式与Python中的实现1.字符串构造2. 字符串截取3. 字符串格式化输出4.字符转义符5. 字符串常用函数函数与方法之比较 6. 字符串常用方法1. 对齐方式center()ljust()rjust() 2. 大小写转换lower()upper()capitalize()title()swapcase() 一、前言 本…
NLP:自定义模型训练
书接上文,为了完成指定的任务,我们需要额外训练一个特定场景的模型
这里主要参考了这篇博客:大佬的博客
我这里就主要讲一下我根据这位大佬的博客一步一步写下时,遇到的问题:
文中的cfg在哪里下载? 要不…
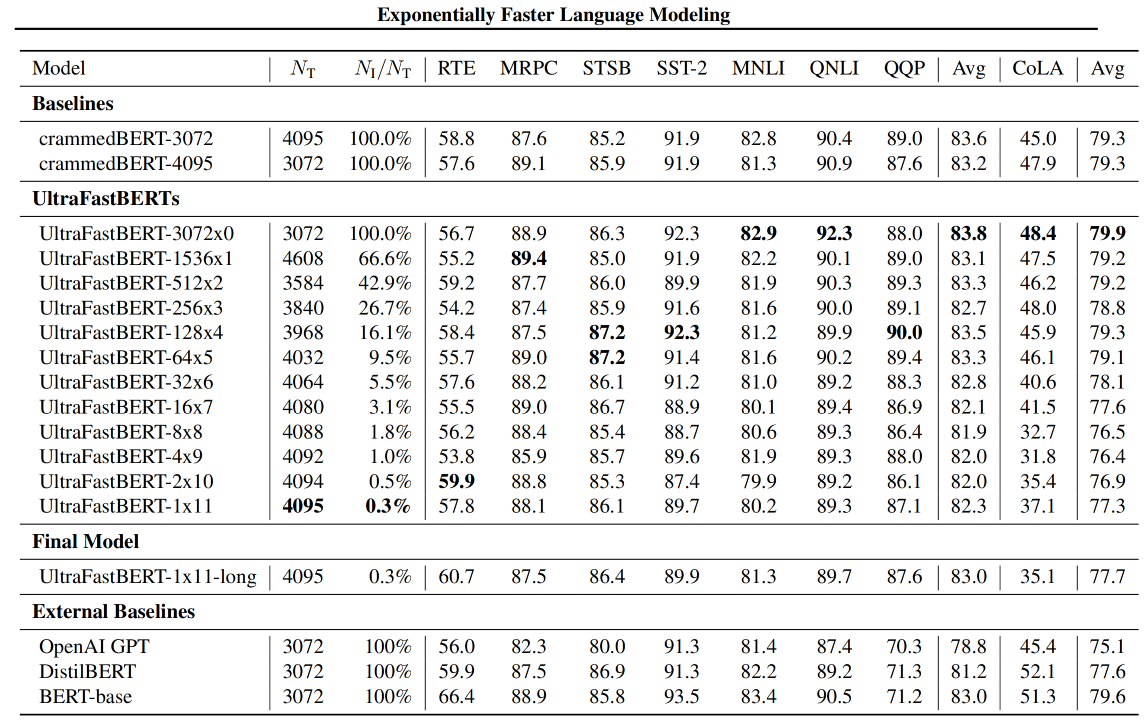
【LM、LLM】浅尝二叉树在前馈神经网络上的应用
前言
随着大模型的发展,模型参数量暴涨,以Transformer的为组成成分的隐藏神经元数量增长的越来越多。因此,降低前馈层的推理成本逐渐进入视野。前段时间看到本文介绍的相关工作还是MNIST数据集上的实验,现在这个工作推进到BERT上…
从零构建属于自己的GPT系列2:模型训练1(预训练中文模型加载、中文语言模型训练、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
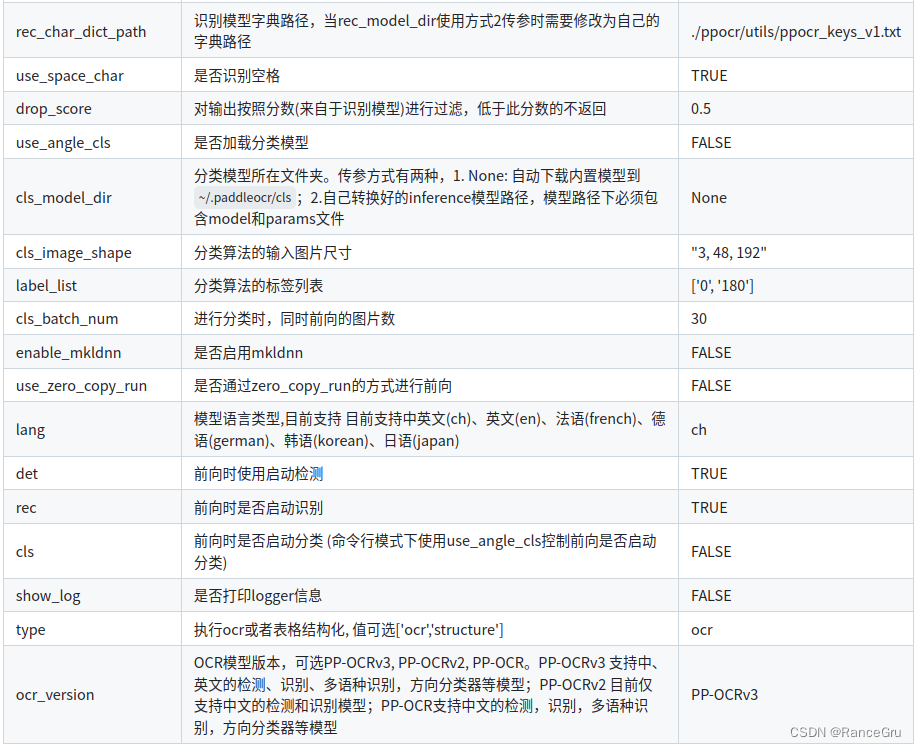
视觉学习笔记12——百度飞浆框架的PaddleOCR 安装、标注、训练以及测试
系列文章目录
虚拟环境部署 参考博客1 参考博客2 参考博客3 参考博客4 文章目录 系列文章目录一、简单介绍1.OCR介绍2.PaddleOCR介绍 二、安装1.anaconda基础环境1)anaconda的基本操作2)搭建飞浆的基础环境 2.安装paddlepaddle-gpu版本1)安装…
Text mining and natural language processing in construction 论文阅读
摘要
文本挖掘 ™ 和自然语言处理 (NLP) 引起了建筑领域的兴趣,因为它们提供了管理和分析基于文本的信息的增强功能。这凸显了需要从施工管理的角度进行系统审查,以确定现状、差距和未来方向。通过将 205 份出版物的目标与施工管理实践中概述的具体领域…
从零构建属于自己的GPT系列6:模型部署2(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
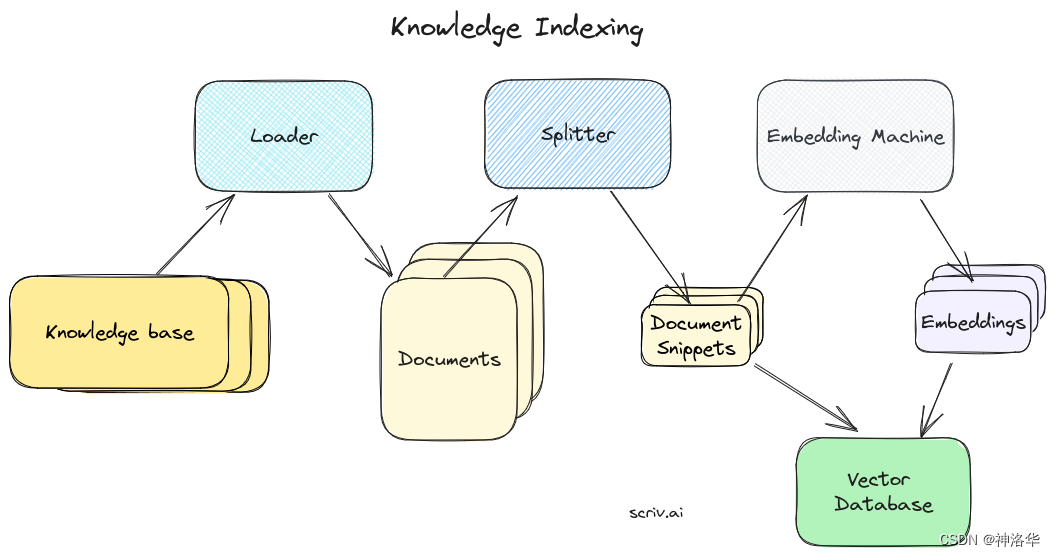
LangChain(0.0.340)官方文档九:Retrieval——Text embedding models、Vector stores、Indexing
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、Text embedding models1.1 Embeddings类1.2 OpenAI1.3 Sentence Transformers on Hugging Face1.4 CacheBackedEmbeddings1.4.1 简介1.4.2 与Vector Store一起使用1.4.3 内…
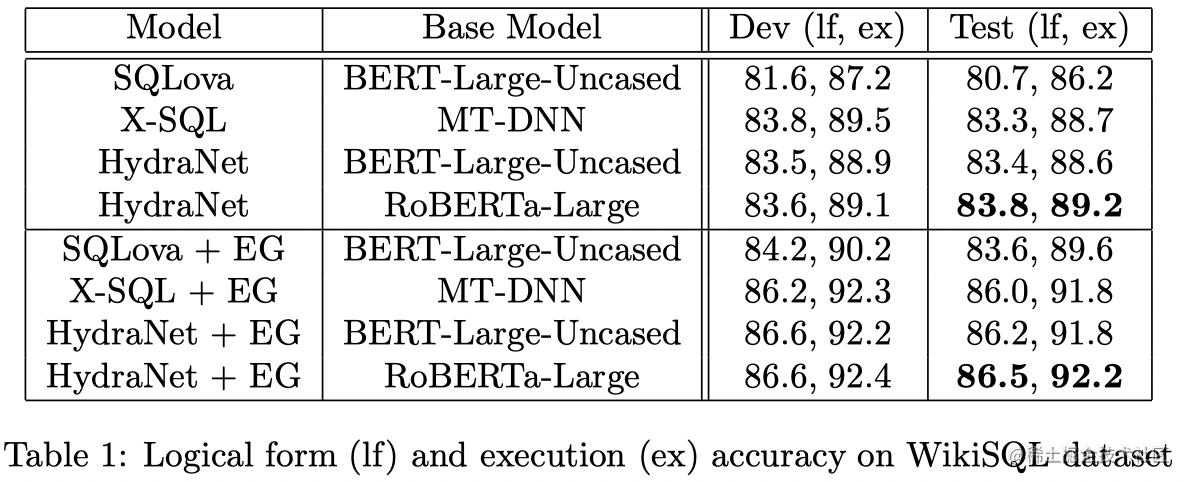
Text2SQL学习整理(五)将Text-to-SQL任务与基本语言模型结合
导语
上篇博客:Text2SQL学习整理(四)将预训练语言模型引入WikiSQL任务简要介绍了两个借助预训练语言模型BERT来解决WIkiSQL数据集挑战的方法:SQLOVA和X-SQL模型。其中,借助预训练语言模型的强大表示能力,S…

语言模型:从n-gram到神经网络的演进
目录 1 前言2 语言模型的两个任务2.1 自然语言理解2.2 自然语言生成 3 n-gram模型4 神经网络语言模型5 结语 1 前言
语言模型是自然语言处理领域中的关键技术之一,它致力于理解和生成人类语言。从最初的n-gram模型到如今基于神经网络的深度学习模型,语言…
Kneser-Ney平滑(Kneser-Ney smoothing)简介
Chat-GPT 3.5给的答案,先记在这里,后面有机会深入了解再补充。
Kneser-Ney平滑(Kneser-Ney smoothing)是一种用于解决语言模型中零概率问题的平滑技术。它是由Kneser和Ney在1995年提出的,被广泛应用于n-gram语言模型中…
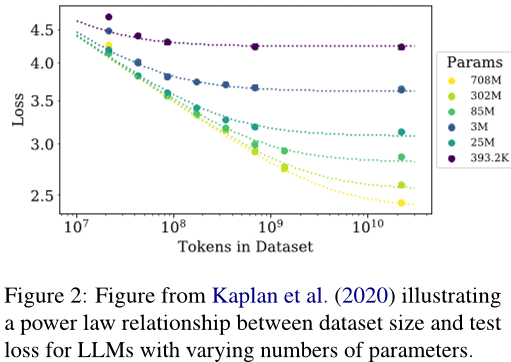
【概述版】悲剧先于解析:在大型语言模型的新时代,历史重演了
这篇论文探讨了大型语言模型(LLM)的成功对自然语言处理(NLP)领域的影响,并提出了在这一新时代中继续做出有意义贡献的方向。作者回顾了2005年机器翻译中大型语法模型的第一个时代,并从中汲取教训和经验。他…
中英双语大模型ChatGLM论文阅读笔记
论文传送门: [1] GLM: General Language Model Pretraining with Autoregressive Blank Infilling [2] Glm-130b: An open bilingual pre-trained model Github链接: THUDM/ChatGLM-6B 目录 笔记Abstract 框架总结1. 模型架构2. 预训练设置3. 训练稳定性…
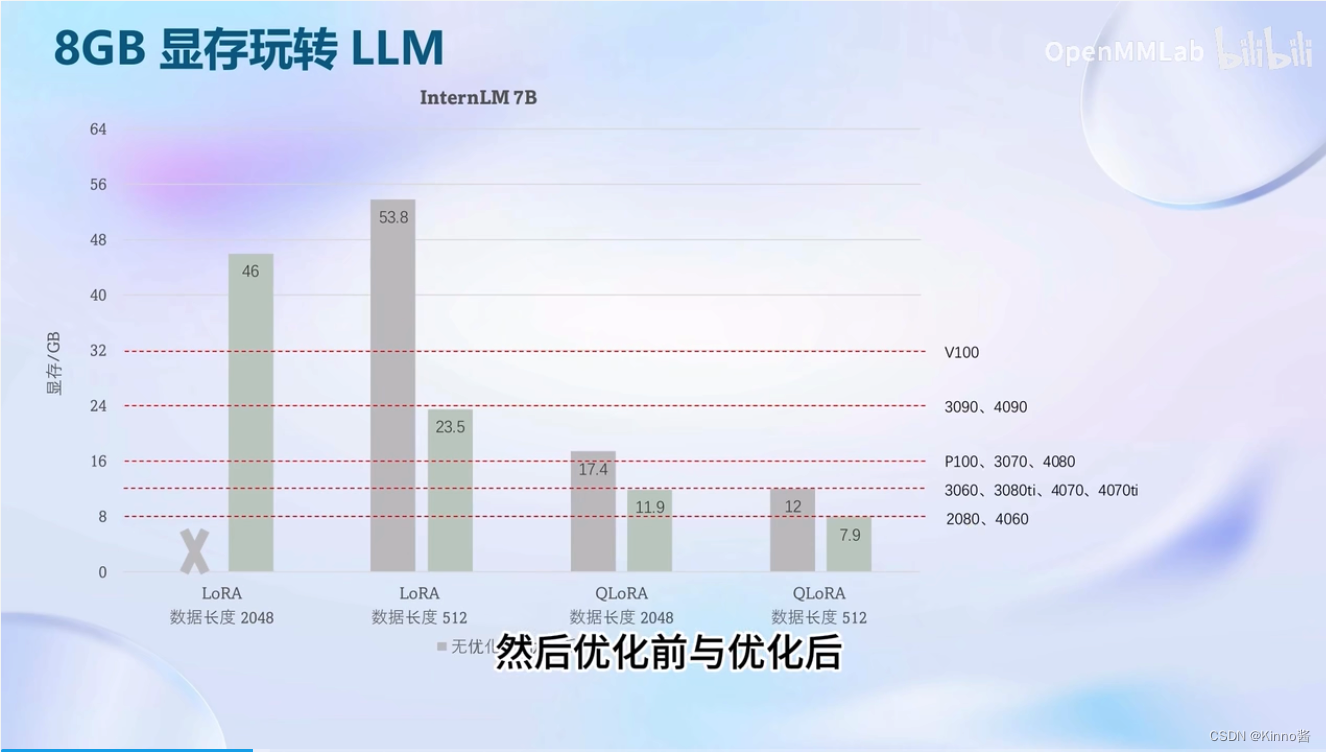
书生·浦语大模型实战营-学习笔记4
XTuner 大模型单卡低成本微调实战 Finetune简介
常见的两种微调策略:增量预训练、指令跟随
指令跟随微调
数据是一问一答的形式 对话模板构建 每个开源模型使用的对话模板都不相同
指令微调原理: 由于只有答案部分是我们期望模型来进行回答的内容…

java 开源中文的繁简体转换工具 opencc4j
Opencc4j
Opencc4j 支持中文繁简体转换,考虑到词组级别。
Features 特点 严格区分「一简对多繁」和「一简对多异」。 完全兼容异体字,可以实现动态替换。 严格审校一简对多繁词条,原则为「能分则不合」。 词库和函数库完全分离ÿ…

【AI视野·今日NLP 自然语言处理论文速览 第七十五期】Thu, 11 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 11 Jan 2024 Totally 36 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Leveraging Print Debugging to Improve Code Generation in Large Language Models Authors Xueyu Hu, Kun K…
Huggingface上传自己的模型
5.8更新几个比较坑的点
首先如果你的模型太大(>5GB),那么需要使用下面的命令声明一下,否则无法push
$ huggingface-cli lfs-enable-largefiles ./path/to/your/repo假如使用VScode提交,那么需要注意,在…

TensorFlow2实战-系列教程9:RNN文本分类1
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 1、文本分类任务
1.1 文本分类
数据集构建:影评数据集进行情感分析&…
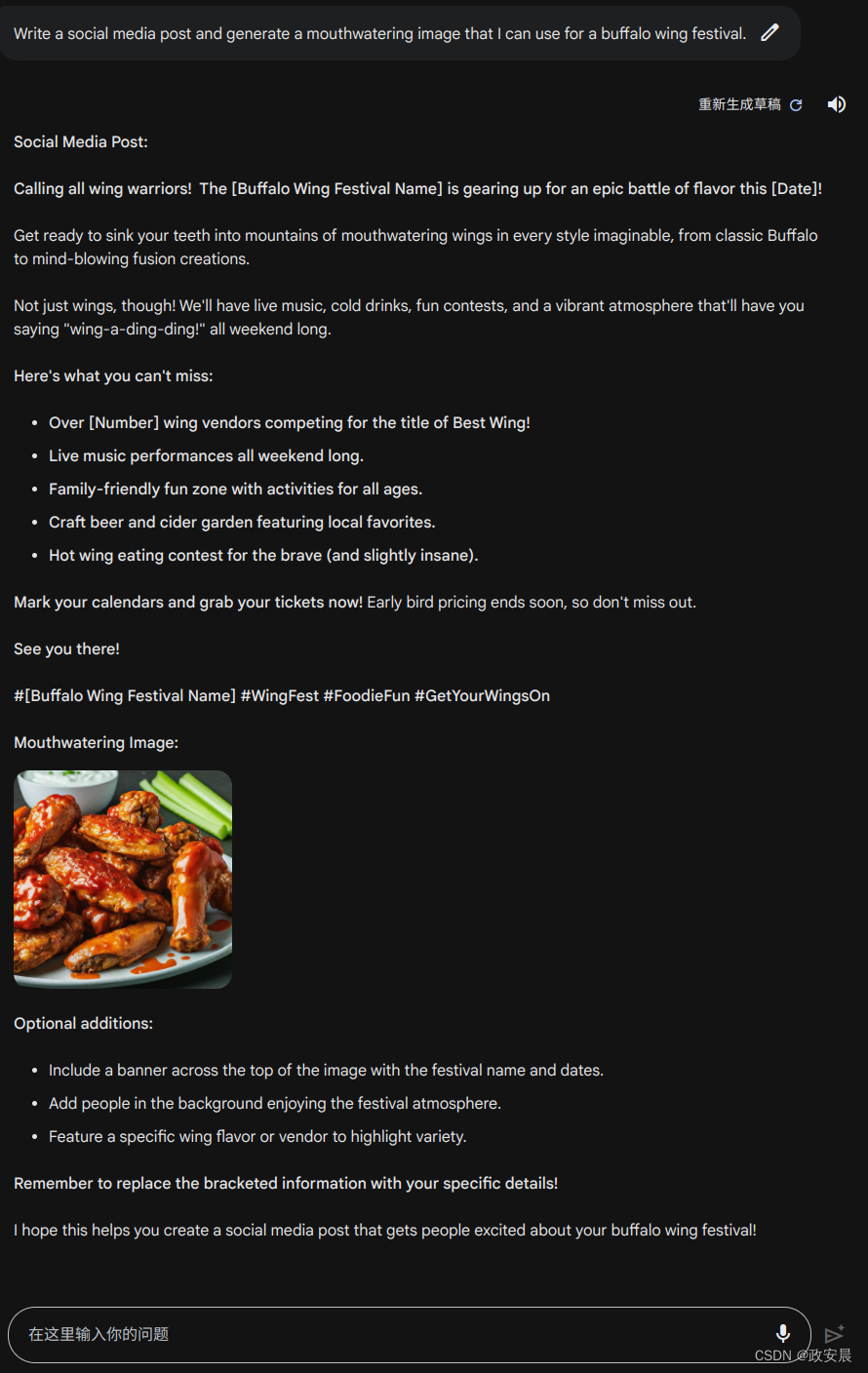
政安晨的AI笔记——Bard大模型最新提示词创作绘画分析
AI大模型进入商业应用元年后的第一年,顶级模型大混战终于开始了。
Bard在追赶OpenAI的过程中,还是补上了画图的短板。
(相比于视频的5阶张量处理而言,图画做为4阶张量处理虽然不新鲜,但却是跨不过去的基础条件&#…
【爬虫实战】全过程详细讲解如何使用python获取抖音评论,包括二级评论
简介:
前两天,TaoTao发布了一篇关于“获取抖音评论”的文章。但是之前的那一篇包涵的代码呢仅仅只能获取一级评论。虽然说抖音的一级评论挺精彩的了,但是其实二级评论更加有意思,同时二级评论的数量是很多。所以二级评论是非常值…
![[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)](https://img-blog.csdnimg.cn/direct/48f1bd6566364ab88ba1f5fb9cb9b583.png)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)。
自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要分支,涉及了处理和理解人类语言的技术…

Transformers —— 以通俗易懂的方式解释-Part 1
公众号:Halo咯咯,欢迎关注~ 本系列主要介绍了为ChatGPT以及许多其他大型语言模型(LLM)提供支持的Transformer神经网络。我们将从基础的Transformer概念开始介绍,尽量避免使用数学和技术细节,使得更多人能够理解这一强大的技术。
Transformers —— 以通俗易懂的方式解释…
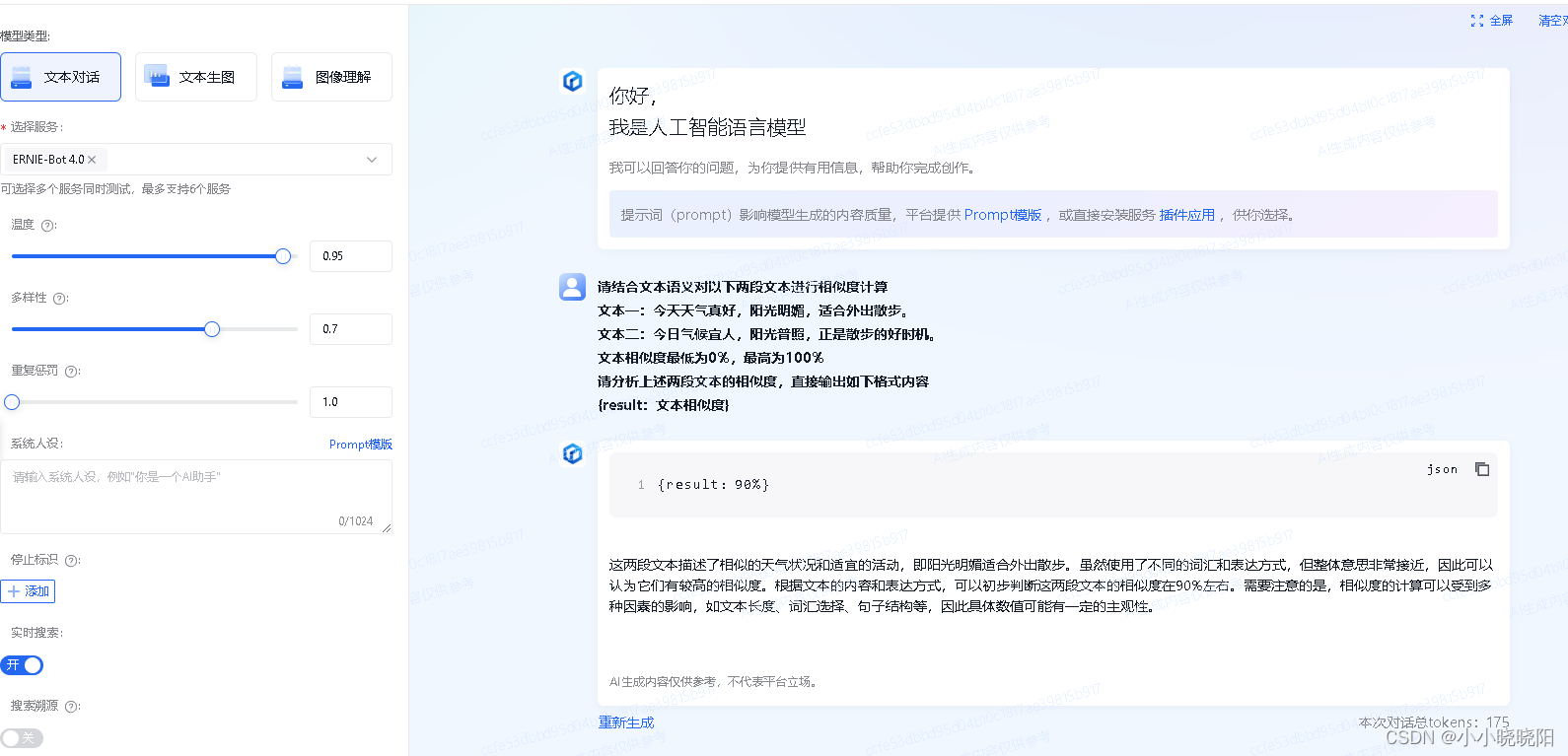
如何利用大模型结合文本语义实现文本相似度分析?
常规的文本相似度计算有TF-IDF,Simhash、编辑距离等方式,但是常规的文本相似度计算方式仅仅能对文本表面相似度进行分析计算,并不能结合语义分析,而如果使用机器学习、深度学习的方式费时费力,效果也不一定能达到我们满…
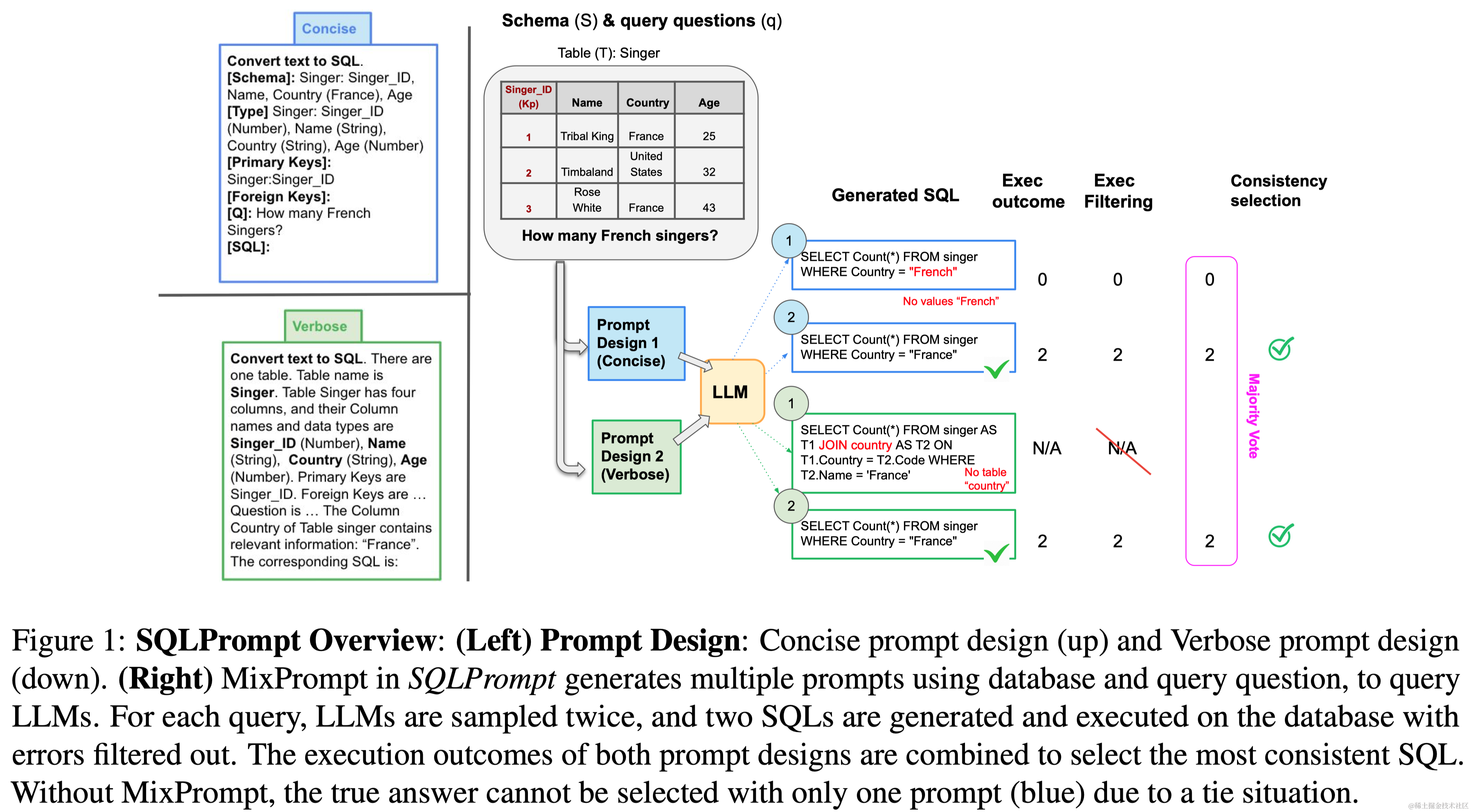
EMNLP 2023精选:Text-to-SQL任务的前沿进展(下篇)——Findings论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…

【AI视野·今日NLP 自然语言处理论文速览 第七十九期】Thu, 18 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 18 Jan 2024 Totally 35 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics …

CCL 2024投稿指南
诸神缄默不语-个人CSDN博文目录
因为ACL估计要寄,所以我准备……如果ACL寄了,我就3天火线转投CCL
CCL 2024官网:第二十三届中国计算语言学大会 - CCL 2024 提交网址:CCL 2024 Conference | OpenReview
2024.4.18 截稿 2024.5.1…
CogVLM与CogAgent:开源视觉语言模型的新里程碑
引言
随着机器学习的快速发展,视觉语言模型(VLM)的研究取得了显著的进步。今天,我们很高兴介绍两款强大的开源视觉语言模型:CogVLM和CogAgent。这两款模型在图像理解和多轮对话等领域表现出色,为人工智能的…

chatGLM中GLM设计思路
GLM是结合了MLM和CLM的一种预训练方式,其中G为general;在GLM中,它不在以某个token为粒度,而是一个span(多个token),这些span之间使用自编码方式,而在span内部的token使用自回归的方式…
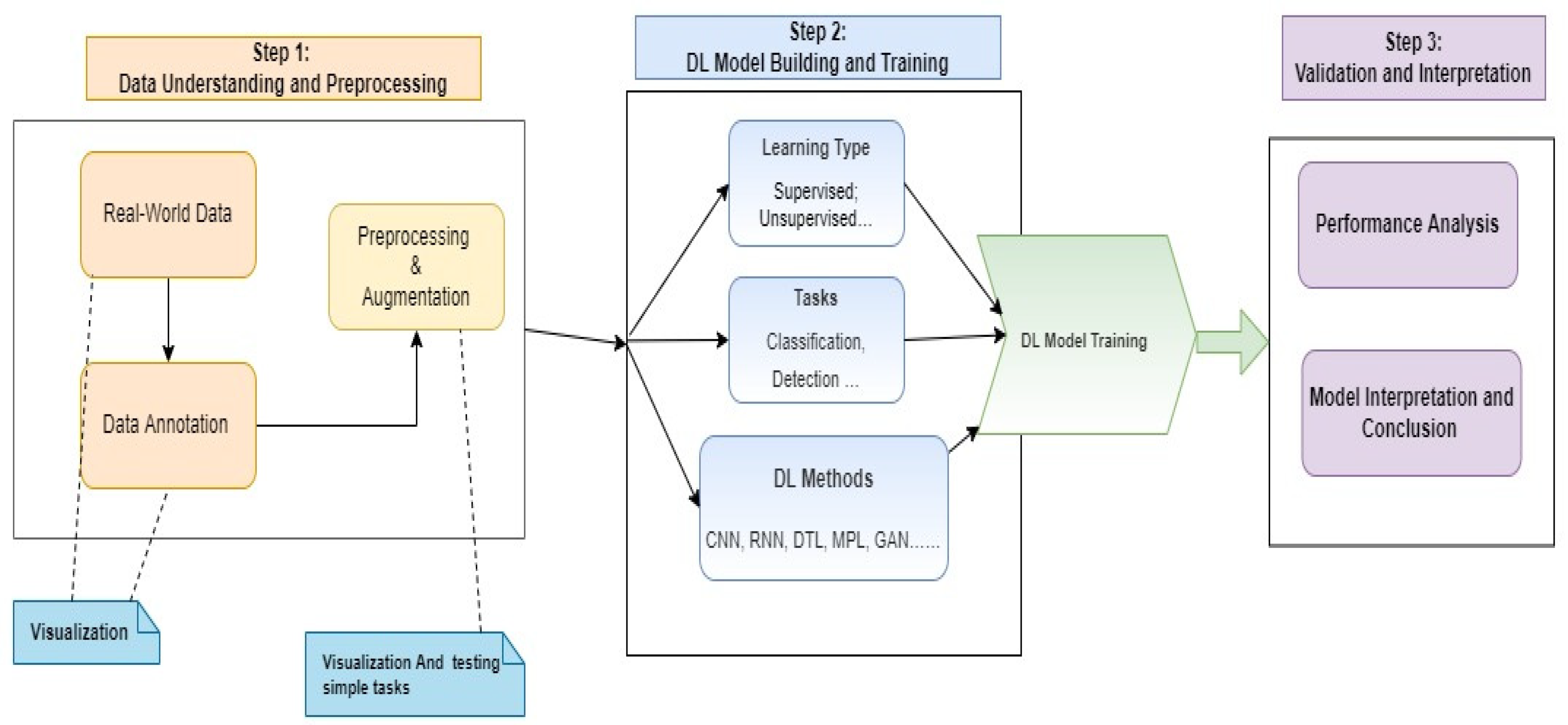

BERT模型结构可视化与模块维度转换剖析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
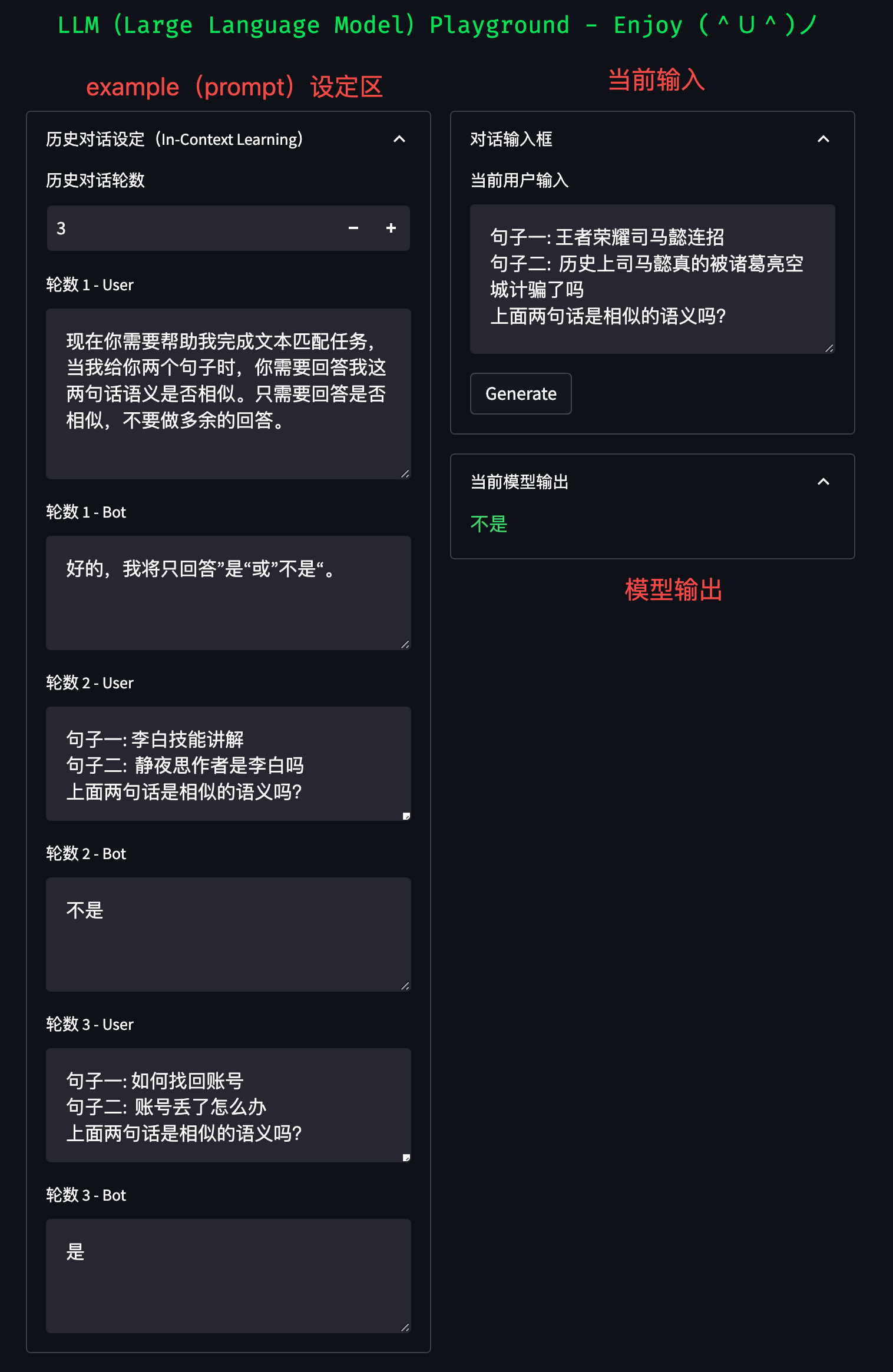
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用
随着 ChatGPT 和 GPT-4 等强大生成模型出现,自然语言处理任务方式正在逐步发生改变。鉴于大模型强大的任务处理能力,未来我们或将不再为每…

NLP | SentenceTransformer将句子进行编码并计算句子语义相似度
环境设置:
SentenceTransformertransformers
SentenceTransformers Documentation — Sentence-Transformers documentation (sbert.net)
Sentence Transformer是一个Python框架,用于句子、文本和图像嵌入Embedding。
这个框架计算超过100种语言的句子…

DevChat:VSCode中基于大模型的AI智能编程助手
文章目录 1. 前言2. 安装2.1 注册新用户2.2 在VSCode中安装DevChat插件2.3 设置Access Key 3. 实战使用4. 总结 1. 前言 DevChat是由Merico公司精心打造的AI智能编程助手。它利用了最先进的大语言模型技术,像人类开发者一样高效地理解需求,并提供最佳的代…
知识图谱入门 (五) 知识存储
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 知识存储,即获取到的三元组和schema如何存储在计算机中。本节从以Jena为例,对知识在数据库中的导入、存储、查询、更新做一个简要的介绍,而后对主流…

知识图谱入门 (二) 知识表示与知识建模
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本讲首先对早期的知识表示做了一个简单介绍,而后详细介绍了基于语义网的知识表示框架,如RDF和RDFS和查询语言SQARQL。最终给出几个典型的知识项目的知识表示。…
Re59:读论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 模型开源地址:https://huggingface.co/facebook/rag-token-nq
ArXiv下载地址:https://arxi…
安装spacy+zh_core_web_sm避坑指南
目录 一、spacy简介
二、安装spacy
三、安装zh_core_web_sm
四、安装en_core_web_sm
五、效果测试
5.1 英文测试
5.2 中文测试 一、spacy简介
spacy是Python自然语言处理(NLP)软件包,可以对自然语言文本做词性分析、命名实体识别、依赖…

OpenAI-ChatGPT最新官方接口《微调ChatGPT模型》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(四)(附源码)
微调ChatGPT模型前言Introduction 导言What models can be fine-tuned? 哪些模型可以微调?Installation 安装Prepare training data 准备训练数据CLI data preparation tool CLI数据准备工具Create a fine-tuned model 创建微调模型Use a fine-tuned model 使用微调…
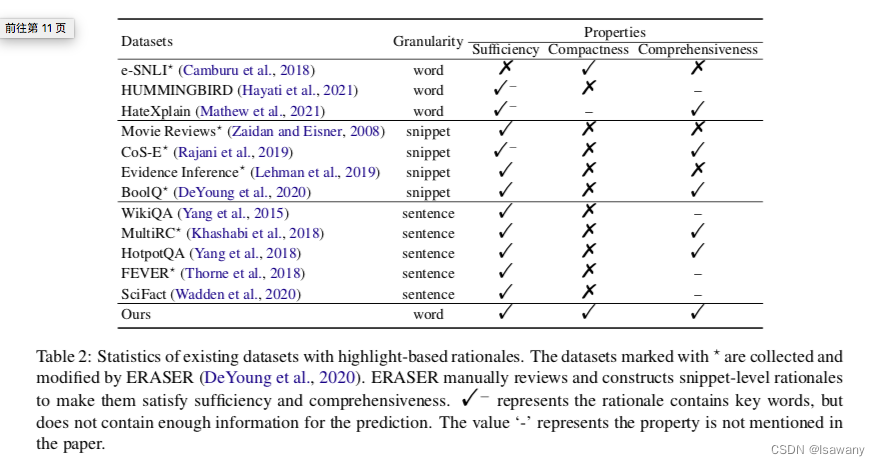
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP 1. 文章简介2. 文章概括3 文章重点技术3.1 数据收集3.2 数据扰动3.3 迭代标注和检查根因3.4 度量3.4.1 Token F1-score3.4.2 MAP(Mean Average Precision) 4. 文章亮点5. 原文传送门 1. 文章简…

VS2017配置Ipopt-基于Windows环境
文章目录 1、 背景2、 配置流程3、测试THE END 1、 背景 \qquad 本科研狗最近手头有个非线性规划模型需要求解,因为Ipopt是一款开源的NLP求解器,所以想要使用一下下。于是直接搜Ipopt官网,果然令人惊喜地列出了安装教程,但对于Win…
【NLP开发】Python实现聊天机器人(ChatterBot,集成web服务)
🍺NLP开发系列相关文章编写如下🍺:
🎈【NLP开发】Python实现词云图🎈🎈【NLP开发】Python实现图片文字识别🎈🎈【NLP开发】Python实现中文、英文分词🎈🎈【N…

基于静态和动态特征融合的语音情感识别层次网络
题目Hierarchical Network based on the Fusion of Static and Dynamic Features for Speech Emotion Recognition时间2021年期刊\会议ICASSP
基于静态和动态特征融合的语音情感识别层次网络
摘要:许多关于自动语音情感识别(SER)的研究都致…
NLP - IRSTLM、SRILM
文章目录IRSTLM关于 IRSTLM安装SRILM关于 SRILM安装使用 ngram-countKenLM 的安装使用,可参考文章: https://blog.csdn.net/lovechris00/article/details/125424808 IRSTLM
关于 IRSTLM
github : https://github.com/irstlm-team/irstlm官方主页&#…

【AI视野·今日NLP 自然语言处理论文速览 第七十一期】Fri, 5 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 5 Jan 2024 Totally 28 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LLaMA Pro: Progressive LLaMA with Block Expansion Authors Chengyue Wu, Yukang Gan, Yixiao Ge, Zeyu Lu, …

【自然语言处理】一篇文章入门分词(Tokenization)
分词 >_<,英文tokenization,也叫word segmentation,是一种操作,它按照特定需求,把文本切分成一个字符串序列(其元素一般称为token,或者叫词语)。 英文分词
英文分词极为简单,下面给出两种分词思路&a…

NLP——part of speech (POS)中的隐马尔可夫模型 + Viterbi 算法
文章目录 POS隐马尔可夫模型计算简介转移概率矩阵(Transition matrix)观察矩阵(Observation / emission Matrix)预测 predictionVitervi 算法练习 POS
词性标注(Part-of-Speech Tagging,POS Tagging&#…
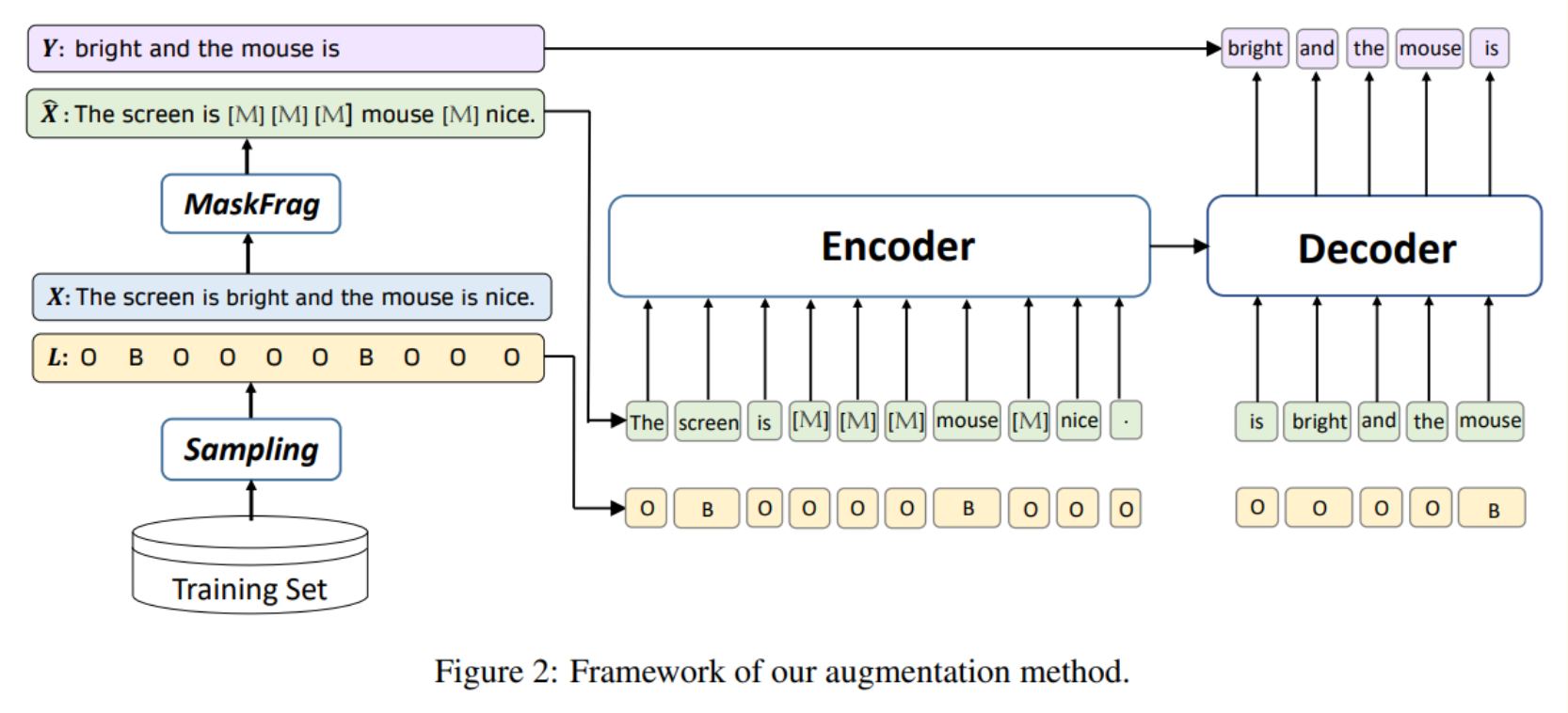
【ACL2020】Conditional Augmentation for Aspect Term Extraction via Masked Sequence-to-Sequence Generat
Conditional Augmentation for Aspect Term Extraction via Masked Sequence-to-Sequence Generation
本文提出了一种用于ATE(识别情感目标——序列标注)任务的数据增强方法 本文针对ATE任务数据缺乏的现状,提出了一种通过Masked Sequence-t…
NLP之CRF++安装及使用
目录 一、CRF简介
CRF VS 词典统计分词
CRF VS HMM,MEMM
CRF分词原理
二、CRF工具包
CRF的安装(linux)
CRF的使用 一、CRF简介
Conditional Random Field:条件随机场,一种机器学习技术(模型…
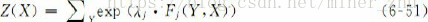
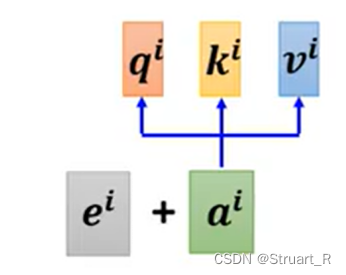
NLP(1)--NLP基础与自注意力机制
目录
一、词向量
1、概述
2、向量表示
二、词向量离散表示
1、one-hot
2、Bag of words
3、TF-IDF表示
4、Bi-gram和N-gram
三、词向量分布式表示
1、Skip-Gram表示
2、CBOW表示
四、RNN
五、Seq2Seq 六、自注意力机制
1、注意力机制和自注意力机制
2、单个输出…
推荐收藏!腾讯算法岗面试题9道(含答案)
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂同学、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
今天我整…
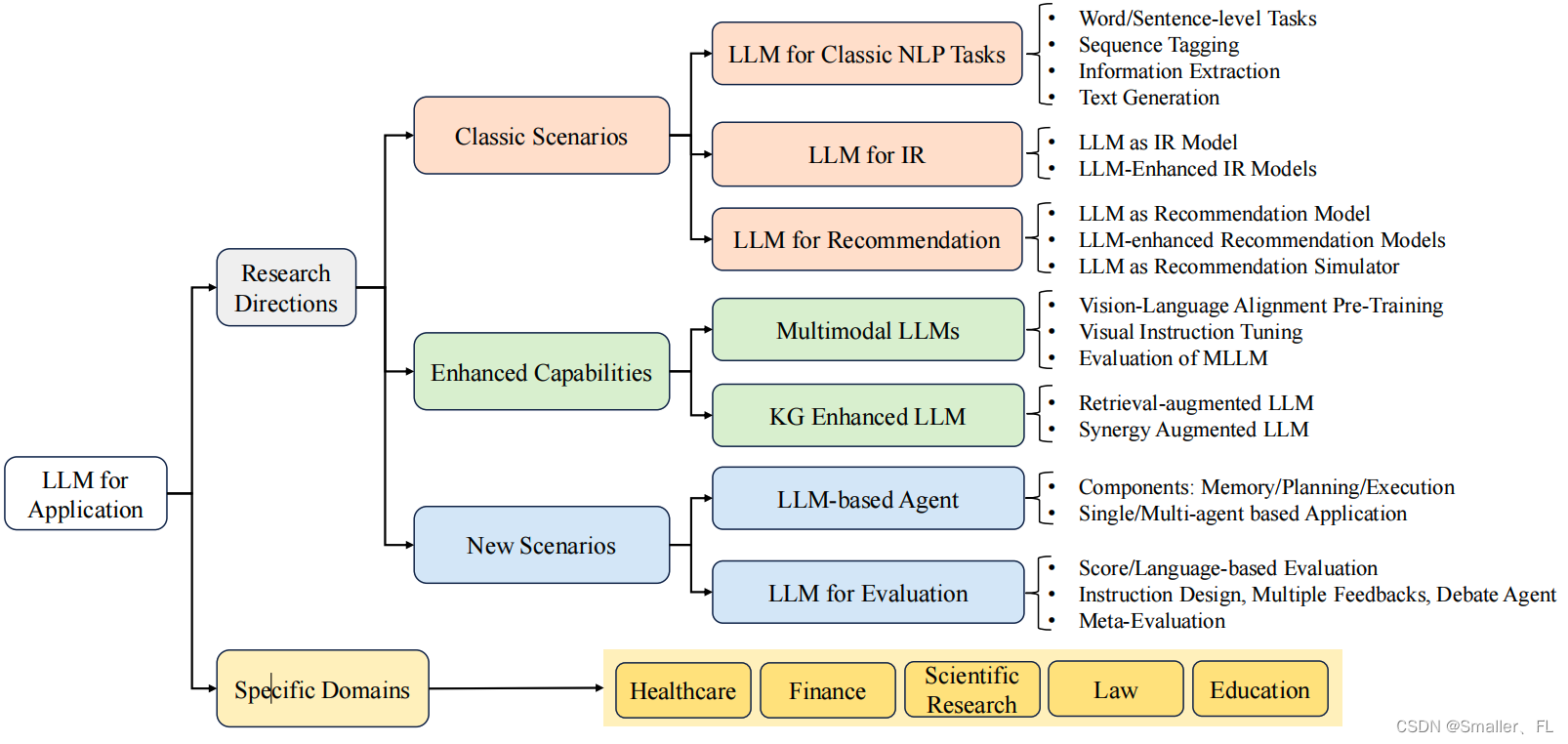
NLP深入学习:《A Survey of Large Language Models》详细学习(七)
文章目录 1. 前言2. 应用场景2.1 LLMs 对研究界的应用2.1.1 经典 NLP 任务2.1.2 信息检索2.1.3 推荐系统2.1.4 多模态大语言模型2.1.5 知识图谱增强型 LLM2.1.6 基于 LLM 的智能体2.1.7 用于评估 2.2 特定领域的应用 3. 参考 1. 前言
这是《A Survey of Large Language Models…
NLP「自然语言处理技术」
NLP是什么在计算机领域, NLP(Natural Language Processing),也就是人们常说的「自然语言处理」,就是研究如何让计算机读懂人类语言。这包括,既要能让计算机理解自然语言文本的意义,也能以自然语…

基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习
本项目给出本次法研杯详细的技术方案,从UIE-base开始到UIE数据蒸馏以及主动学习的建议,欢迎大家尝试,ps:主动学习标注需要自行实现,参考项目,楼主就不标注了。
项目链接:https://aistudio.baid…
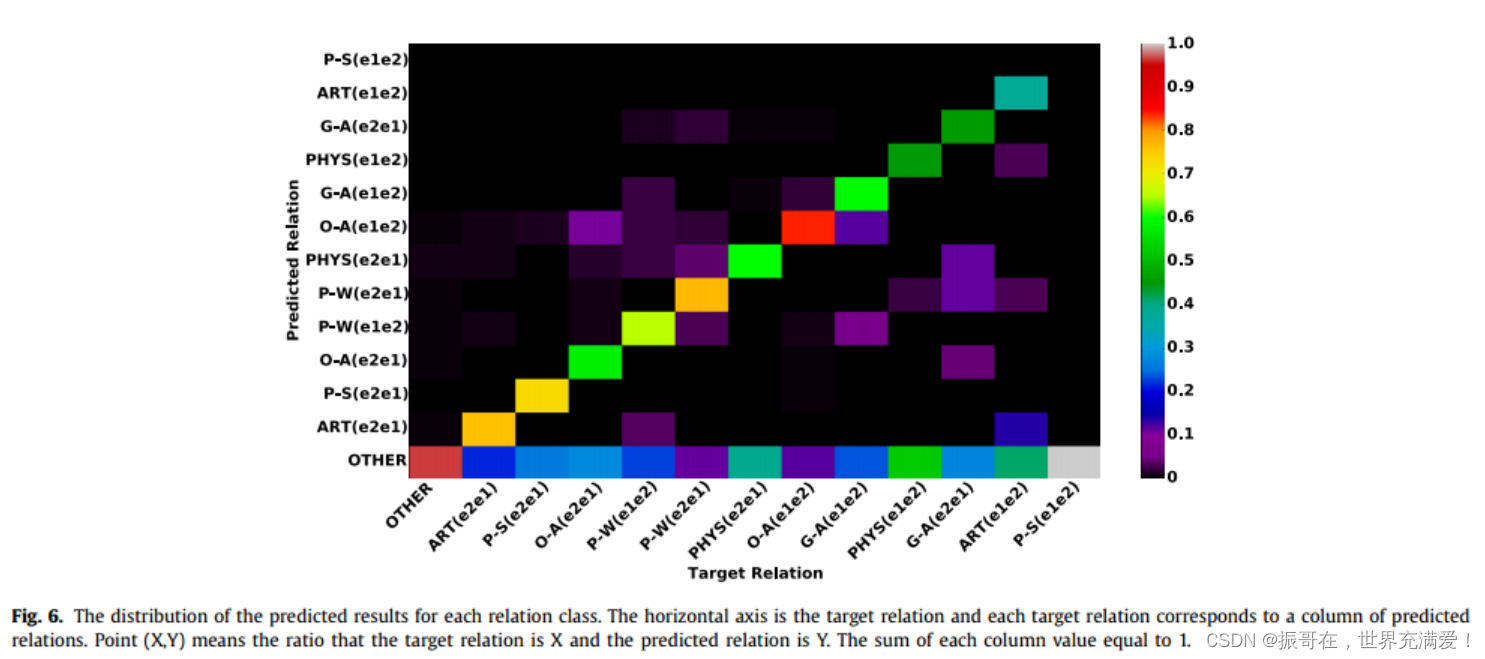
文献学习-联合抽取-Joint entity and relation extraction based on a hybrid neural network
目录
1、Introduction
2、Related works
2.1 Named entity recognition
2.2 Relation classification
2.3 Joint entity and relation extraction
2.4 LSTM and CNN models On NLP
3、Our method
3.1 Bidirectional LSTM encoding layer
3.2 Named entity recogniton …
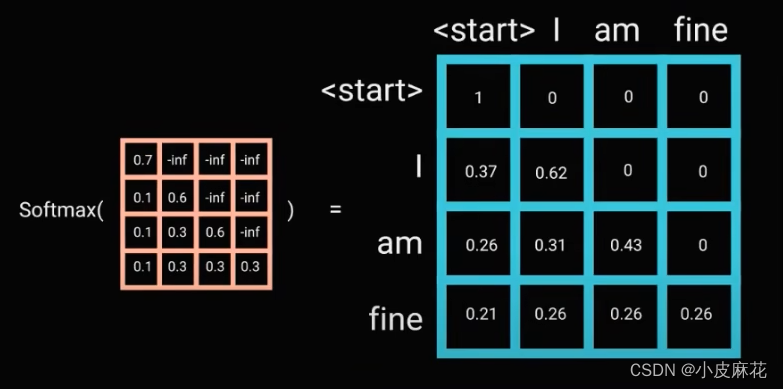
Transformer总结和梳理
Transformer总结和梳理Positional encodingSelf-attentionMulti--head-attentionAdd&NormAdd操作Norm操作FeedForwardMASKPadding MaskedSelf-Attention Masked首先来看一下Transformer结构的结构:Transformer是由Encoder和Decoder两大部分组成,首先…

【Python自然语言处理】规则分词中正向、反向、双向最大匹配法的讲解及实战(超详细 附源码)
需要源码和字典集请点赞关注收藏后评论区留言私信~~~ 一、规则分词
规则分词核心内容是建立人工专家词典库,通过将语句切分出的单词串与专家词典库中的所有词语进行逐一匹配,匹配成功则进行对象词语切分,否则通过增加或者减少一个字继续比较…
java实现实体关系抽取
前言:21年广州荔湾区成了疫情灾区,很多人都没有工作,被居家隔离,感染病毒概率死亡率是0.005%,没有工作死亡率是100%,因此作为普通老百姓,自己开发了一个数据分析工具,叫yandas。
信…
《统计自然语言处理》知识结构总结
一、自然语言处理概述 1)自然语言处理:利用计算机为工具,对书面实行或者口头形式进行各种各样的处理和加工的技术,是研究人与人交际中以及人与计算机交际中的演员问题的一门学科,是人工智能的主要内容。 2)…

NLP之自然语言处理简述
什么是自然语言处理?
自然语言处理是研究在人与人交际中以及人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力(linguistic competence)和语言应用(linguistic performance)的模型,建…
Bert文本聚类实践
问题来源:先做的huggingface-bert文本分类(参考text-classification,情感分类,数据集可以考虑SST2),但是数据量太大了,无法穷举所有的类别,故而先用分类来做,但这样也有一…

【AI视野·今日NLP 自然语言处理论文速览 第七十八期】Wed, 17 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 17 Jan 2024 (showing first 100 of 163 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Deductive Closure Training of Language Models for Coherence, Accur…

文本预处理:词袋模型(bag of words,BOW)、TF-IDF
文本预处理:词袋模型(bag of words,BOW)、TF-IDF这篇博客主要整理介绍文本预处理中的词袋模型(bag of words,BOW)和TF-IDF。
一、词袋模型(bag of words,BOW)…
获取并处理中文维基百科语料
获取语料
下载链接
处理语料
直接下载下来的维基百科语料是一个带有html和markdown标记的文本压缩包,基本不能直接使用。目前主流的开源处理工具主要有两个:1、Wikipedia Extractor;2、gensim的wikicorpus库。
然而,这两个主流…
![[特征工程]Chap4. 特征缩放:TF-IDF](https://img-blog.csdn.net/20180504014354961?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L25lbW95eQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[特征工程]Chap4. 特征缩放:TF-IDF
本章通过BOW 到tf-idf的变化,讨论 feature scaling 的效果.
TF-IDF: BOW的变种
tf-idf可以说就是BOW基础上的变种, 全称: term frequency- inverse document frequency ,中文: 词频-逆文件频率.
BOW记录文件中的词频, 明显的问题就是会强调一些没意义的词, 如英文中的 the and …
Elasticsearch:如何在 Elastic 中实现图片相似度搜索
作者:Radovan Ondas 在本文章,我们将了解如何通过几个步骤在 Elastic 中实施相似图像搜索。 开始设置应用程序环境,然后导入 NLP 模型,最后完成为你的图像集生成嵌入。
Elastic 图像相似性搜索概览 >> 如何设置环境
第一步…

NNLM的pytorch实现和注意点
目录原理部分代码代码注意点原理部分 为了通过前面的词预测后一个词。对于一个结构固定的模型来说,要求每个batch的输入数据的长度要一致将索引表示的词,转化为向量表示,作为输入层,将前面词的向量拼接才一起作为输入向量…
图解NLP模型发展:从RNN到Transformer
图解NLP模型发展:从RNN到Transformer
自然语言处理 (NLP) 是深度学习中一个颇具挑战的问题,与图像识别和计算机视觉问题不同,自然语言本身没有良好的向量或矩阵结构,且原始单词的含义也不像像素值那么确定和容易表示。一般我们需…
pytorch lstm
1、输入input:数据维度是 (seq, batch, feature),即序列长度、batch_size、每个时刻特征数量。
2、output, (hn, cn) nn.LSTM(input_size, hidden_size, num_layers)
input_size:每时刻输入特征数量
hidden_size:隐藏层特征数…
Bert CNN信息抽取
Github参考代码:https://github.com/Wangpeiyi9979/IE-Bert-CNN
数据集来源于百度2019语言与智能技术竞赛,在上述链接中提供下载方式。
感谢作者提供的代码。
1、信息抽取任务
给定schema约束集合及句子sent,其中schema定义了关系P以及其…
Huggingface的GenerationConfig 中的top_k与top_p详细解读
Huggingface的GenerationConfig 中的top_k与top_p详细解读 Top_kTop_p联合共用 Top_k
top-k是指只保留概率最高的前k个单词,然后基于剩余单词的概率进行归一化,从中随机抽取一个单词作为最终输出。这种方法可以限制输出序列的长度,并仍然保持…


《Focal Loss GHM Loss Dice Los》论文笔记
Focal Loss
在二分类问题中,交叉熵损失定义如下: yyy 表示真实值,取值0与1,ppp表示模型预测正类的概率,取值0到1。
为了表述方便,将上述公式重新表述为: 对于类别不平衡问题,我们…

大模型Founation Model
一、背景
自从chatgpt,gpt4以特别好的效果冲入人们的视野中,也使得AI产业发生了巨大变革,从17年以来的bert,将AI的各种领域都引入bert类的fine-tune方法,来解决单个领域单个任务的一一个预训练模型。在学术界和工业界…
NLP之jieba分词原理简析
一、jieba介绍
jieba库是一个简单实用的中文自然语言处理分词库。
jieba分词属于概率语言模型分词。概率语言模型分词的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。
jieba支持三种分词模式:
全模式,把句子…
NLP之情感信息抽取
情感信息抽取是一种关于细粒度文本的情感分析技术,旨在抽取情感文本中有价值的情感信息。
Liu(2007)将情感信息定义为一个5元组(O,F,SO,H,T),其中࿰…
BatchNormalization LayerNormerlization
BN(BatchNormalization) 与 LN(LayerNormerlization)的主要区别在于数据处理的维度不同,在NLP中,假设输入shape为(batch_size, seq_len,embedding_dim),则BN的处理维度为“seq_len”, LN的处理维…



深入理解BERT Transformer ,不仅仅是注意力机制
作者: 龙心尘 时间:2019年3月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89058309
大数据文摘与百度NLP联合出品 作者:Damien Sileo 审校:百度NLP、龙心尘 编译:张驰、毅航
为什么BERT…

用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/89036531
大数据文摘联合百度NLP出品 审校:百度NLP、龙心尘 编译:Andy,张驰 来源:towardsdatascien…
error: RPC failed; curl 28 OpenSSL SSL_read: Connection was reset, errno 10054
clone MiniGPT-4的时候报错
Cloning into MiniGPT-4...
error: RPC failed; curl 28 OpenSSL SSL_read: Connection was reset, errno 10054
fatal: the remote end hung up unexpectedly解决办法
先
git config --global http.sslVerify "false"然后再clone就好了…
目前自然语言处理的实际应用方法总结
自然语言处理的方法
分词
分词的任务定义为:输入一个句子,输出一个词语序列的过程。如将「严守一把手机关了。」输出为「严守一/把/手机/关/了。」
目前的两种主流方法包括基于离散特征的 CRF 和 BILSTM-CRF。
挑战包括交叉歧义、新词识别、领域移植…
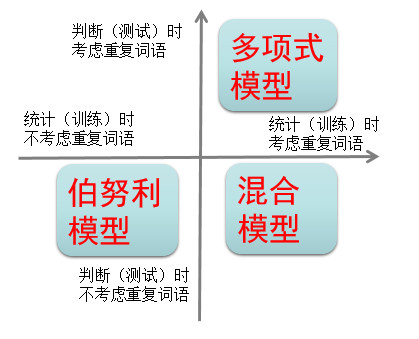
NLP系列(2)_用朴素贝叶斯进行文本分类(上)
作者:龙心尘 && 寒小阳
时间:2016年1月。
出处:
http://blog.csdn.net/longxinchen_ml/article/details/50597149
http://blog.csdn.net/han_xiaoyang/article/details/50616559
声明:版权所有,转载请联系…
NLP之中文命名实体识别(Named EntitiesRecognition--NER)
一、什么是命名实体识别
命名实体识别是识别一个句子中有特定意义的实体并将其区分为人名,机构名,日期,地名,时间等类别的工作。
命名实体识别本质上是一个模式识别任务, 即给定一个句子, 识别句子中实体的边界和实体的类型。是…
NLP之jieba中文分词官方文档
jieba
“结巴”中文分词:做最好的 Python 中文分词组件
特点
支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快࿰…

COLING 2022事件相关(事件抽取、事件关系抽取、事件预测等)论文汇总
COLING 2022事件抽取相关(事件抽取、事件关系抽取、事件预测等)论文汇总,已更新全部的论文讲解。
Event Extraction
OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction 讲解地址 提出一种新的标注策略,映射事件抽取为wo…
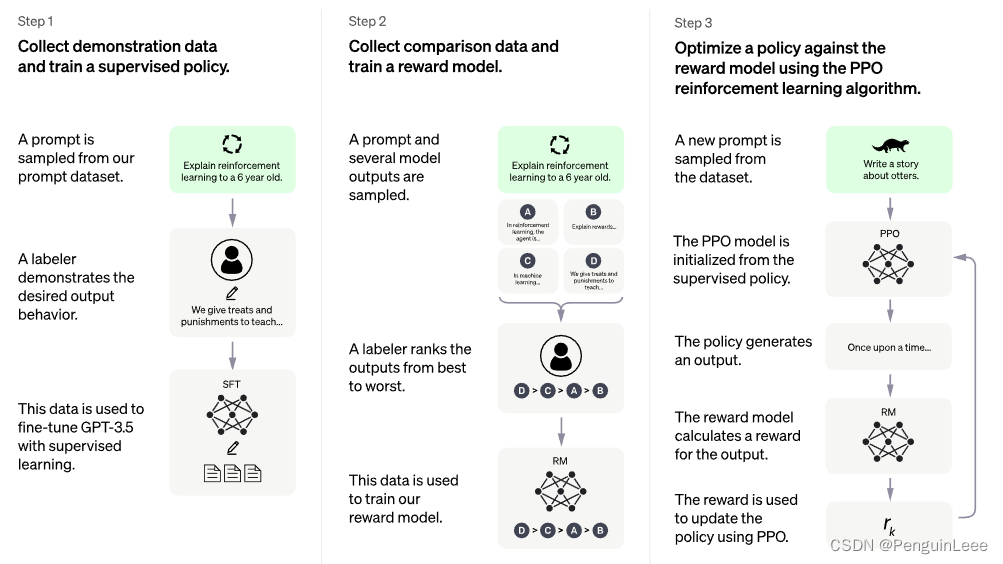
ChatGPT原理简明笔记
学习笔记,以李宏毅的视频讲解为主,chatGPT的官方博客作为补充。 自己在上古时期接触过人工智能相关技术,现在作为一个乐子来玩,错漏之处在所难免。 若有错误,欢迎各位神仙批评指正。 chatGPT的训练分为四个阶段&#x…

《论文阅读》Towards Emotional Support Dialog Systems
《论文阅读》Towards Emotional Support Dialog Systems 前言简介思路出发点相关知识区别EC、ER和ESCEmotional Support Conversation任务定义ESC框架数据集总结前言
你是否也对于理解论文存在困惑?
你是否也像我之前搜索论文解读,得到只是中文翻译的解读后感到失望?
小白…
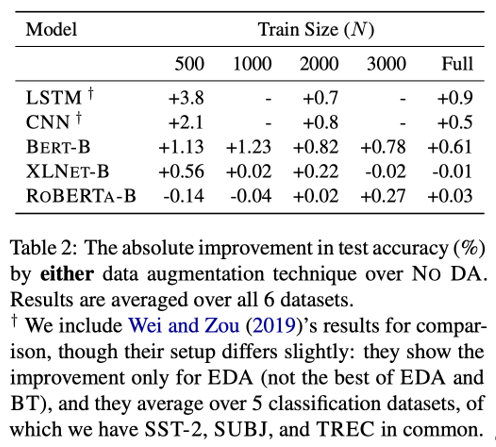
数据增广真有那么神奇吗?
作者:皮皮雷 来源:投稿 编辑:学姐 论文题目
How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
论文作者
S. Longpre, Y. Wang, and C. DuBois
论文发表于
2020 EMNLP findings 摘要
任务无关的数据增广…
提示词(prompt)工程指南(三):高级提示
到此为止,已经很明显完善提示有助于在不同任务上获得更好的结果。这就是提示工程的整体理念。
尽管那些例子很有趣,但在我们进入更高级的概念之前,让我们正式介绍一些概念。 完整的中文版本指南和更丰富的参考资料在 Github 和 Gitee 中&…

各种预训练模型的理论和调用方式大全
诸神缄默不语-个人CSDN博文目录
本文主要以模型被提出的时间为顺序,系统性介绍各种预训练模型的理论(尤其是相比之前工作的创新点)、调用方法和表现效果。
最近更新时间:2023.5.10 最早更新时间:2023.5.10
BertRobe…

【NLP+机器学习】实现对评论的情感倾向分析,预测,评估
前言
对文本的情感分析采用了两种思路——文本分类和文本聚类
有监督的学习无监督的学习训练集包括输入和由人工标注的输出(x,y)其训练集没有人为标注的输出(x)分类(classify)聚类(…

【文本聚类】三种聚类算法实现影评的情感分析(K-Means,Agglomerative,DBSCAN)
文本处理
from nltk.corpus import movie_reviews# ([...], pos)
# ([...], neg)
documents [(list(movie_reviews.words(fileid)), category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)]# 将documents「随机化」ÿ…

文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks 1. 文章简介2. 主要方法介绍3. 主要实验内容 1. Unsupervised STS2. Supervised STS3. Downsteam SentEval Evaluation4. Ablation Study 4. 结论 & 思考 文献链接&#x…

SolidUI 单独部署
1.首次安装准备事项
1.1 Linux 服务器
硬件要求
安装SolidUI 微服务1个,至少512M内存。每个微服务默认配置启动的jvm -Xmx 内存大小为 512M(内存不够的情况下,可以尝试调小至256/128M,内存足够情况下也可以调大)。 …

命名实体识别(NER)的发展历程
命名实体识别(Named Entity Recognition,NER)简单说就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。一般我们归为序列标注问题(sequence labeling problem)中的一种。与分类问题相比&#…

Toolformer:可以教会自己使用工具的语言模型
Toolformer:可以教会自己使用工具的语言模型 摘要Introduction现有大模型的局限处理办法本文的idea Approach样例化API调用执行API调用筛选API调用模型微调 实验局限 论文地址点这里
摘要
语言模型(LMs)呈现了令人深刻的仅使用少量的范例或…
微软亚研院:NLP趋势展望
趋势热点:值得关注的 NLP 技术
从最近的 NLP 研究中,我们认为有一些技术发展趋势值得关注,这里总结了五个方面:
热点一,预训练神经网络
如何学习更好的预训练的表示,在一段时间内继续成为研究的热点。
…
第N3周:调用Gensim库训练Word2Vec模型
目录 一、课题背景和开发环境二、准备工作1. 安装Gensim库2. 对原始语料分词 三、训练Word2Vec模型四、模型应用1.计算词汇相似度2. 找出不匹配的词汇3.计算词汇的词频 🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:…

NLP学习笔记(七) BERT简明介绍
大家好,我是半虹,这篇文章来讲 BERT\text{BERT}BERT (Bidirectional Encoder Representations from Transformers)
原始论文请戳这里 0 概述
从某种程度上来说,深度学习至关重要的一环就是表征学习,也就是学习如何得到数据的向…
NLP英文数据分析干货!!!——针对English分析模版
NLP英文数据分析一、全套英文预处理代码二、统计词频词云图分析统计词频词云图分析三、情感分析NLTK情感分析实战四、相似度分析(LDA、LSI、Tfidf)一、全套英文预处理代码
# 英文句子处理模块
from nltk.corpus import stopwords as pw
import sys
imp…
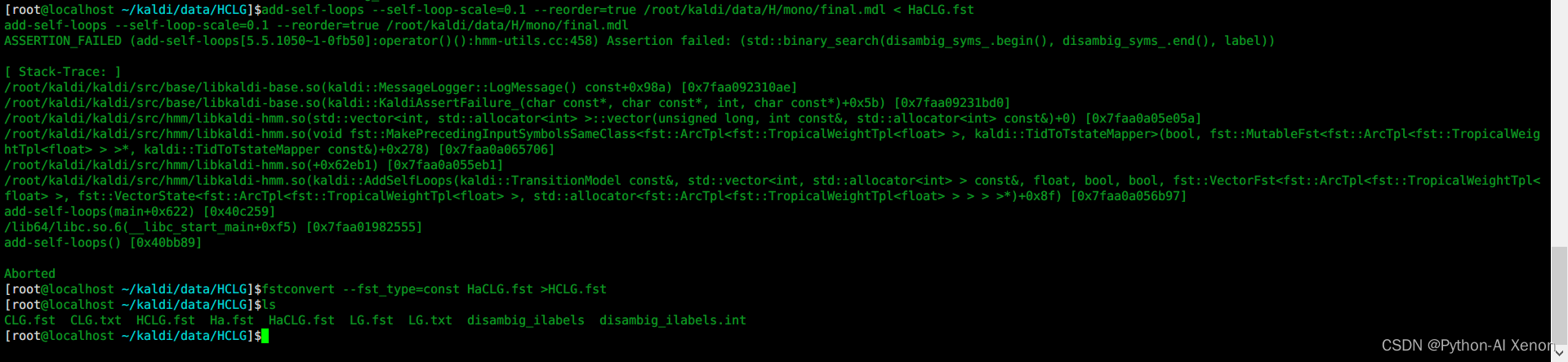
Kaldi语音识别技术(八) ----- 整合HCLG
Kaldi语音识别技术(八) ----- 整合HCLG 文章目录Kaldi语音识别技术(八) ----- 整合HCLGHCLG 概述组合LG.fst可视化 LG.fst组合CLG.fst可视化CLG.fst生成H.fst组合HCLG.fst生成HaCLG.fst生成HCLG.fstHCLG 概述
HCLG min(det(H o min(det(C o min(det(L o G)))))
将…

NLP中文数据分析干货!!!——针对Chinese分析模版、苏宁空调评论分析实战(提供数据)
NLP中文数据分析一、全套中文预处理代码去掉文本中多余的空格去除多余符号,保留指定中英文和数字繁体转简体分词去除停用词预处理封装二、统计词频词云图分析统计词频词云图分析三、情感分析SnowNLP情感分析实战四、主题分析LDA前数据预处理LDA主题模型五、实战演练…

《Not Enough Data? Deep Learning to the Rescue》论文笔记
引言
文本数据增强技术在小样本分类任务上,有助于模型效果的提升。已有的数据增强技术如EDA、Conditional BERT采用的是局部替换的方式,在预训练语言模型效果显著提升的背景下,作者试图采用GPT2,以文本生成的方式合成新样本&…

《Conditional BERT Contextual Augmentation》论文笔记
Conditional BERT Contextual Augmentation
直观来看,MLM 是一种非常好的“基于上下文”的数据增强方式(后面的实验结果也证明,直接使用Bert也可以取得较好的效果。), 但是在分类任务中,人工合成的数据不应…

《PERT: Pre-Training Bert With Pemuted Language Model》论文笔记
简介
作者提出,预训练模型大致可以分为两大类,自编码(AutoEncoder) 与自回归(AutoRegressive),自编码的典型代表是BERT, 自回归的典型代表是GPT。Bert预训练阶段采用 MLM NSP 预训…
向量数据库Chroma教程
引言
随着大模型的崛起,数据的海洋愈发浩渺无垠。受限于token的数量,无数的开发者们如同勇敢的航海家,开始在茫茫数据之海中探寻新的路径。他们选择了将浩如烟海的知识、新闻、文献、语料等,通过嵌入算法(embedding)的神秘力量,转化为向量数据,存储在神秘的Chroma向量…

ChatGLM-6B部署和微调实例
文章目录 前言一、ChatGLM-6B安装1.1 下载1.2 环境安装 二、ChatGLM-6B推理三、P-tuning 微调3.1微调数据集3.2微调训练3.3微调评估3.4 调用新的模型进行推理 总结 前言
ChatGLM-6B ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Mo…

Hardware-Aware-Transformers开源项目笔记
文章目录 Hardware-Aware-Transformers开源项目笔记开源项目背景知识nas进化算法进化算法代码示例 开源项目Evolutionary Search1 生成延迟的数据集2 训练延迟预测器3 使延时约束运行搜索算法4. 训练搜索得到的subTransformer5. 根据重训练后的submodel 得到BLEU精度值 代码结构…

LaWGPT安装和使用教程的复现版本【细节满满】
文章目录 前言一、下载和部署1.1 下载1.2 环境安装1.3 模型推理 总结 前言
LaWGPT 是一系列基于中文法律知识的开源大语言模型。该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练&am…

【论文精读】GPT2
摘要 在单一领域数据集上训练单一任务的模型是当前系统普遍缺乏泛化能力的主要原因,要想使用当前的架构构建出稳健的系统,可能需要多任务学习。但多任务需要多数据集,而继续扩大数据集和目标设计的规模是个难以处理的问题,所以只能…
pyhanlp安装和使用教程
文章目录 pyhanlp介绍 pyhanlp介绍
HanLP 是一个由中国开发者何晗(hankcs)于 2014 年开发的自然语言处理库,自发布之后,HanLP 不断更新迭代,进行了许多新功能和性能的优化,Github 上 Star 数量已超过 3w,其在主流自然…
大语言模型LLM中Transformer模型的调用过程与步骤
在LLM(Language Model)中,Transformer是一种用来处理自然语言任务的模型架构。下面是Transformer模型中的调用过程和步骤的简要介绍:
数据预处理:将原始文本转换为模型可以理解的数字形式。这通常包括分词、编码和填充…
LTP/pyltp安装和使用教程
文章目录 LTP介绍分句分词加载外部词典个性化分词 词性标注命名实体识别NER依存句法分析语义角色标注 LTP介绍
官网:https://ltp.ai/ 下载可以到官网的下载专区:https://ltp.ai/download.html 语言技术平台(Language Technology Platform&am…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.01.01-2024.01.10
1.Pre-trained Large Language Models for Financial Sentiment Analysis 标题:用于金融情感分析的预训练大型语言模型 author:Wei Luo, Dihong Gong date Time:2024-01-10 paper pdf:http://arxiv.org/pdf/2401.05215v1
摘要: 金融情感分析是指将金融文本内容划分…
NLP_文本数据增强_5(代码示例)
学习目标
了解文本数据增强的作用. 掌握实现常见的文本数据增强的具体方法. 常见的文本数据增强方法: 回译数据增强法
1 回译数据增强法 回译数据增强目前是文本数据增强方面效果较好的增强方法, 一般基于google翻译接口, 将文本数据翻译成另外一种语言(一般选择小语种),之后…

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…
【LLM】Advanced rag techniques: an illustrated overview
note 文章目录 noteAdvanced rag techniques: an illustrated overview基础RAG高级RAG分块和向量化(Chunking & Vectorisation)搜索索引(Search Index)1. 向量存储索引(Vector Store Index)2. 多层索引(Hierarchical Indices)3. 假设问题和HyDE(Hypo…

Text-to-SQL任务中的思维链(Chain-of-thought)探索
导语
在探索LLM在解决Text-to-SQL任务中的潜能时,本文提出了一种创新的‘问题分解’Prompt格式,结合每个子问题的表列信息,实现了与顶尖微调模型(RASATPICARD)相媲美的性能。
会议:EMNLP 2023链接&#x…
【AI】小白入门笔记
前言 2024年,愿新年胜旧年!作为AI世界的小白,今天先来从一些概念讲起,希望路过的朋友们多多指教!
正文
AI (人工智能) 提起AI, 大家可能会想起各种机器人,移动手机的“Siri”,"小爱同学", 是语…
NLP自然语言处理原理应用讲解
自然语言处理(NLP)是人工智能领域中研究如何让计算机理解和处理人类自然语言的一门学科。它的应用广泛,例如在搜索引擎、聊天机器人、机器翻译等领域中都发挥了重要的作用。
NLP的基本原理是通过对大量的语料库进行训练,让计算机…
NLP深入学习(七):词向量
文章目录 0. 引言1. 什么是词向量2. Word2Vec2.1 介绍2.2 例子 3. 参考 0. 引言
前情提要: 《NLP深入学习(一):jieba 工具包介绍》 《NLP深入学习(二):nltk 工具包介绍》 《NLP深入学习&#x…
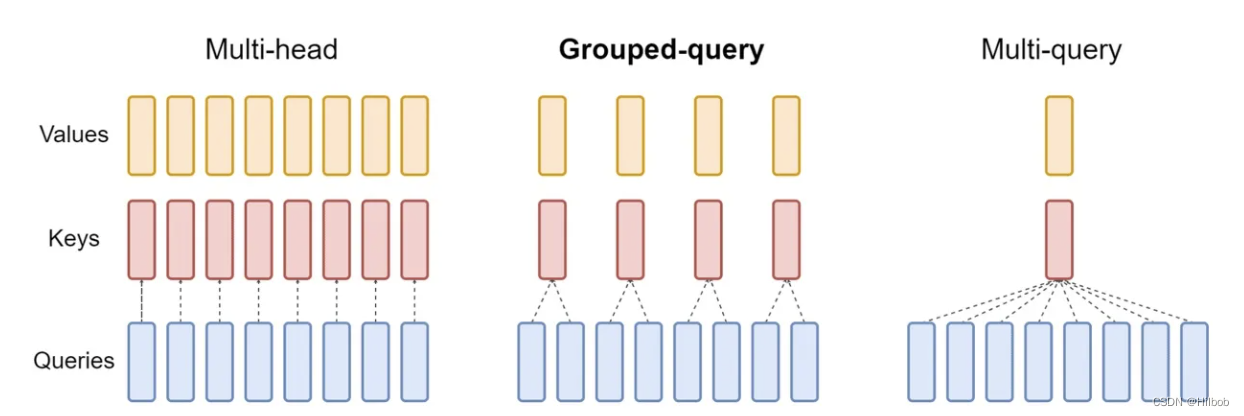
【NLP】MHA、MQA、GQA机制的区别
Note
LLama2的注意力机制使用了GQA。三种机制的图如下:
MHA机制(Multi-head Attention)
MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 V…
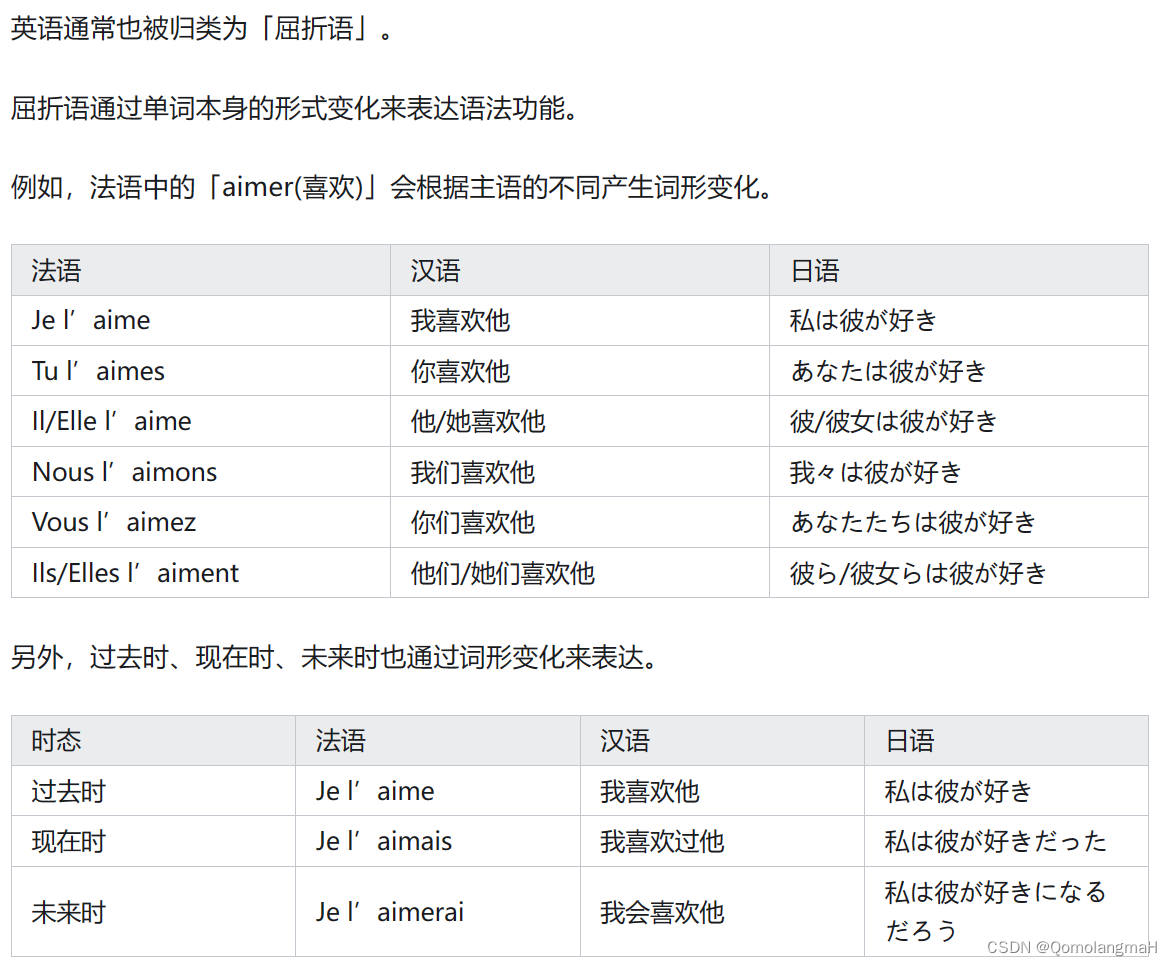
【自然语言处理】统计中文分词技术(一):1、分词与频度统计
文章目录 一、词与分词1、词 vs 词素2、世界语言分类 二、分词的原因与基本原因1、为什么要分词2、分词规范3、分词的主要难点-切分歧义如何排除切分歧义利用词法信息利用句法信息利用语义信息利用语用、语境信息 4、分词的主要难点-未登录词未登录词如何识别未登录词 三、分词…
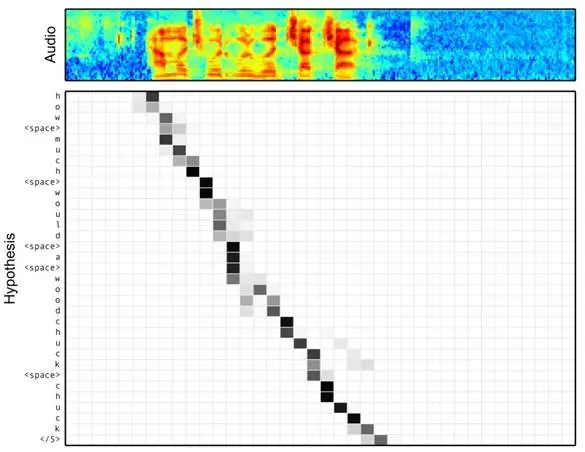
深度学习中的Attention机制
深度学习中的Attention机制 一、Encoder-Decoder框架二、Attention机制(1) Soft Attention模型(2) Attention机制的本质思想(3) Self Attention模型(4) Attention机制的应用 一、Encoder-Decoder框架
Encoder-Decoder框架是一种深度学习领域的研究模式,应用场景异常…
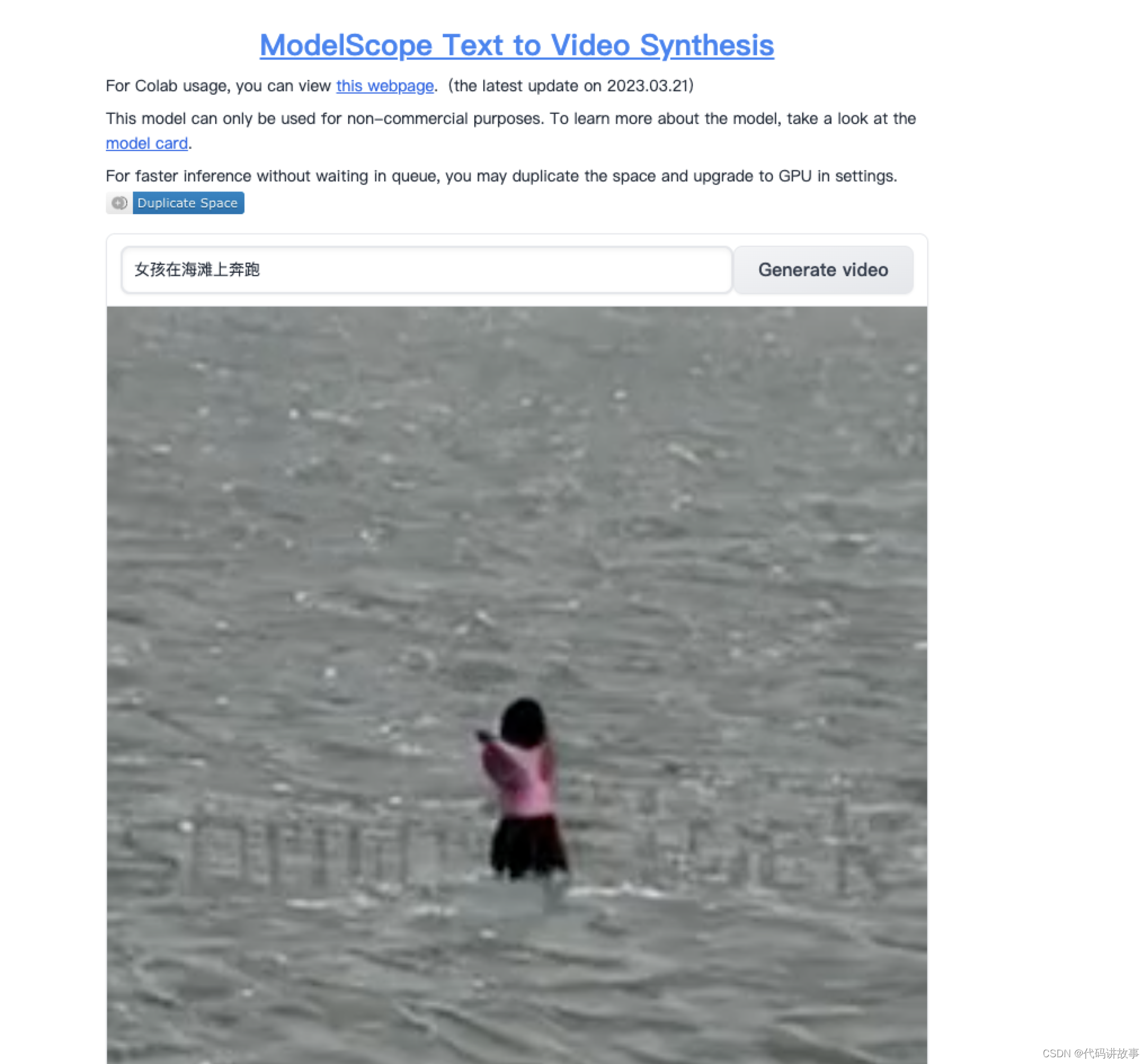
免费使用支持离线部署使用的 txt2video 文本生成视频大模型(Text-to-Video-Synthesis Model)
免费使用支持离线部署使用的 txt2video 文本生成视频大模型(Text-to-Video-Synthesis Model)。
文本生成视频大模型(Text-to-Video-Synthesis Model)是一种基于深度学习技术的人工智能模型,它可以将自然语言文本描述转换为相应的视频。即通过输入文本描述ÿ…
2024 年学习 AI 路线图
2024 年学习 AI 路线图 一、数学二、工具2.1 Python2.2 PyTorch 三、机器学习3.1 从头开始编写3.2 参加比赛3.3 做副业项目3.4 部署模型3.5 补充材料 四、深度学习4.1 fast.ai4.2 多参加一些比赛4.3 论文实现4.4 计算机视觉4.5 强化学习4.6 自然语言处理 五、大型语言模型5.1 观…
解析旅游者心声:用PySpark和SnowNLP揭秘景区评论的情感秘密
简介:
在本篇博客中,我们将探讨如何利用PySpark和SnowNLP这两个强大的工具来分析大规模的旅游评论数据。通过结合携程和去哪儿的数据作为示例,我们将探索如何从海量的评论中提取有价值的情感信息和洞察。PySpark作为一种分布式计算框架,能够处理大规模的数据集,为我们提供…
LLM--如何使用SentenceTransformer将文本向量化
将文本向量化是自然语言处理(NLP)中的一项关键步骤,其主要目的是将原本难以直接被计算机理解的自然语言文本转换成数值形式的向量,以便于后续的机器学习算法和深度学习模型进行处理、分析和建模
1. 如何安装SentenceTransformer
安装参考: https://pypi.org/project/sen…
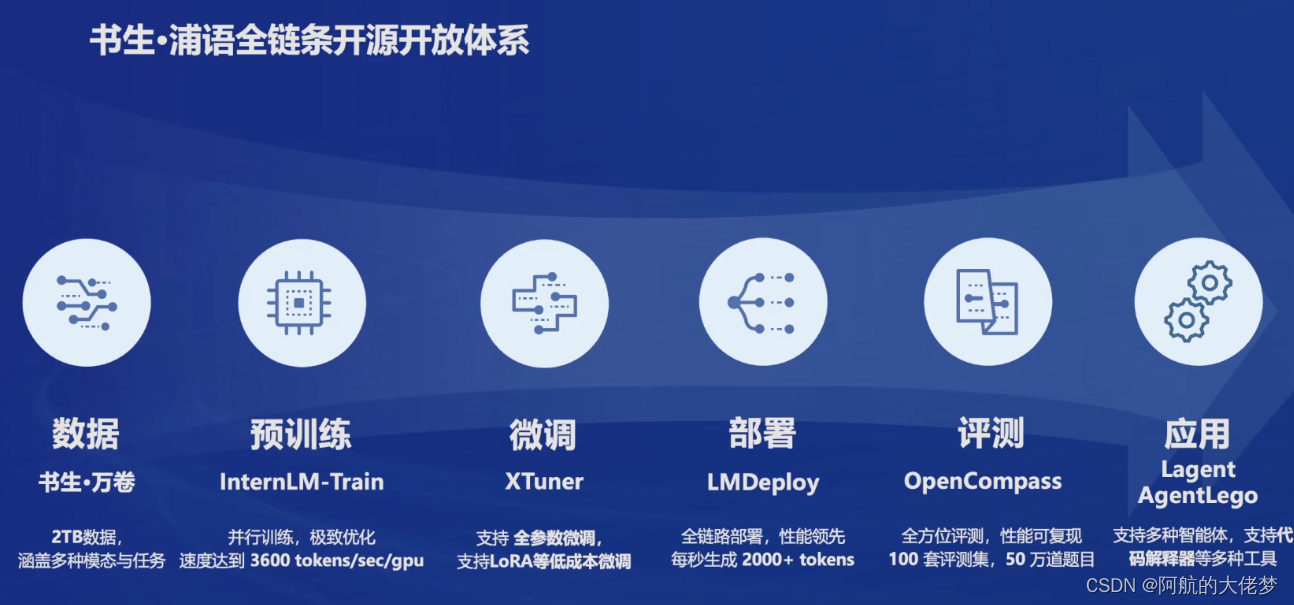
书生·浦语大模型实战营 | 第1次学习笔记
前言
书生浦语大模型应用实战营 第二期正在开营,欢迎大家来学习。(参与链接:https://mp.weixin.qq.com/s/YYSr3re6IduLJCAh-jgZqghttps://mp.weixin.qq.com/s/YYSr3re6IduLJCAh-jgZqg)
第一堂课的视频链接:https://m…

REPLUG:检索增强的黑盒语言模型
论文题目:REPLUG: Retrieval-Augmented Black-Box Language Models 论文日期:2023/05/24 论文地址:https://arxiv.org/abs/2301.12652 文章目录 Abstract1. Introduction2. Background and Related Work2.1 Black-box Language Model…
1.8 NLP自然语言处理
NLP自然语言处理
更多内容,请关注: github:https://github.com/gotonote/Autopilot-Notes.git
一、简介
seq2seq(Sequence to Sequence)是一种输入不定长序列,产生不定长序列的模型,典型的处理任务是机器翻译&#…
RAFT: Adapting Language Model to Domain Specific RAG
预备知识
RAG介绍一文搞懂大模型RAG应用(附实践案例) - 知乎 (zhihu.com)
RAG的核心理解为“检索生成”
检索:者主要是利用向量数据库的高效存储和检索能力,召回目标知识;
生成:利用大模型和Prompt工程…
自然语言处理Gensim入门:建模与模型保存
文章目录 自然语言处理Gensim入门:建模与模型保存关于gensim基础知识1. 模块导入2. 内部变量定义3. 主函数入口 (if __name__ __main__:)4. 加载语料库映射5. 加载和预处理语料库6. 根据方法参数选择模型训练方式7. 保存模型和变换后的语料8.代码 自然语言处理Gens…
AI:141-利用自然语言处理改进医疗信息提取与分类
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~
🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…

NLP-词向量、Word2vec
Word2vec
Skip-gram算法的核心部分 我们做什么来计算一个词在中心词的上下文中出现的概率?
似然函数 词已知,它的上下文单词的概率 相乘。 然后所有中心词的这个相乘数 再全部相乘,希望得到最大。 目标函数(代价函数࿰…
LLM int4算法autoround v0.1即将发布,欢迎试用
概述
AutoRound(https://github.com/intel/auto-round)实现了出色的量化性能,在W4G128上多数场景中接近无损压缩,适用于包括gemma-7B、Mistral-7b、Mixtral-8x7B-v0.1、Mixtral-8x7B-Instruct-v0.1、Phi2、LLAMA2等一系列流行模型…
spaCy NLP库的模型的下载、安装和使用说明书
文章目录 1 前言2 安装3 模型命名规范3.1 模型版本控制3.2 支持对旧版本的兼容 4 下载模型5 加载和使用模型6 手动下载和安装7 spaCy v1.x模型的命名规范8 问题和错误报告 1 前言
explosion网址:https://explosion.ai/ spaCy下载网址:https://explosion…

NLP - 神经网络与反向传播
使用神经网络进行命名实体识别(二值词窗分类)
根据上下文窗口 建立词向量 通过一个神经网络层,通过一个逻辑分类器,得到这个概率是属于特定实体词的预测概率。 另一个分类器来比较说明 这个词是哪个实体类型(比较概率…

智能咖啡厅助手:人形机器人 +融合大模型,行为驱动的智能咖啡厅机器人(机器人大模型与具身智能挑战赛)
智能咖啡厅助手:人形机器人 融合大模型,行为驱动的智能咖啡厅机器人(机器人大模型与具身智能挑战赛)
“机器人大模型与具身智能挑战赛”的参赛作品。的目标是结合前沿的大模型技术和具身智能技术,开发能在模拟的咖啡厅场景中承担服务员角色并…
案例介绍:汽车售后服务网络构建与信息抽取技术应用(开源)
一、引言
在当今竞争激烈的汽车行业中,售后服务的质量已成为品牌成功的关键因素之一。作为一位经验丰富的项目经理,我曾参与构建一个全面的汽车售后服务网络,旨在为客户提供无缝的维修、保养和配件更换服务。这个项目的核心目标是通过高效的…
【自然语言处理】NLP入门(三):1、正则表达式与Python中的实现(3):字符转义符及进制转换
文章目录 一、前言二、正则表达式与Python中的实现1.字符串构造2. 字符串截取3. 字符串格式化输出4. 字符转义符a. 常用字符转义符续行符换行符制表符双引号单引号反斜杠符号回车符退格符 b. ASCII编码转义字符进制转换2 进制8 进制10 进制16 进制进制转换函数 c. Unicode字符\…

【NLP】小结:fasttext模型中的层次softmax策略
一. fasttext介绍 1. fasttext的作用
作为NLP工程领域常用的工具包, fasttext有两大作用:
进行文本分类训练词向量
2. fasttext的优势
在保持较高精度的前提下, 快速的进行训练和预测是fasttext的最大优势。 fasttext有上述优势的原因可以简单总结为以下几点:
fasttext工具…
【GPT概念04】仅解码器(only decode)模型的解码策略
一、说明 在我之前的博客中,我们研究了关于生成式预训练转换器的整个概述,以及一篇关于生成式预训练转换器(GPT)的博客——预训练、微调和不同的用例应用。现在让我们看看所有仅解码器模型的解码策略是什么。 二、解码策略 在之前…
Python实现视频转音频、音频转文本加文本实体识别
文章目录 概述必备第三方库视频转音频音频转文字完整代码命名实体识别NER注意点概述
本教程希望可以识别出目前活跃的视频平台(例如抖音、快手等)中视频文案中蕴含的实体信息,首先有两条技术路径: 直接提取视频帧,之后实现逐帧的字幕识别,最后合并为视频文案。 优点:准…
Transformer代码从零解读【Pytorch官方版本】
文章目录 1、Transformer大致有3大应用2、Transformer的整体结构图3、如何处理batch-size句子长度不一致问题4、MultiHeadAttention(多头注意力机制)5、前馈神经网络6、Encoder中的输入masked7、完整代码补充知识: 1、Transformer大致有3大应…
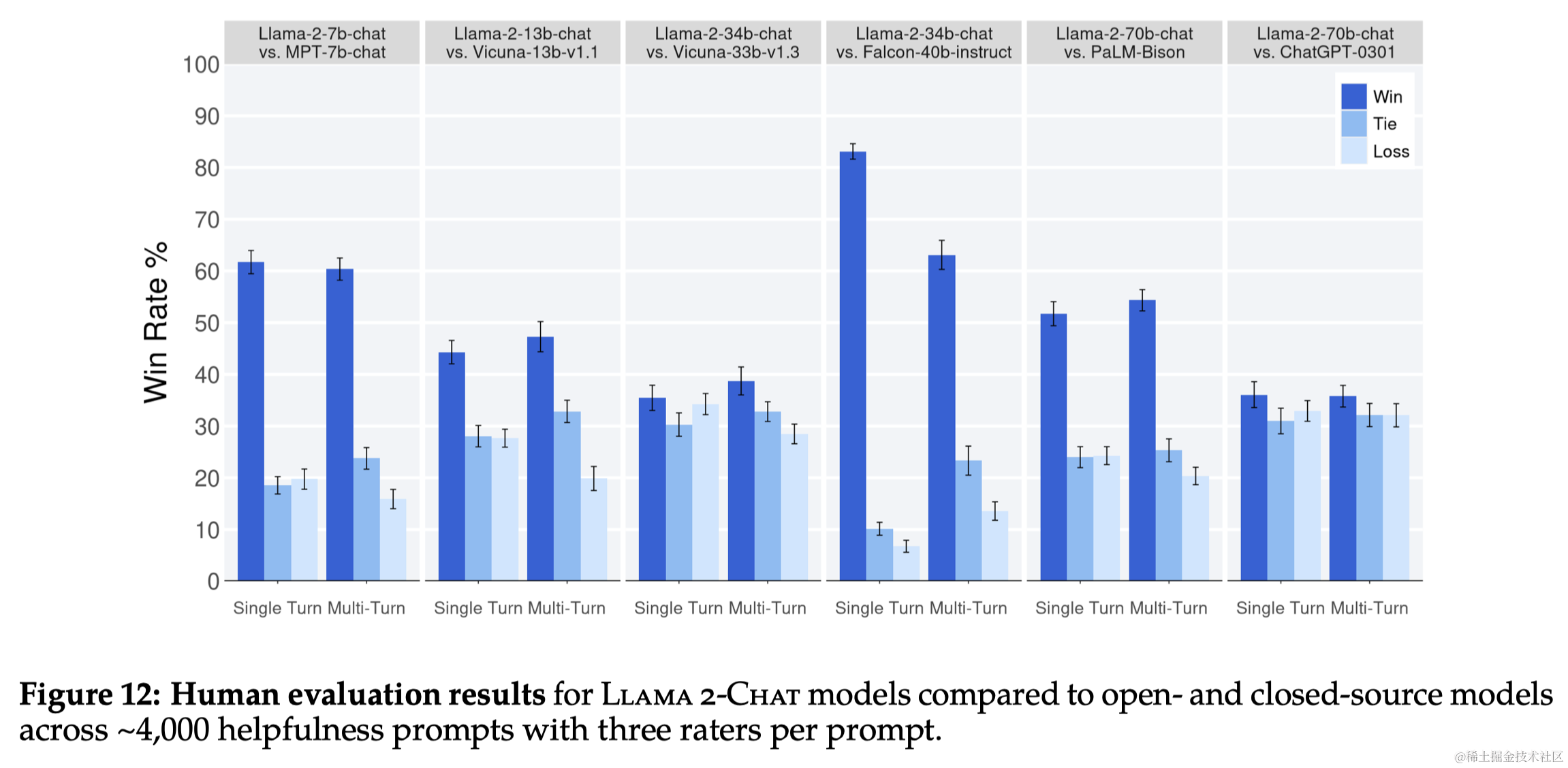
论文笔记:Llama 2: Open Foundation and Fine-Tuned Chat Models
导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMsÿ…
【NLP02-文本处理的基本方法】
文本处理的基本方法
1、文本预处理
1.1、什么是分词
就是将连续的字序列按照一定的规范重新组合成词序列的过程
1.2、分词的作用
词作为语言语义理解最小单位,是人类理解文本语言的基础
1.3、流行中文词jieba
import jieba
content "公信处女干事每月经…
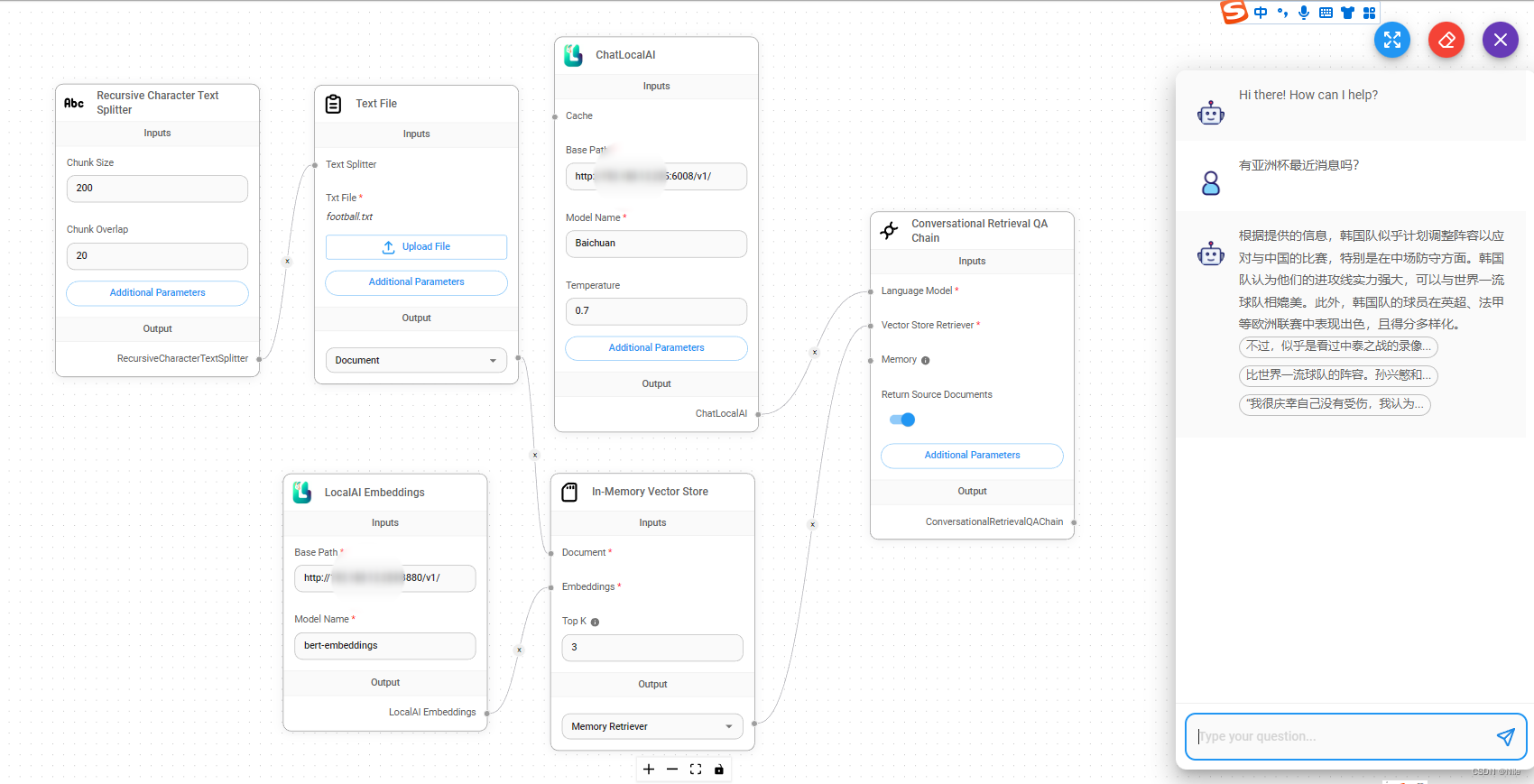
Flowise+LocalAI部署--Agent应用
背景
概念
Flowise
Flowise 是一个开源的用户界面可视化工具,它允许用户通过拖放的方式来构建自定义的大型语言模型(LLM)流程。 Flowise基于LangChain.js,是一个非常先进的图形用户界面,用于开发基于LLM的应用程序。…

2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程…
【NLP03-新闻主题分类任务】
新闻主题分类任务
背景
以一段新闻报道中的文本描述内容为输入,使用模型帮助我们判断它最优可能属于哪一种类型的新闻,这是典型的文本分类问题,这里假定每种类型是互斥的,即文本描述有且只有一种类型
新闻主题分类数据
#通过t…
【NLP5-RNN模型、LSTM模型和GRU模型】
RNN模型、LSTM模型和GRU模型
1、什么是RNN模型
RNN(Recurrent Neural Network)中文称为循环神经网络,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出
RNN的循环机制使模…
深入了解前馈网络、CNN、RNN 和 Hugging Face 的 Transformer 技术!
一、说明 本篇在此对自然语言模型做一个简短总结,从CNN\RNN\变形金刚,和抱脸的变形金刚库说起。 二、基本前馈神经网络: 让我们分解一个基本的前馈神经网络,也称为多层感知器(MLP)。此代码示例将࿱…

《How to Fine-Tune BERT for Text Classification》论文笔记
方法论
作者提出三种FineTune Bert的方法:1)直接使用下游目标数据集进行FineTune;2)先在目标领域上进一步Pretraining Bert, 再利用目标数据集FineTune; 3)与方法2类似,但加入了Mul…
低资源场景下的命名实体识别
Overview
低资源下的命名实体识别主要分为两个方面,一种是in-domain下的N-way-K-shot类型的少样本,一种是cross-domain下现在资源丰富的sourc-domain上进行微调,之后再迁移到低资源的target-domain进一步微调。
基于prompt的方法在少样本分…

使用NLP库textblob进行情感分析-红楼梦评论
最近做了一个分析国外读者对红楼梦评价的小项目。这部分是使用textblob库对评论进行情感分析,得到情感值,并且进行分类,生成词云。 生成直方图、条形图的数据分析过程见我的这篇文章
读入的数据是这样的格式。包含两行,一行评论&…
【ChatGPT】前世今生,真的那么强大吗?NLP技术不断成熟. || 附:【深度学习】在PyTorch中使用LSTM进行新冠病例预测
近期,一款名为ChatGPT的智能聊天机器人 火爆全球,它究竟是什么?它会对哪些行业产生冲击?对此,我整理了一些资料,简要介绍ChatGPT的——前世今生。 此外,新冠终于离我们远去,大家的生活也回到正轨。使用LSTM模型对新冠病例进行预测拟合,看一下它曾经的“爆发”…我们所…

nlp中文本预处理技术
自然语言处理NLP(Natural Language Processing),就是使用计算机对语言文字进行处理的相关技术。本文主要是总结一下中、英文的常用的文本预处技术。 文本分析的流程如下:
一、中文文本分析流程
1,中文文本处理的特点…
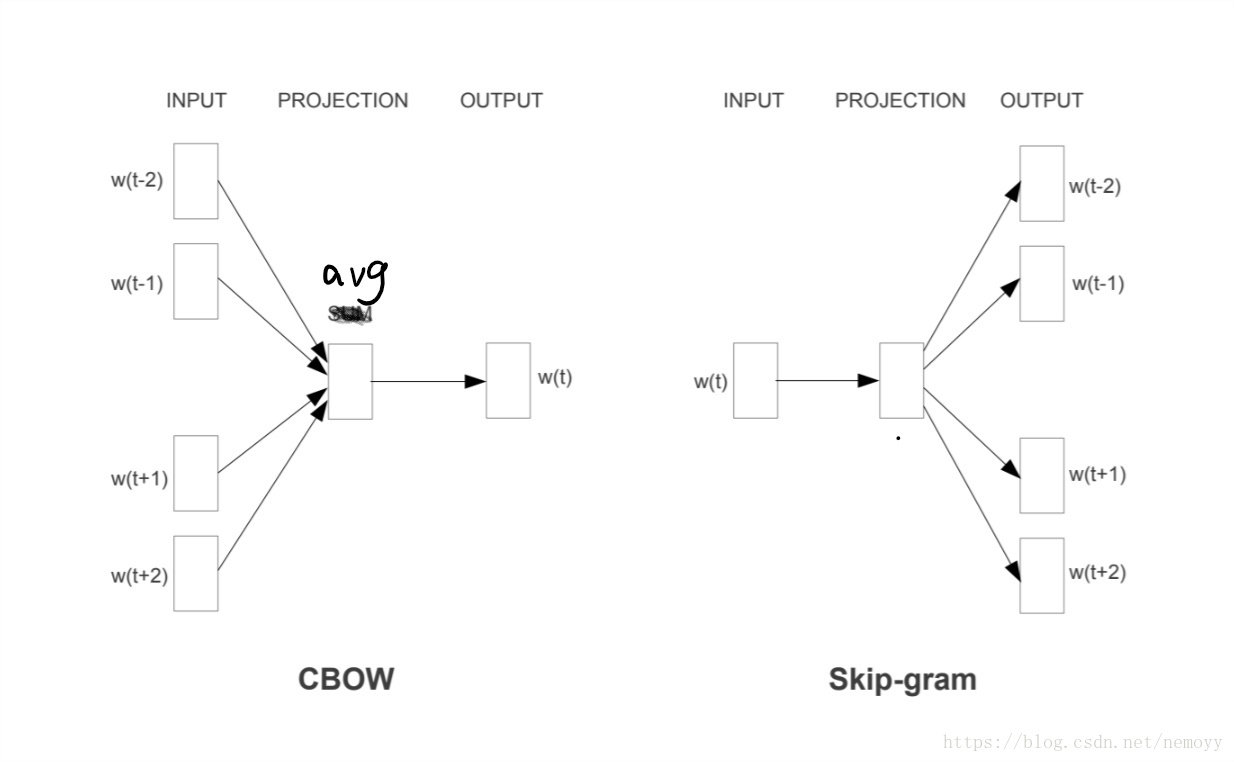
word2vec: 理解nnlm, cbow, skip-gram
word2vec 论文笔记
1 word rep
怎么表示词的意思? 传统的想法有查字典. 近义词,缺点:主观,费人力, 难记算相似性 one-hot 缺点:维度灾难,正交,无法计算similarity. 那么,通过借鉴近义词,学习将similarity编码到词向量中去.
1.1 one-hot
n-gram language model见我之前写…
Re45:读论文 GPT-1 Improving Language Understanding by Generative Pre-Training
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文全名:Improving Language Understanding by Generative Pre-Training 论文下载地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
本文是2018年OpenAI的工作,…
李沐 深度学习论文 解读 alexnet 笔记
李沐b站视频链接9年后重读深度学习奠基作之一:AlexNet【论文精读】_哔哩哔哩_bilibili-https://www.bilibili.com/video/BV1ih411J7Kz?spm_id_from333.999.0.0
主要记录行业大专家如何看待细分领域,跨领域工作的 1.alexnet 论文只是说明了效果很好 但是…

文本分类识别系统1-keras版本
数据中包含了10个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共6万多条评论数据,数据有两个字段,其中cat字段表示类别,review表示用户的评价信息,数据总量为62774,且评价内容全部为中文。还有label,用0、1表示评论的积极和消极,这里用不到…
glove_python安装(避免编译错误)
直接采用pip install glove_python时出现了编译错误,因此采用其他方法进行安装
cd /tmp \
&& curl -o glove_python.zip -OL https://github.com/maciejkula/glove-python/archive/master.zip \
&& unzip glove_python.zip \
&& rm -f glo…
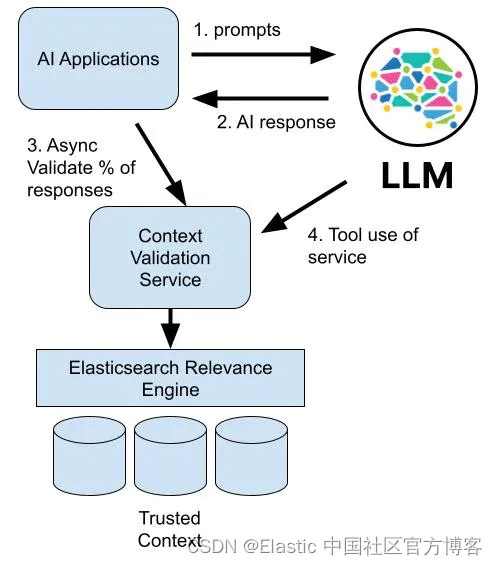
检索与毒害 —— 对抗人工智能供应链攻击
作者:DAVE ERICKSON
在这篇文章中,了解人工智能大语言模型的供应链漏洞,以及如何利用搜索引擎的人工智能检索技术来对抗人工智能的错误信息和故意篡改。 虽然对于人工智能研究人员来说可能是新鲜事,但供应链攻击对于网络安全世界…

如何只用bert夺冠之对比学习代码解读
有监督对比学习:Supervised Contrastive Learning: https://zhuanlan.zhihu.com/p/136332151
1. 自监督对比学习
一句话总结:不使用label数据,通过数据增强构造样本,使特征提取器提取的特征在增强样本和原始样本的距离更近&…
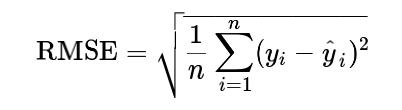
kaggle近三年NLP比赛top方案汇总及新赛推荐
NLP的赛题任务主要有文本分类、情感分析、关系抽取、文本匹配、阅读理解、问答系统等,自Google开发的NLP处理模型BERT被广泛应用后,目前解决NLP任务的首选方案就是深度学习方法(textCNN、LSTM、GRU、BiLSTM、Attention等)…

《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》论文笔记
ELECTRA 提出“替换词检测” 预训练任务,在计算损失时,考虑全部输入, 而非 MLM 中15%的输入;另一方面解决了[MASK] 在预训练与Fine-Tuning 阶段不一致的问题。
替换词检测
替换词检测任务采用如下结构: 生成器理论…

【自然语言处理】NLP学习及实践记录 | part 01 自然语言实现中文分词|句法分析
项目需要,所以学习一下,自然语言处理,主要是【知识库构建】、【自动摘要生成】、【个性推荐算法】、【聊天机器人|问答系统】这几个部分的应用。
有哪些部分在我们学习NLP过程中提的比较多的呢?这是老师在讲课开始提的一个问题&a…

《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》论文笔记
EDA
作者提出四种简洁有效的文本数据增强方法,可以提升分类任务的效果,称为EDA(Easy Data Augmentation),四种方法如下:
同义词替换(Synonym Replacement):从输入中随机…
![[论文阅读] SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL](https://img-blog.csdnimg.cn/f224fb6c3b06424b9bc3cc0360bf13bc.png#pic_center)
[论文阅读] SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL
“SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL” 是一篇 text2sql 领域的论文,发布于 NeurIPS 2021。
原文链接:https://arxiv.org/abs/2111.00653 项目代码链接:https://github.com/DMIRLAB-Group/SADGA
总体…
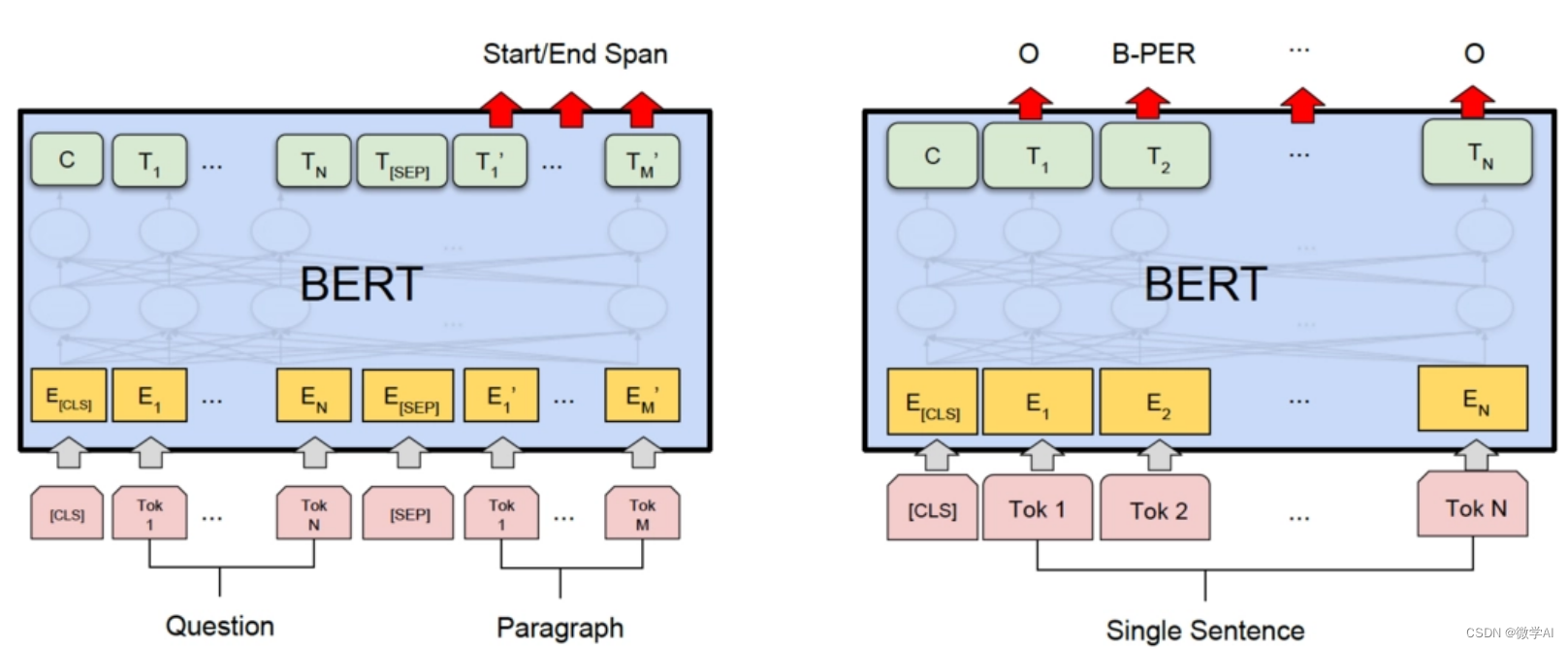
人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式
大家好,我是微学AI,今天给大家介绍一下人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式。句子嵌入是将句子映射到一个固定维度的向量表示形式,它在自然语言处理(NLP)中有着广泛的应用。通过将句子转化为向量…
【pytorch】Dataloader学习笔记
总结
Pytorch中加载数据集的核心类为torch.utils.data.Dataloder,Dataloader中最核心的参数为dataset,表示需加载的源数据集。dataset有两种类型:“map-style dataset” 与 “iterable-style dataset”, map-style dataset可以理…

【自然语言处理】不同策略的主题建模方法比较
不同策略的主题建模方法比较 本文将介绍利用 LSA、pLSA、LDA、NMF、BERTopic、Top2Vec 这六种策略进行主题建模之间的比较。
1.简介
在自然语言处理(NLP)中,主题建模一词包含了一系列的统计和深度学习技术,用于寻找文档集中的隐…

孤注一掷——基于文心Ernie-3.0大模型的影评情感分析
孤注一掷——基于文心Ernie-3.0大模型的影评情感分析 文章目录 孤注一掷——基于文心Ernie-3.0大模型的影评情感分析写在前面一、数据直观可视化1.1 各评价所占人数1.2 词云可视化 二、数据处理2.1 清洗数据2.2 划分数据集2.3 加载数据2.4 展示数据 三、RNIE 3.0文心大模型3.1 …
前沿探索|关于 AIGC 的「幻觉/梦游」问题
AI语言模型的梦游是指模型产生内容与真实世界不符或者是毫无意义的情况。这种情况主要是由于语言模型缺乏真实世界的知识和语言的含义,导致模型难以理解和表达现实世界的概念和信息。这种情况在现代自然语言处理中普遍存在,尤其是在开放式生成领域的问题…

Llama模型结构解析(源码阅读)
目录 1. LlamaModel整体结构流程图2. LlamaRMSNorm3. LlamaMLP4. LlamaRotaryEmbedding 参考资料: https://zhuanlan.zhihu.com/p/636784644 https://spaces.ac.cn/archives/8265 ——《Transformer升级之路:2、博采众长的旋转式位置编码》
前言&#x…
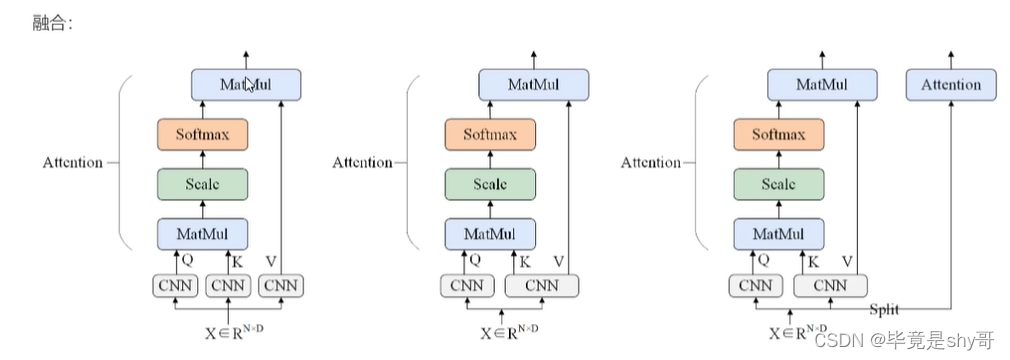

优雅组合,高效交互:Gradio Combining Interfaces模块解析
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…
举例说明自然语言处理(NLP)技术
自然语言处理(NLP)技术是一种人工智能领域的技术,用于处理自然语言文本或语音信号。下面是一些自然语言处理技术的例子: 机器翻译:机器翻译是一种自然语言处理的技术,它可以将一种语言的文本翻译成另一种语…

基于Django+node.js+MySQL+杰卡德相似系数智能新闻推荐系统——机器学习算法应用(含Python全部工程源码)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境node.js前端环境MySQL数据库 模块实现1. 数据预处理2. 热度值计算3. 相似度计算1)新闻分词处理2)计算相似度 4. 新闻统计5. API接口开发6. 前端界面实现1)运行逻辑2࿰…

【论文学习】RoBERTa
目录摘要训练过程分析摘要
RoBERTa(A Robustly Optimized BERT Pretraining Approach)基本与BERT一致,但在以下方面做了一些细节调整:1)在更多数据上,以更大batch_size,训练更长时间࿱…
【论文学习】RoBERTa
目录摘要训练过程分析摘要
RoBERTa(A Robustly Optimized BERT Pretraining Approach)基本与BERT一致,但在以下方面做了一些细节调整:1)在更多数据上,以更大batch_size,训练更长时间࿱…

【Python装饰器】functools.wraps函数保留被装饰函数的元信息
前言
装饰器一般被用于修饰函数,为被修饰的函数增添某些功能,其输入一般为函数,输出为同一个函数,或者另一不同的函数。除注册装饰器外,大多数装饰器会返回与被装饰函数不同的函数对象。另一方面,由于装饰…

【AI视野·今日NLP 自然语言处理论文速览 第三十六期】Wed, 20 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 20 Sep 2023 Totally 64 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
SlimPajama-DC: Understanding Data Combinations for LLM Training Authors Zhiqiang Shen, Tianhua Tao, Li…
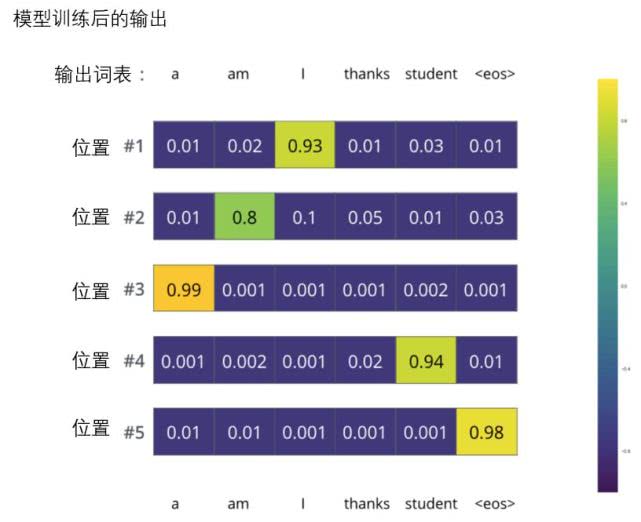
图解Transformer(完整版)
作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/86533005
审校:百度NLP、龙心尘 翻译:张驰、毅航、Conrad 原作者:Jay Alammar 原链接:https://jala…

NLP系列(6)_从NLP反作弊技术看马蜂窝注水事件
作者: 龙心尘 时间:2018年11月 出处:https://blog.csdn.net/longxinchen_ml/article/details/84205459
按:本文基于网易云课堂公开课分享内容整理补充完成。感谢志愿者july同学的贡献。
10月21日,朋友圈被一篇名为《…

【小沐学NLP】Python使用NLTK库的入门教程
文章目录 1、简介2、安装2.1 安装nltk库2.2 安装nltk语料库 3、测试3.1 分句分词3.2 停用词过滤3.3 词干提取3.4 词形/词干还原3.5 同义词与反义词3.6 语义相关性3.7 词性标注3.8 命名实体识别3.9 Text对象3.10 文本分类3.11 其他分类器3.12 数据清洗 结语 1、简介
NLTK - 自然…

【AI视野·今日NLP 自然语言处理论文速览 第四十二期】Wed, 27 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 27 Sep 2023 Totally 50 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models Authors Mert …
百度开源NLP工具LAC
工具介绍
LAC全称Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。该工具具有以下特点与优势: 效果好:通过深度学习模型联合学习分词、词性标注、专名识…

Jieba分词斗罗大陆
Jieba分词斗罗大陆
1.相关包导入
import jieba
import numpy as np
import pandas as pd2.斗罗大陆词库导入
dldlck pd.read_csv(F:\\cqie3.2\\NLP\\斗罗大陆词 库.txt,encodinggbk)
Dldlck3.斗罗大陆文本导入
with open(F:\\cqie3.2\\NLP\\斗罗大陆.txt,encodingutf-8) …
整理了197个经典SOTA模型,涵盖图像分类、目标检测、推荐系统等13个方向
今天来帮大家回顾一下计算机视觉、自然语言处理等热门研究领域的197个经典SOTA模型,涵盖了图像分类、图像生成、文本分类、强化学习、目标检测、推荐系统、语音识别等13个细分方向。建议大家收藏了慢慢看,下一篇顶会的idea这就来了~
由于整理的SOTA模型…

【AI视野·今日NLP 自然语言处理论文速览 第四十七期】Wed, 4 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 4 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Contrastive Post-training Large Language Models on Data Curriculum Authors Canwen Xu, Corby Rosset, Luc…
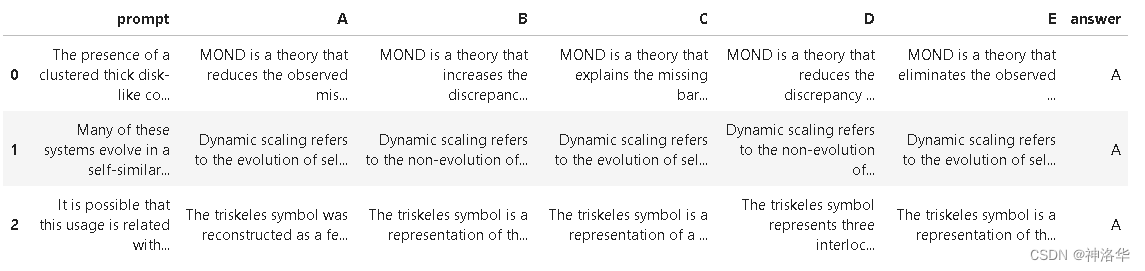
Kaggle - LLM Science Exam(二):Open Book QAdebertav3-large详解
文章目录 前言:优秀notebook介绍三、Open Book Q&A3.1 概述3.2 安装依赖,导入数据3.3 数据预处理3.3.1 处理prompt3.3.2 处理wiki数据 3.4 使用faiss搜索获取匹配的Prompt-Sentence Pairs3.5 查看context结果并保存3.6 推理3.6.1 加载测试集3.6.2 定…
【论文解读】The Power of Scale for Parameter-Efficient Prompt Tuning
一.介绍
1.1 promote tuning 和 prefix tuning 的关系
“前缀调优”的简化版
1.2 大致实现
冻结了整个预训练模型,并且只允许每个下游任务附加k个可调令牌到输入文本。这种“软提示”是端到端训练的,可以压缩来自完整标记数据集的信号,使…

文献阅读:AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
文献阅读:AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators 1. 文章简介2. 方法介绍3. 实验考察 1. 实验结果2. 消解实验3. Consistency & Stability 4. 结论 & 思考 文献链接:https://arxiv.org/abs/2303.16854
…
TextRank 算法 关键词提取
参考论文:Rada Mihalcea《TextRank:Bring Order into texts》。
TextRank将文本中的语法单元视作图中的节点,如果两个语法单元存在一定语法关系(例如共现),则这两个语法单元在图中就会有一条边相互连接&am…
【小沐学NLP】AI辅助编程工具汇总
文章目录 1、简介2、国内2.1 aiXcoder2.1.1 工具特点2.1.2 部署方式2.1.3 使用费用2.1.4 代码测试2.1.4.1 代码搜索引擎2.1.4.2 在线体验 2.2 CodeGeeX2.2.1 工具特点2.2.2 部署方式2.2.3 使用费用2.2.4 代码测试 2.3 Alibaba Cloud AI Coding Assistant(cosy&#…

【AI视野·今日NLP 自然语言处理论文速览 第三十六期】Tue, 19 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 19 Sep 2023 (showing first 100 of 106 entries) Totally 106 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Speaker attribution in German parliamentary debates with QLoRA-ada…

Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本、图像等领域,支持文搜、图搜文、图搜图匹配搜索
Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本、图像等领域,支持文搜、图搜文、图搜图匹配搜索
Similarities 相似度计算、语义匹配搜索工具包,实现了多种相似度计算、匹配搜索算法&…

解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。
但,想要直接利用 LLM 完成…
Hugging Face 实战系列 总目录
PyTorch 深度学习 开发环境搭建 全教程
Transformer:《Attention is all you need》
Hugging Face简介 1、Hugging Face实战-系列教程1:Tokenizer分词器(Transformer工具包/自然语言处理) Hungging Face实战-系列教程1:Tokenize…
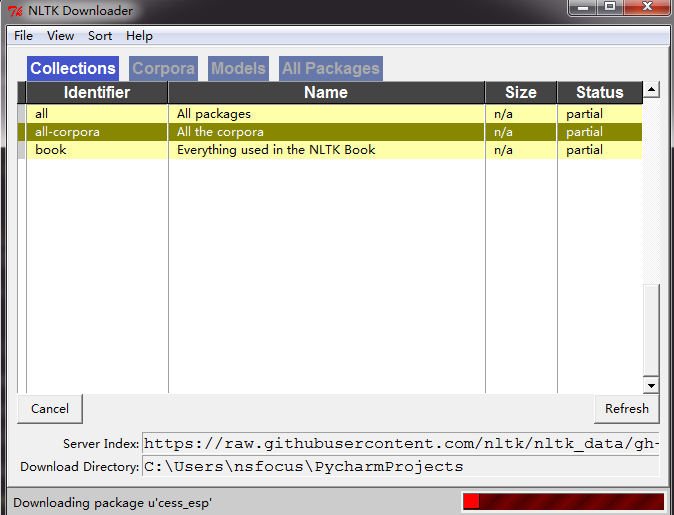
解决:NLTK包下载出错问题及NLP环境测试
Python 2.7 IDE Pycharm 5.0.3 NLTK 3.2.1 前言 需要用到自然语言处理了,安装调试过程记录一下,省的下次再找 【注意:软件安装需求:Python、NLTK、NLTK-Data必须安装,NumPy和Matplotlin推荐安装,NetworkX和…
【AI视野·今日NLP 自然语言处理论文速览 第三十七期】Wed, 20 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 20 Sep 2023 Totally 64 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
SlimPajama-DC: Understanding Data Combinations for LLM Training Authors Zhiqiang Shen, Tianhua Tao, Li…

【AI视野·今日NLP 自然语言处理论文速览 第四十三期】Thu, 28 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 28 Sep 2023 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Cross-Modal Multi-Tasking for Speech-to-Text Translation via Hard Parameter Sharing Authors Brian Yan,…


LangChain(0.0.340)官方文档七:Retrieval——document_loaders
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、简介1.1 BaseLoader1.2 文本加载(TextLoader) 二、 CSV(CSVLoader)2.1 默认加载2.2 指定一列来标识文档来源 三、 HTML l…
Kaggle - LLM Science Exam上:赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 deberta-v3-large 1k Wikiÿ…
社交网络分析2(下):社交网络情感分析的方法、挑战与前沿技术
社交网络分析2(下):社交网络情感分析的方法、挑战与前沿技术 写在最前面7. 词嵌入(word embedding)的主要目的是什么?结合某方法简要地说明如何实现词嵌入。主要目的实现方法示例:GloVe案例分析…

【AI视野·今日NLP 自然语言处理论文速览 第五十期】Mon, 9 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 9 Oct 2023 Totally 32 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation Authors Fangyuan …

Kaggle - LLM Science Exam(三):Wikipedia RAG
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、 [EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS2.1 Data overview2.2 Data gathering 三、如何高效收集数据3.1 概述3.2 与训练数据关联的维基百科类别…
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术…
安装torch113、cuda116并运行demo【Transformer】
文章目录 01. 导读02. 显卡驱动版本03. 创建环境、下载安装必要包04. 运行参考代码: 01. 导读
安装torch113、cuda116并运行demo【Transformer】
02. 显卡驱动版本
C:\Users\Administrator>nvidia-smi -l 10 Wed Sep 13 23:35:08 2023 ----------------------…
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇],支持Linux/Windows部署安装
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术…

【AI视野·今日NLP 自然语言处理论文速览 第六十期】Mon, 23 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 23 Oct 2023 (showing first 100 of 108 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Exploring Linguistic Probes for Morphological Generalization Autho…
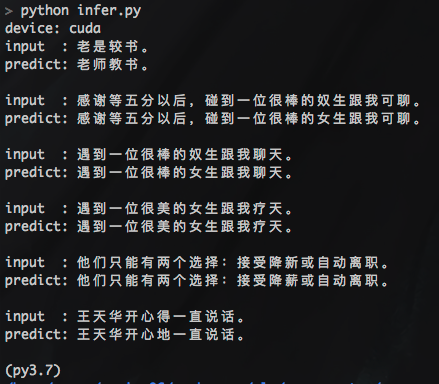
pycorrector一键式文本纠错工具,整合了BERT、MacBERT、ELECTRA、ERNIE等多种模型,让您立即享受纠错的便利和效果
pycorrector:一键式文本纠错工具,整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer、T5等多种模型,让您立即享受纠错的便利和效果 pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,pytho…

dialogbot:开箱即用的对话机器人解决方案,涵盖问答型对话、任务型对话和聊天型对话等多种场景,为您提供全方位的对话交互体验。
dialogbot:开箱即用的对话机器人解决方案,涵盖问答型对话、任务型对话和聊天型对话等多种场景,支持网络检索问答、领域知识问答、任务引导问答和闲聊问答,为您提供全方位的对话交互体验。 人机对话系统一直是AI的重要方向…
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力。
一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务进行优化。CLIP的设计类似于GPT-2和GPT-3,具备出色的零射击能力…
主题模型LDA教程:n-gram N元模型和nltk应用
文章目录 N-Gram 模型原理概率估计 nltk使用n-gram N-Gram 模型
N-Gram(N元模型)是自然语言处理中一个非常重要的概念。N-gram模型也是一种语言模型,是一种生成式模型。
假定文本中的每个词 w i w_{i} wi和前面 N − 1 N-1 N−1 个词有…
文档向量化工具(一):Apache Tika介绍
Apache Tika是什么?能干什么?
Apache Tika是一个内容分析工具包。
该工具包可以从一千多种不同的文件类型(如PPT、XLS和PDF)中检测并提取元数据和文本。
所有这些文件类型都可以通过同一个接口进行解析,这使得Tika在…
【论文复现】DAE:《Annotating and Modeling Fine-grained Factuality in Summarization》
以下是复现论文《 Annotating and Modeling Fine-grained Factuality in Summarization》(NAACL 2021)代码https://github.com/tagoyal/factuality-datasets的流程记录: 在服务器上conda创建虚拟环境dae(python版本于readme保持一…
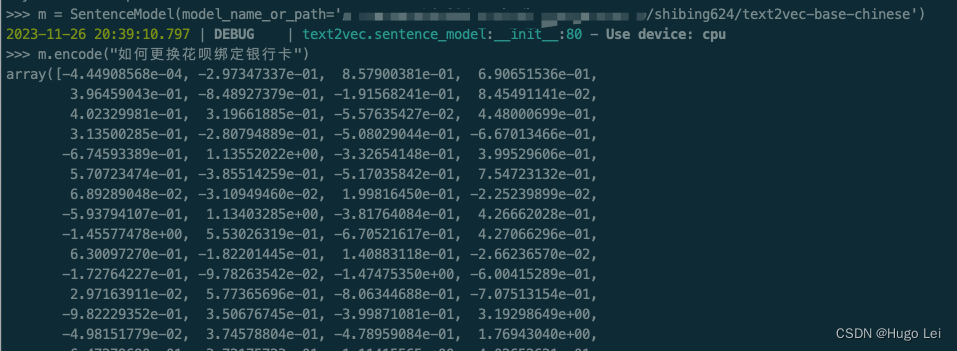
文档向量化工具(二):text2vec介绍
目录
前言
text2vec开源项目
核心能力
文本向量表示模型
本地试用
安装依赖
下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过)
运行试验代码 前言 在上一篇文章中介绍了,如何从不同格式的文件里提取…


文档理解的新时代:LayOutLM模型的全方位解读
一、引言
在现代文档处理和信息提取领域,机器学习模型的作用日益凸显。特别是在自然语言处理(NLP)技术快速发展的背景下,如何让机器更加精准地理解和处理复杂文档成为了一个挑战。文档不仅包含文本信息,还包括布局、图…
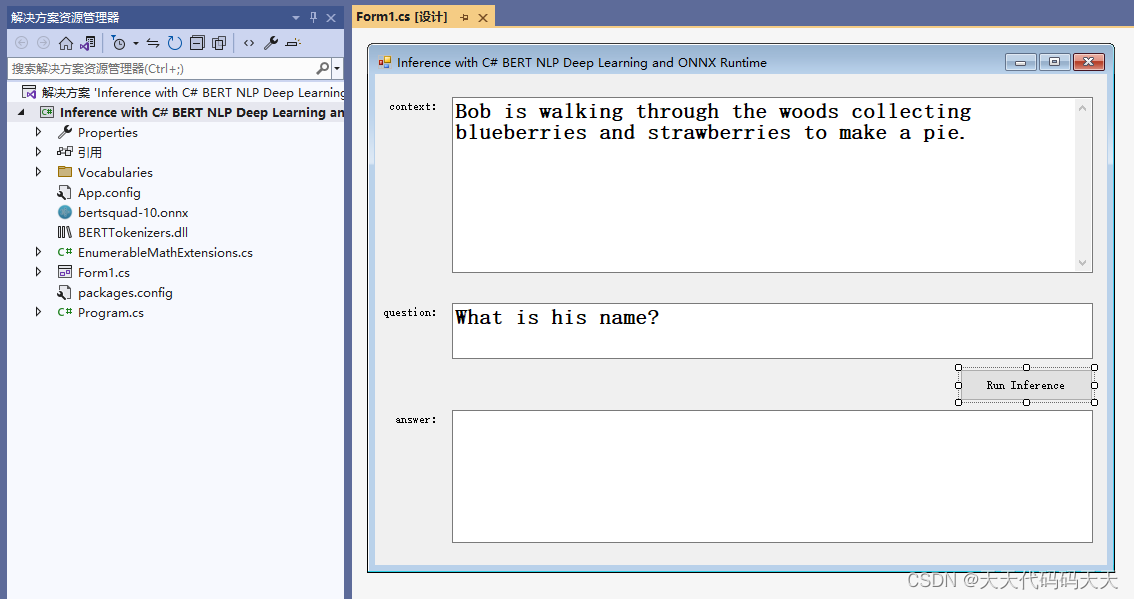
Inference with C# BERT NLP Deep Learning and ONNX Runtime
目录
效果
测试一
测试二
测试三
模型信息
项目
代码
下载 Inference with C# BERT NLP Deep Learning and ONNX Runtime
效果
测试一
Context :Bob is walking through the woods collecting blueberries and strawberries to make a pie.
Question …
LangChain(0.0.340)官方文档三:Prompts上——自定义提示模板、使用实时特征或少量示例创建提示模板
文章目录 一、 Prompt templates1.1 langchain_core.prompts1.2 PromptTemplate1.2.1 简介1.2.2 ICEL1.2.3 Validate template 1.3 ChatPromptTemplate1.3.1 使用role创建1.3.2 使用MessagePromptTemplate创建1.3.3 自定义MessagePromptTemplate1.3.3.1 自定义消息角色名1.3.3.…
LangChain(0.0.339)官方文档四:Prompts下——prompt templates的存储、加载、组合和部分格式化
文章目录 一、 部分提示模板1.1 使用字符串值进行部分格式化(Partial with strings)1.2 使用函数进行部分格式化(Partial with functions) 二、Prompt pipelining2.1 String prompt pipelining2.2 Chat prompt pipelining 三、使用…
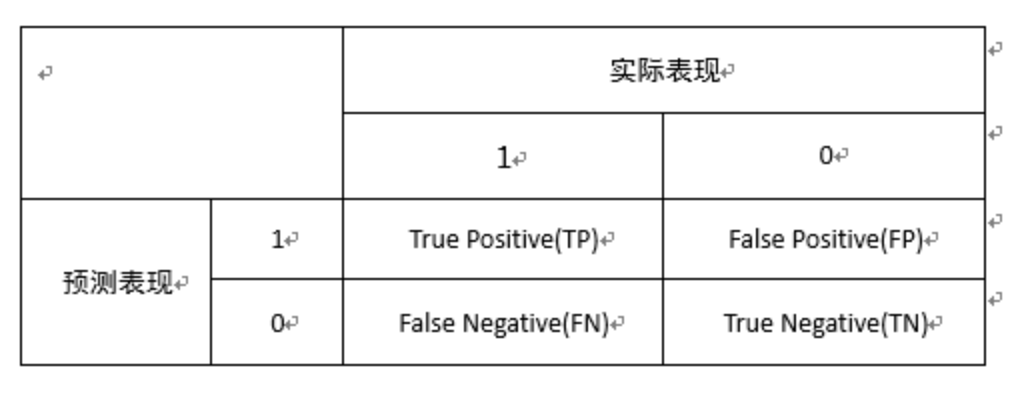
NLP中基本概念入门
词向量(Word Embedding) 词向量主要用于将自然语言中的词符号数学化,这样才能作为机器学习问题的输入。 数学化表示词的方式很多,最简单的有独热编码,即“足球”[0,0,1,0,0,0,0,…],“篮球”[0,0,0,0,0,1,0…
从零构建属于自己的GPT系列4:模型训练3(训练过程解读、序列填充函数、损失计算函数、评价函数、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
从零构建属于自己的GPT系列5:模型本地化部署(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
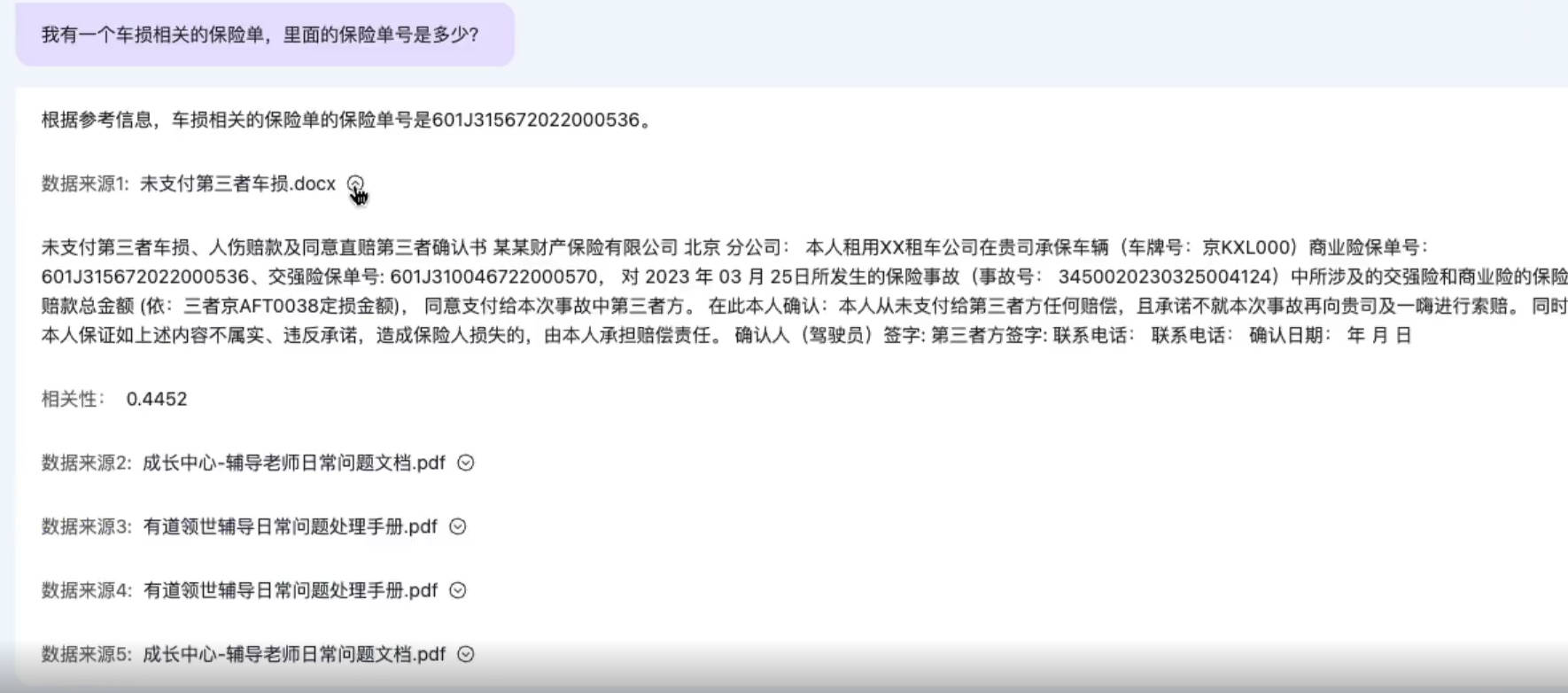
Anything本地知识库问答系统:基于检索增强生成式应用(RAG)两阶段检索、支持海量数据、跨语种问答
QAnything本地知识库问答系统:基于检索增强生成式应用(RAG)两阶段检索、支持海量数据、跨语种问答
QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。…
标签正则化和硬标签、软标签、单标签、多标签
起因:最近在训练一个非常简单的二分类任务(计算描述两个实体的文本是否描述的是同一个实体),任务训练模式是用NLP大模型批量标注样本,在蒸馏后的robert_base上进行fine-tune,但是存在以下问题: …
Qwen 通义千问 14B 模型,长文本问答效果测试
千问的config:
seq_len2k max_position_embedding8k
注意,以下实验结果的字数是token数,不是中文字符数。
不使用动态ntk
12000字输入: 乱码5000字输入:乱码1500字输入:正常
不使用动态ntk,…
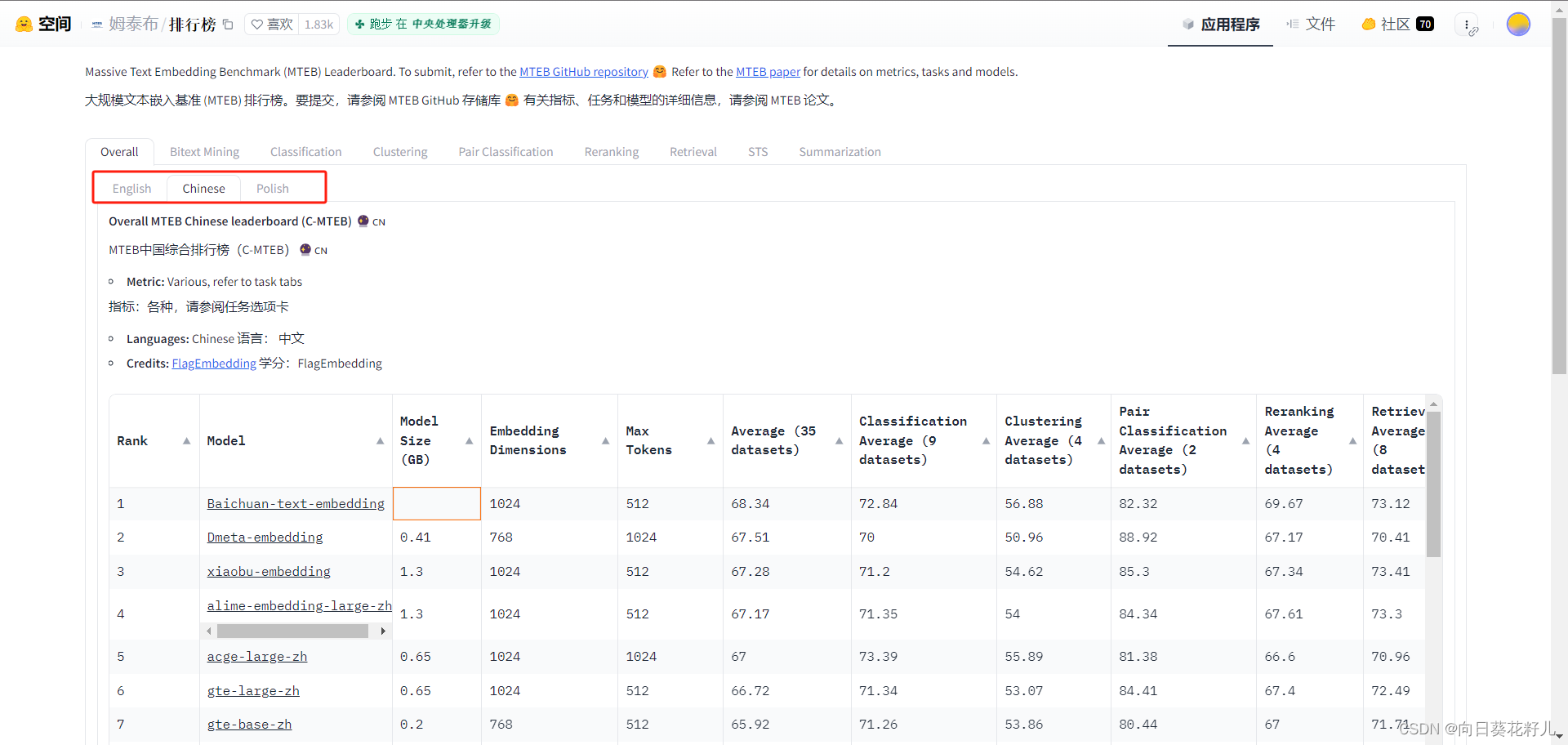
#RAG#llm时代-RAG各模块痛点总结及解决办法,强化rag认知
RAG(Retrieval-Augmented Generation)技术是一种结合了检索和生成的方法,能够在生成文本的过程中利用外部知识库或语境来提高生成文本的质量和准确性。在当前的LLM(Large Language Model)时代,RAG技术显得尤…
LLaMA-2 下载demo使用
LLaMA-2 下载&demo使用 1. LLaMA-2 下载&demo使用1.1 meta官网1.2 huggingface1.3 其他源1.4 huggingface下载模型和数据加速 1. LLaMA-2 下载&demo使用
1.1 meta官网
llama2下载
在meta的官网 Meta website 进行下载申请(注意地区不要选择China会被…

人工智能快速发展时代下的“AI诈骗防范”
当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿冒他人身份实施诈骗、侵害消费者合法权益。你认为AI诈骗到底应该如何防范…
huggingface实战bert-base-chinese模型(训练+预测)
文章目录 前言一、bert模型词汇映射说明二、bert模型输入解读1、input_ids说明2、attention_mask说明3、token_type_ids说明4、模型输入与vocab映射内容二、huggingface模型数据加载1、数据格式查看2、数据dataset处理3、tokenizer处理dataset数据三、huggingface训练bert分类模…

Python 自己训练chatGPT,实例代码如下;简单易懂的训练chatGPT,模板实例;自己训练chatGPT
代码实例:
比较简单的示例,其它gpt架构相关知识和代码移步专栏其它文章。
from torchtext.datasets import WikiText2 # 导入WikiText2
from torchtext.data.utils import get_tokenizer # 导入Tokenizer分词工具
from torchtext.vocab import build_…
HuggingFace Hub系列:推动NLP前进的协作平台
在当今快速发展的机器学习(ML)领域,没有任何一个公司,包括科技巨头,能够独立“解决AI”。这是一个需要通过共享知识和资源在社区中协作来实现的目标。正是基于这个信念,Hugging Face Hub应运而生,它是一个集成了超过12…
NLP_新闻主题分类_7(代码示例)
目标
有关新闻主题分类和有关数据.使用浅层网络构建新闻主题分类器的实现过程.
1 案例说明 关于新闻主题分类任务: 以一段新闻报道中的文本描述内容为输入, 使用模型帮助我们判断它最有可能属于哪一种类型的新闻, 这是典型的文本分类问题, 我们这里假定每种类型是互斥的, 即文…

【AI视野·今日NLP 自然语言处理论文速览 第八十期】Fri, 1 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 1 Mar 2024 Totally 67 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Loose LIPS Sink Ships: Asking Questions in Battleship with Language-Informed Program Sampling Authors G…
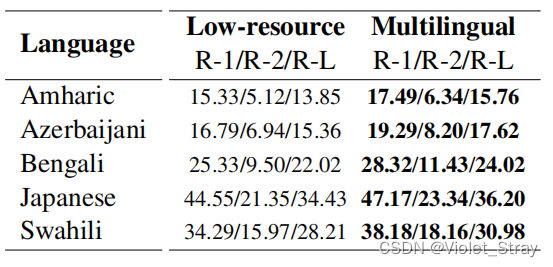
【翻译】XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
摘要
当代的关于抽象文本摘要的研究主要集中在高资源语言,比如英语,这主要是因为低/中资源语言的数据集有限。在这项工作中,我们提出了XL-Sum,这是一个包含100万篇专业注释的文章摘要对的综合多样数据集,从BBC中提取&…

大型语言模型与知识图谱的完美结合:从LLMs到RAG,探索知识图谱构建的全新篇章
最近,使用大型语言模型(LLMs)和知识图谱(KG)开发 RAG(Retrieval Augmented Generation)流程引起了很大的关注。在这篇文章中,我将使用 LlamaIndex 和 NebulaGraph 来构建一个关于费城费利斯队(Philadelphia Phillies)的 RAG 流程。
我们用的是开源的 NebulaGraph 来…
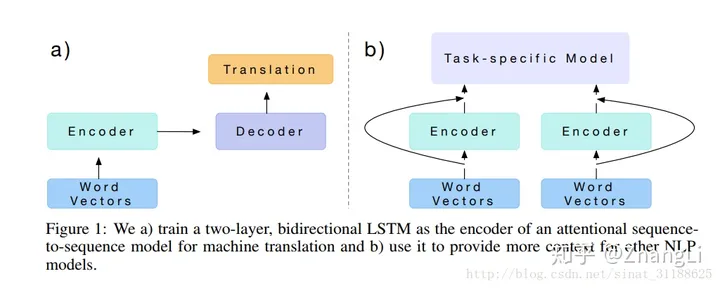
传统词嵌入方法的千层套路
诸神缄默不语-个人CSDN博文目录
在自然语言处理(NLP)领域,词嵌入是一种将词语转换为数值形式的方法,使计算机能够理解和处理语言数据。 词嵌入word embedding也叫文本向量化/文本表征。 本文将介绍几种流行的传统词嵌入方法。 文…
jupyter快速实现单标签及多标签多分类的文本分类BERT模型
jupyter实现pytorch版BERT(单标签分类版)
nlp-notebooks/Text classification with BERT in PyTorch.ipynb
通过改写上述代码,实现多标签分类
参考解决方案 ,我选择的解决方案是继承BertForSequenceClassification并改写&#…

书生·浦语大模型实战营-学习笔记2
目录 轻松玩转书生浦语大模型趣味Demo1. 大模型及 InternLM 模型介绍2. InternLM-Chat-7B 智能対话 Demo3. Lagent 智能体工具调用 Demo4. 浦语•灵笔图文创作理解 Demo5. 通用环境配置实验记录6. 课后作业 视频地址: (2)轻松玩转书生浦语大模型趣味Demo 文档教程&a…

从零构建属于自己的GPT系列1:数据预处理(文本数据预处理、文本数据tokenizer、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…
从零构建属于自己的GPT系列3:模型训练2(训练函数解读、模型训练函数解读、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…
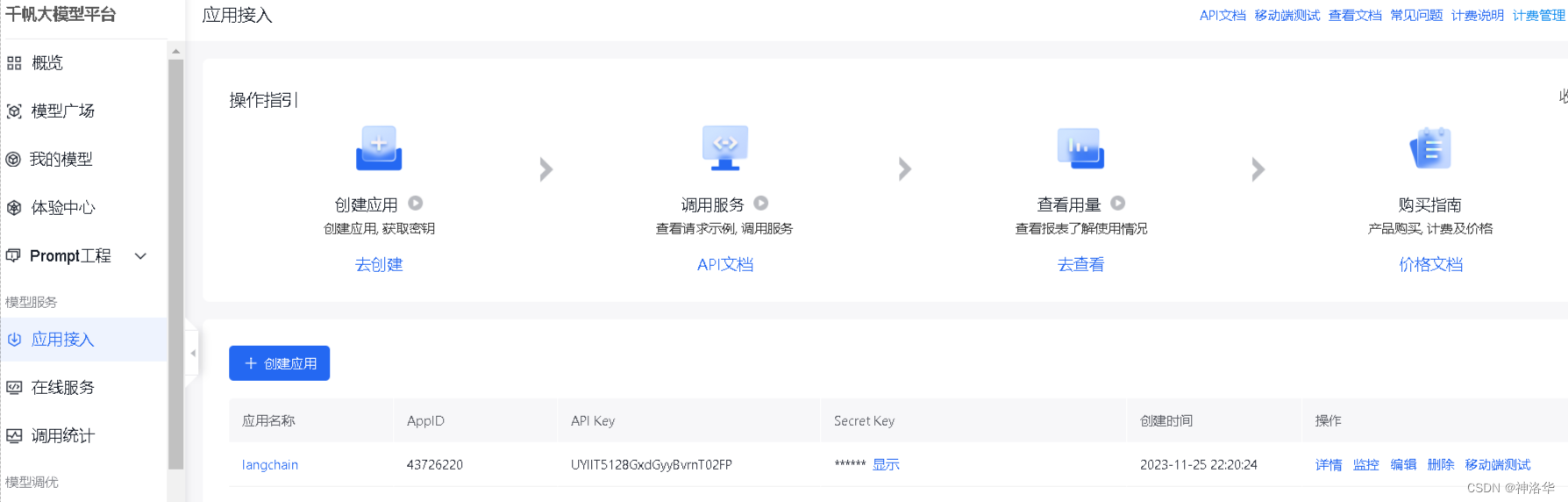
LangChain(0.0.340)官方文档五:Model
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、Chat models1.1 Chat models简介1.2 Chat models的调用方式1.2.1 环境配置1.2.2 使用LCEL方式调用Chat models1.2.3 使用内置Chain调用Chat models 1.3 缓存1.3.1 内存缓存…
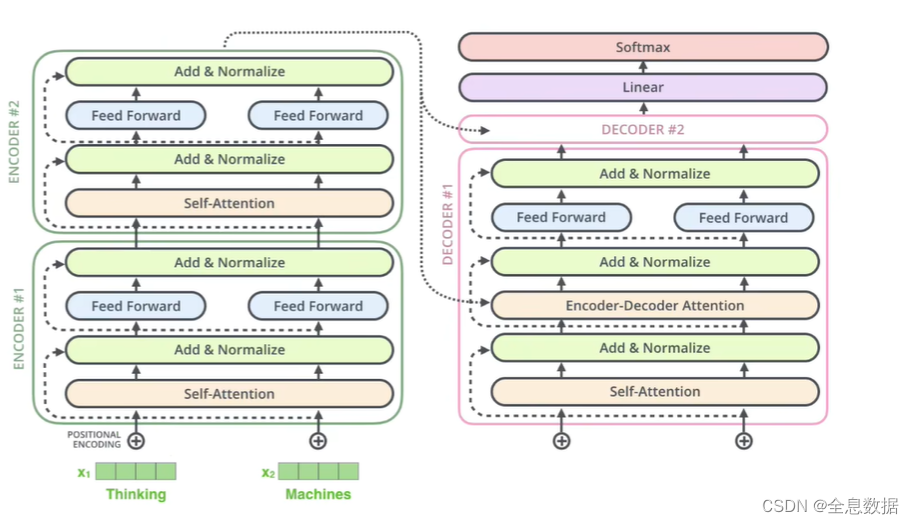
Transformer详解【学习笔记】
文章目录 1、Transformer绪论2、Encoders和Decoder2.1 Encoders2.1.1 输入部分2.1.2 多头注意力机制2.1.3 残差2.1.4 LayNorm(Layer Normalization)2.1.5 前馈神经网路 2.2 Decoder2.2.1 多头注意力机制2.2.2 交互层 1、Transformer绪论 Transformer在做…
seq2seq:中英文翻译
文章目录 一、完整代码二、论文解读2.1 RNN模型2.2 Attention-based ModelsGlobal attentional modelLocal attentional model 2.3 Input-feeding Approach2.4 模型效果 三、过程实现3.1 导包3.2 数据准备3.3 构建相关类3.4 模型配置3.5 模型推理 四、整体总结 论文:…

Python数据分析案例33——新闻文本主题多分类(Transformer, 组合模型) 模型保存
案例背景
对于海量的新闻,我们可能需要进行文本的分类。模型构建很重要,现在对于自然语言处理基本都是神经网络的方法了。
本次这里正好有一组质量特别高的新闻数据,涉及 教育 科技 社会 时政 财经 房产 家居 七大主题,基本涵盖…

人工智能的新篇章:深入了解大型语言模型(LLM)的应用与前景
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

自然语言处理(Natural Language Processing,NLP)解密
专栏集锦,大佬们可以收藏以备不时之需:
Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9
Python 专栏:http://t.csdnimg.cn/hMwPR
Redis 专栏:http://t.csdnimg.cn/Qq0Xc
TensorFlow 专栏:http://t.csdni…
NLP Seq2Seq模型
🍨 本文为[🔗365天深度学习训练营学习记录博客🍦 参考文章:365天深度学习训练营🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mi…
自然语言处理的技术进步与应用领域的拓展
文章目录
技术进步:推动NLP前行的关键技术
应用场景:NLP技术的实际应用
挑战与前景:NLP的未来发展
未来的发展趋势可能包括
总结 技术进步:推动NLP前行的关键技术
自然语言处理(NLP)是计算机科学和人…

tess4j 实现 OCR 图片文字识别
OCR图像识别技术的JAVA实现
最近有个需求需要用图像识别,学习记录一下。
目前网络上的开源的图像识别技术有很多,例如 OCRE(OCR Easy)、Clara OCR、OCRAD、TESSERACT-OCR 等。
今天本blog将记录下tesseract-ocr的JAVA实现,便于以后查阅使用…

【AI视野·今日NLP 自然语言处理论文速览 第七十六期】Fri, 12 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 12 Jan 2024 Totally 60 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Axis Tour: Word Tour Determines the Order of Axes in ICA-transformed Embeddings Authors Hiroaki Yamagi…
TensorFlow2实战-系列教程12:RNN文本分类4
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 8、压缩版本网络模型
class Model(tf.keras.Model):def __init__(self, params):supe…
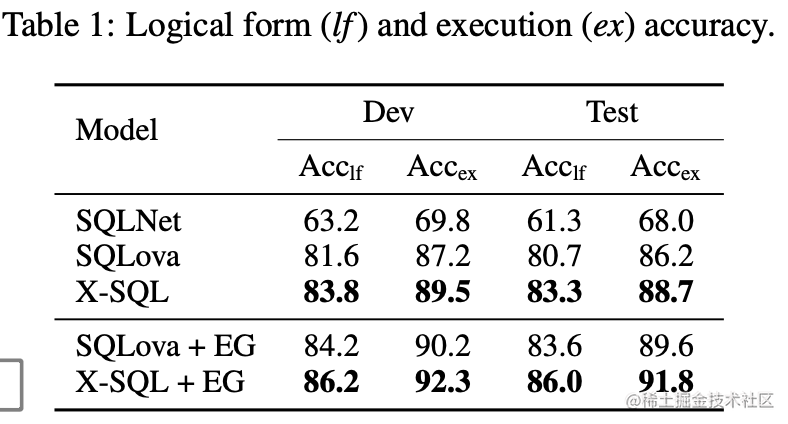
Text2SQL学习整理(四)将预训练语言模型引入WikiSQL任务
导语
上篇博客:Text2SQL学习整理(三):SQLNet与TypeSQL模型简要介绍了WikiSQL数据集提出后两个早期的baseline,那时候像BERT之类的预训练语言模型还未在各种NLP任务中广泛应用,因而作者基本都是使用Bi-LSTM…
NLP - 共现矩阵、Glove、评估词向量、词义
Word2vec算法优化 J(θ): 损失函数 问题:进行每个梯度更新时,都必须遍历整个语料库,需要等待很长的时间,优化将非常缓慢。 解决:不用梯度下降法,用随机梯度下降法 (SGD)。 减少噪音&…
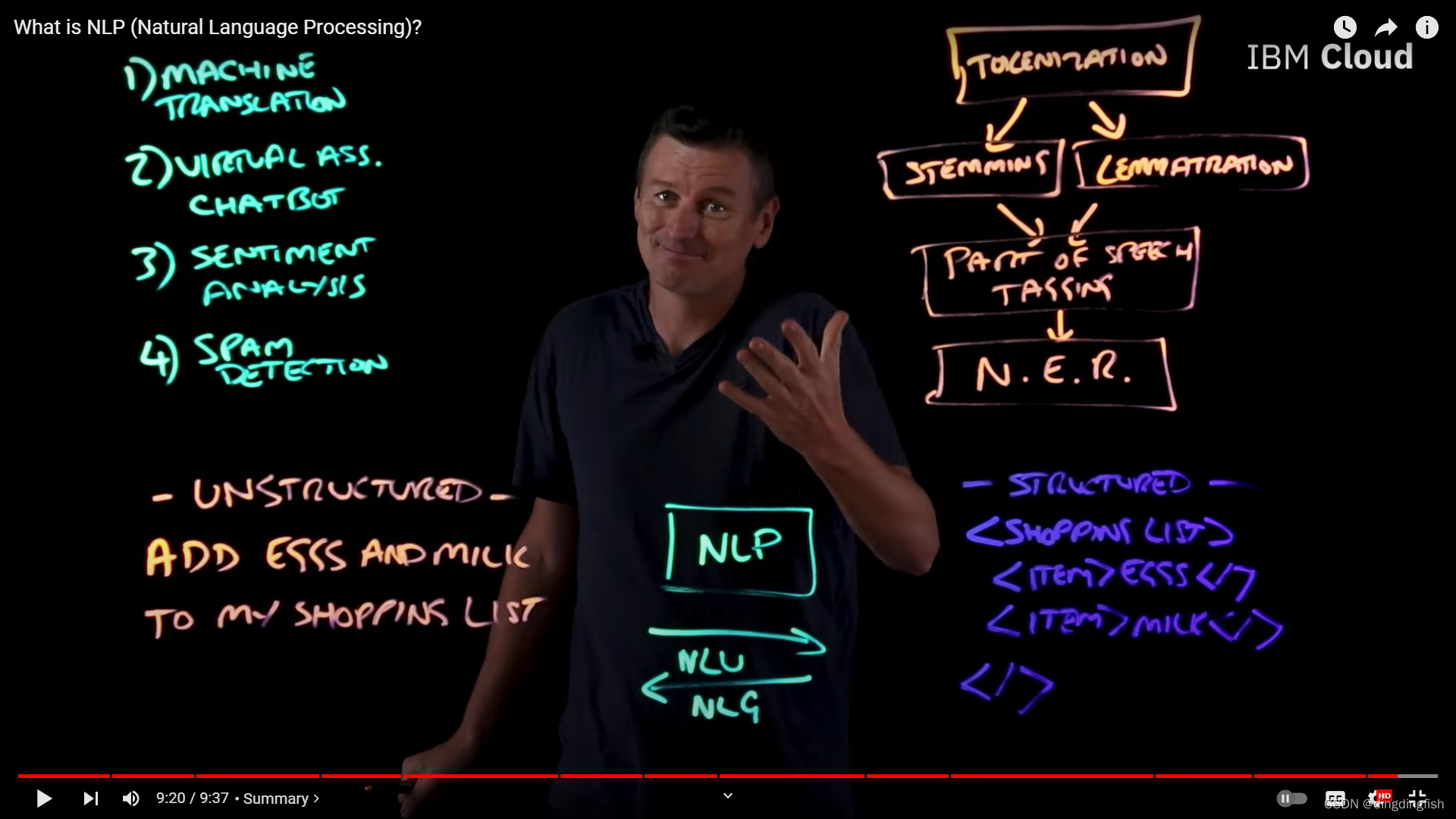
什么是自然语言处理(NLP)?
此为观看视频What is NLP (Natural Language Processing)?后的笔记。 你正在看这个视频,试图理解作者说的单词和句子,当我们要求计算机做到这一点时,这就是 NLP,即自然语言处理。 NLP 在人工智能应用中实用价值很高。NLP 从非结构…

自然语言处理(NLP)中NER如何从JSON数据中提取实体词的有效信息
专栏集锦,大佬们可以收藏以备不时之需:
Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9
Python 专栏:http://t.csdnimg.cn/hMwPR
Redis 专栏:http://t.csdnimg.cn/Qq0Xc
TensorFlow 专栏:http://t.csdni…
NLP_文本张量表示方法_2(代码示例)
目标
了解什么是文本张量表示及其作用.文本张量表示的几种方法及其实现.
1 文本张量表示 将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
["人生", "该&q…
NLP学习路线指南总结
当然可以,以下是一份较为详细的NLP学习路线指南,帮助你逐步掌握自然语言处理的核心技术和应用。
一、基础知识与技能
语言学基础: 语言学基本概念:语音、语法、语义等。语言的层次与分类:语音学、音系学、句法学、语…

anaconda虚拟环境安装apex0.1教程win10
我安装apex0.1的环境是:torch(gpu)1.8.0,cuda10.2,cuda7.6.5。
第一步:下载对应的pytorch、cuda、cudnn版本
这里就不详细介绍了,具体可以参考我的这篇博文win10中anaconda创建虚拟环境配置py…
大模型的Base版本模型、Chat版本模型和4Bit版本模型有什么区别
在最近开源的大部分大语言模型里,我们往往能看到在huggingface上,同一数据量级会有Base版本模型、Chat版本模型和4Bit模型等多个版本的模型,像我一样的新手小白可能会搞不清楚我应该用哪个来使用
下面是一些总结: Base版本模型&a…
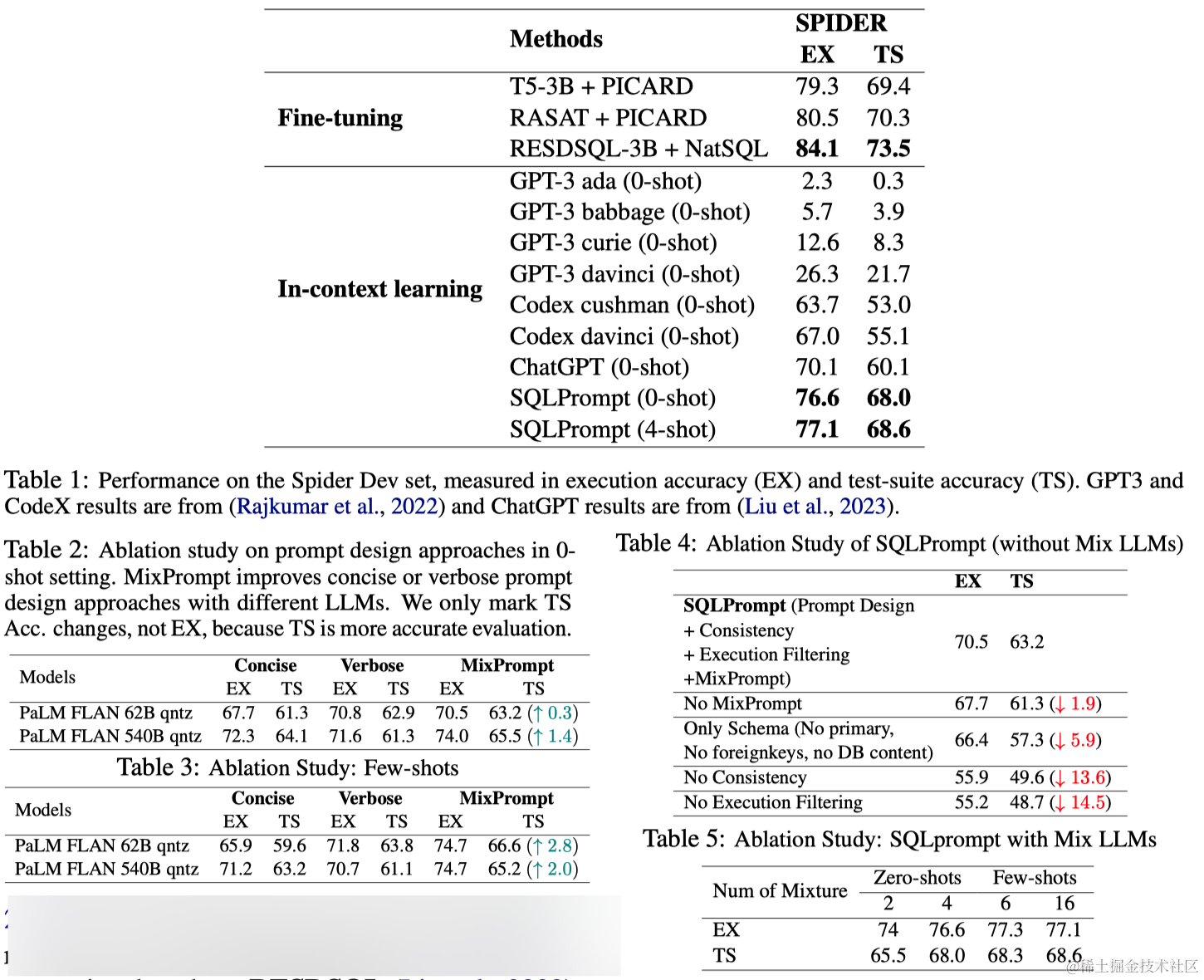
论文笔记:SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
导语
本文提出了SQLPrompt,通过创新的Prompt设计、基于执行一致性的解码策略,以及混合不同格式的Prompt和不同LLMs输出的方式,提高了LLM在Few-shot In-context Learning下的能力。
会议:EMNLP 2023 Findings (Short&…

【论文笔记】Multi-Chain Reasoning:对多思维链进行元推理
目录 写在前面1. 摘要2. 相关知识3. MCR方法3.1 生成推理链3.2 基于推理链的推理 4. 实验4.1 实验设置4.2 实验结果 5. 提及文献 写在前面
文章标题:Answering Questions by Meta-Reasoning over Multiple Chains of Thought论文链接:【1】代码链接&…
干掉“卧槽”!首个支持中文及跨语言查询的开源在线反向词典!
大家好,我是 Java陈序员。
我们在生活中,会遇到一些有趣的人和事,或者是一些令人惊叹的风景。想表达抒发自己心情的时候,到嘴边往往却只能说一句“卧槽”! 别问我为啥知道,因为“俺也一样”! 今…

语言革命:NLP与GPT-3.5如何改变我们的世界
文章目录 📑前言一、技术进步与应用场景1.1 技术进步1.2 应用场景 二、挑战与前景三、伦理和社会影响四、实践经验五、总结与展望 📑前言 自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支…
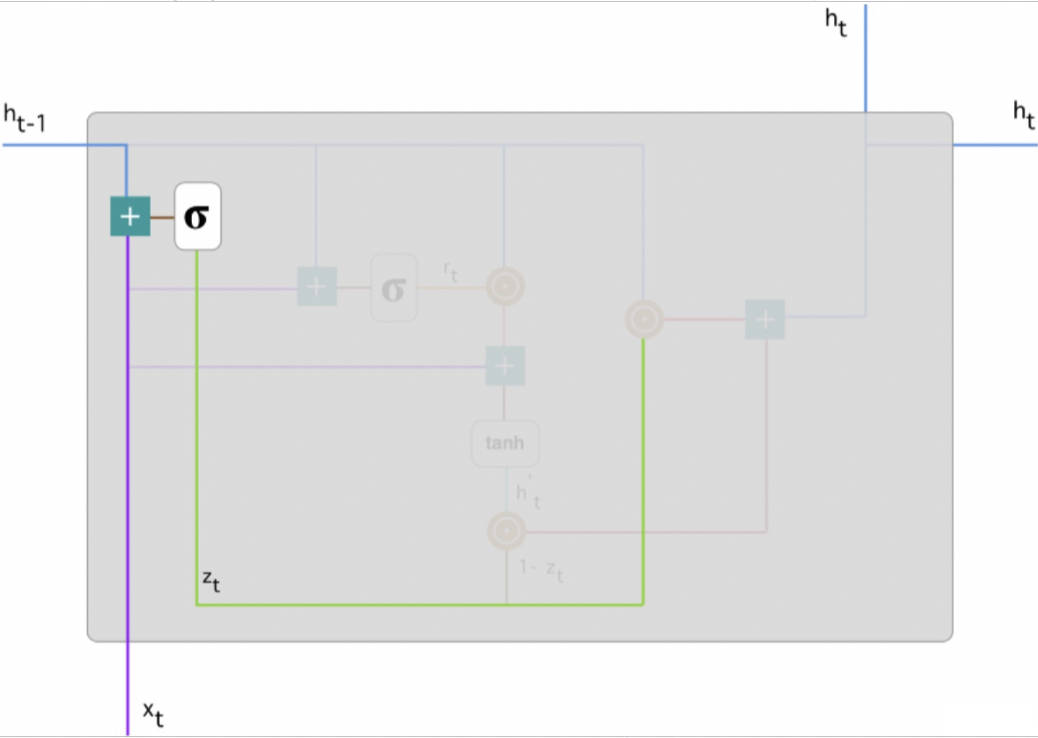
基于BiLSTM-CRF模型的分词、词性标注、信息抽取任务的详解,侧重模型推导细化以及LAC分词实践
基于BiLSTM-CRF模型的分词、词性标注、信息抽取任务的详解,侧重模型推导细化以及LAC分词实践
1.GRU简介
GRU(Gate Recurrent Unit)门控循环单元,是[循环神经网络](RNN)的变种种,与 LSTM 类似通过门控单元解决 RNN 中不能长期记忆和反向传播中的梯度等问题。与 LSTM 相…
Byte-Pair Encoding(BPE)
Byte-Pair Encoding(简称BPE)是一种在自然语言处理(NLP)中使用的压缩算法,它用一小组子词单元表示大词汇量。它由Sennrich等人于2016年引入,并广泛用于各种NLP任务,如machine translation, text classification, and text generation。BPE的基本思想是通过迭代地合并文本…

Re61:读论文 PRP Get an A in Math: Progressive Rectification Prompting
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Get an A in Math: Progressive Rectification Prompting
ArXiv网址:https://arxiv.org/abs/2312.06867 官方实现网站:PRP 官方代码:https://github.…

重塑语言智能未来:掌握Transformer,驱动AI与NLP创新实战
Transformer模型 Transformer是自然语言理解(Natural Language Understanding,NLU)的游戏规则改变者,NLU 是自然语言处理(Natural Language Processing,NLP)的一个子集。NLU已成为全球数字经济中AI 的支柱之一。
Transformer 模型标志着AI 新…
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)
使用PaddleNLP识别垃圾邮件:用BERT做中文邮件内容分类,验证集准确率高达99.6%以上(附公开数据集)。
要使用PaddleNLP和BERT来识别垃圾邮件并做中文邮件内容分类,可以按照以下步骤进行操作: 安装PaddlePaddle和PaddleNLP:首先,确保在你的环境中已经安装了PaddlePaddle和…

推荐一款开源的跨平台划词翻译和OCR翻译软件:Pot
Pot简介
一款开源的跨平台划词翻译和OCR翻译软件 下载安装指南 根据你的机器型号下载对应版本,下载完成后双击安装即可。 使用教程
Pot具体功能如下:
划词翻译输入翻译外部调用鼠标选中需要翻译的文本,按下设置的划词翻译快捷键即可按下输…
自然语言处理(NLP)——使用Rasa创建聊天机器人
1 基本概念
1.1 自然语言处理的分类 IR-BOT:检索型问答系统 Task-bot:任务型对话系统 Chitchat-bot:闲聊系统
1.2 任务型对话Task-Bot:task-oriented bot 这张图展示了一个语音对话系统(或聊天机器人)的基本组成部分和它们之间的…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.10-2024.02.15
2024.02.10–2024.02.15: arXiv中发表的关于大语言模型(LLMs)相关的文章,已经筛选过一部分,可能有的文章质量并不是很好,但是可以看出目前LLM的科研大方向!
后续我会从中选择出比较有意思的文章…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.05-2024.02.10
相关LLMs论文大多都是应用型文章,少部分是优化prompt/参数量级等等… 有一些应用文还是值得参考的,当工作面临一个新的场景,可以学习下他人是如何结合LLMs与实际应用中的链接。
LLMs论文速览:2024.02.05-2024.02.10: …
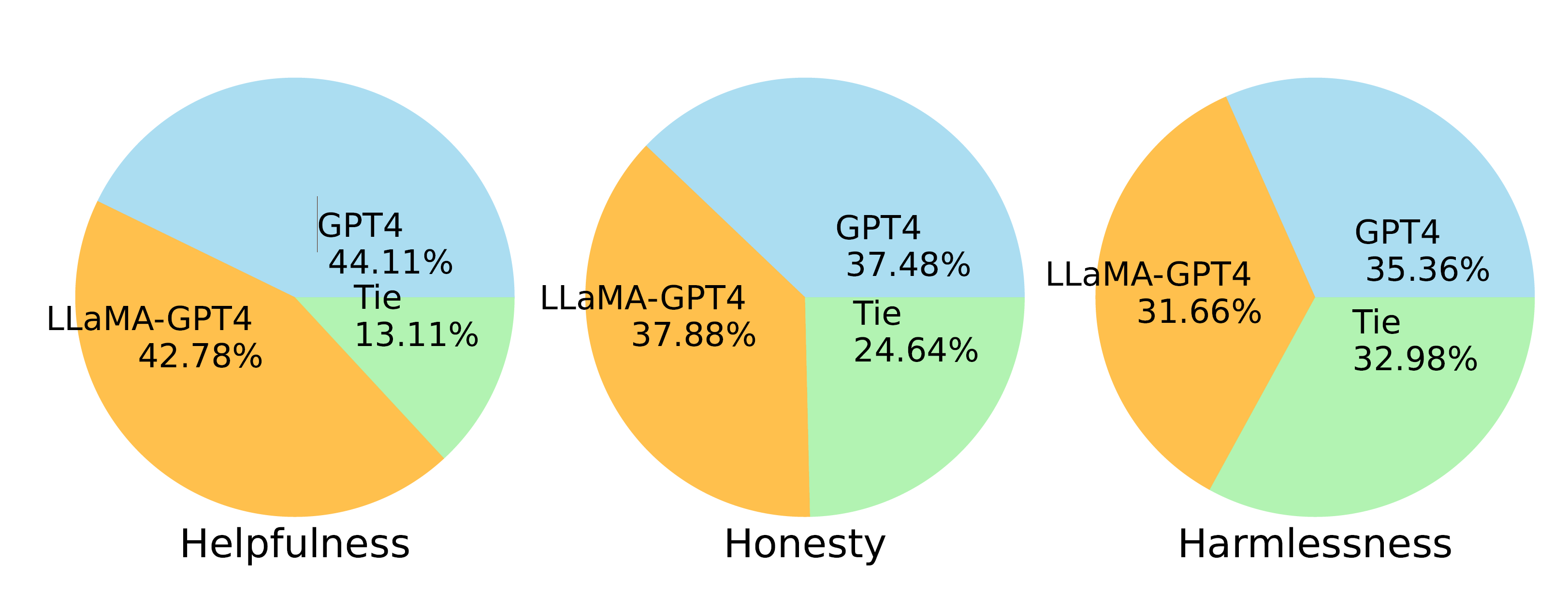
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库&am…

探秘SuperCLUE-Safety:为中文大模型打造的多轮对抗安全新框架
探秘SuperCLUE-Safety:为中文大模型打造的多轮对抗安全新框架
进入2023年以来,ChatGPT的成功带动了国内大模型的快速发展,从通用大模型、垂直领域大模型到Agent智能体等多领域的发展。但是生成式大模型生成内容具有一定的不可控性࿰…
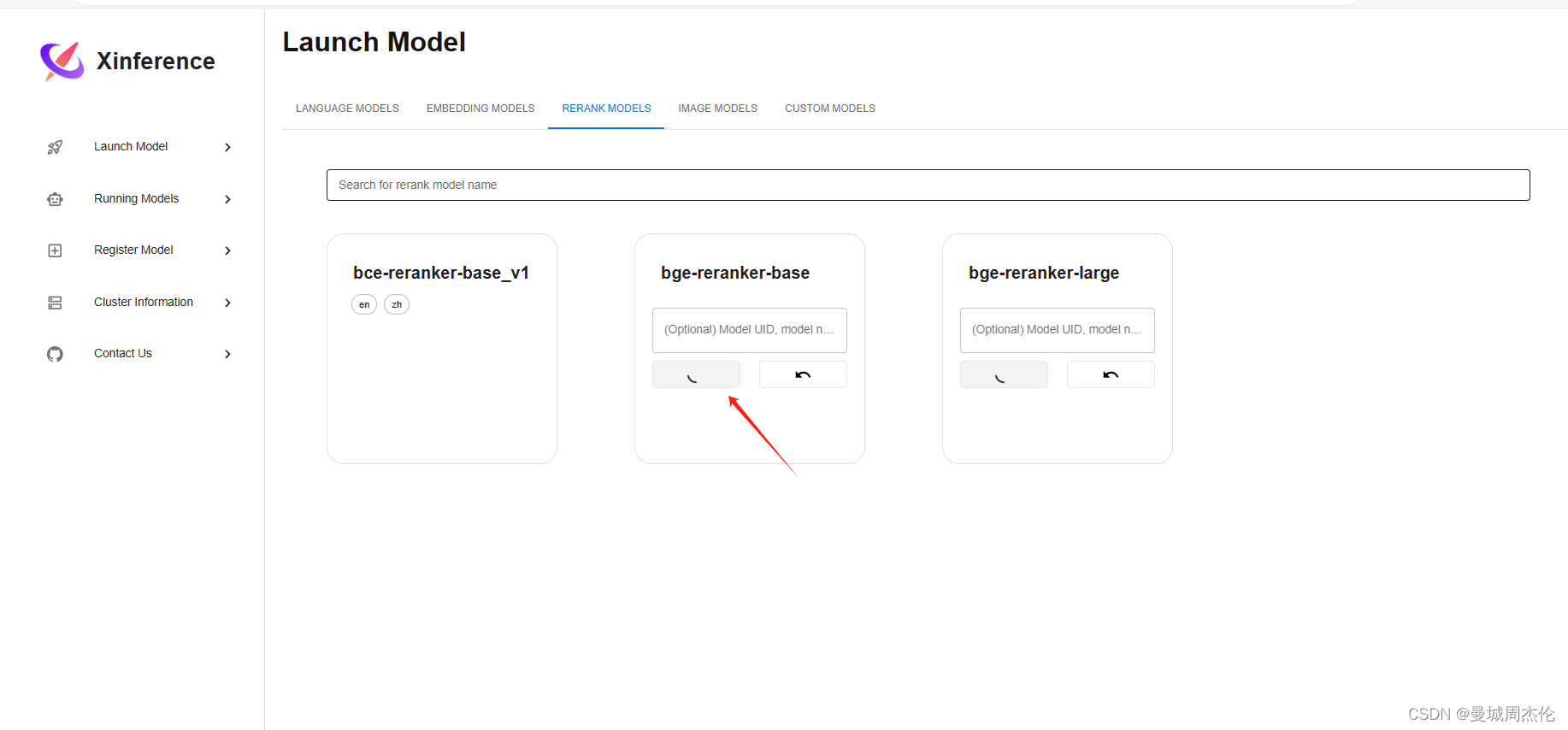
自然语言处理: 第十三章Xinference部署
项目地址: Xorbitsai/inference
理论基础
正如同Xorbits Inference(Xinference)官网介绍是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通…
自然语言处理(NLP)技术-AI生成版
自然语言处理(NLP)是一种涵盖众多技术的交叉学科,旨在使计算机能够理解、生成和处理自然语言文本。它涉及语言学、计算机科学、统计学和人工智能等多个领域。下面将举例说明NLP技术在实际应用中的一些场景。
情感分析
情感分析是指使用NLP技…
自然语言处理22-基于本地知识库的快速问答系统,利用大模型的中文训练集为知识库
大家好,我是微学AI,今天给大家介绍一下自然语言处理22-基于本地知识库的快速问答系统,利用大模型的中文训练集为知识库。我们的快速问答系统是基于本地知识库和大模型的最新技术,它利用了经过训练的中文大模型,该模型使用了包括alpaca_gpt4_data的开源数据集。
一、本地…

hanlp,pkuseg,jieba,cutword分词实践
总结:只有jieba,cutword,baidu lac成功将色盲色弱成功分对,这两个库字典应该是最全的
hanlp[持续更新中]
https://github.com/hankcs/HanLP/blob/doc-zh/plugins/hanlp_demo/hanlp_demo/zh/tok_stl.ipynb
import hanlp
# hanlp.pretrained.tok.ALL # 语种见名称最…
NLP_jieba和hanlp词性对照表_6
jieba词性对照表: - a 形容词 - ad 副形词 - ag 形容词性语素 - an 名形词 - b 区别词 - c 连词 - d 副词 - df - dg 副语素 - e 叹词 - f 方位词 - g 语素 - h 前接成分 - i 成语 - j 简称略称 - k 后接成分 - l 习用语 …
【第十二届“泰迪杯”数据挖掘挑战赛】【2024泰迪杯】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:模型数据、全套代码、训练好的模…
什么是自然语言处理(NLP)?自然语言处理(NLP)的概述
什么是自然语言处理?
自然语言处理(NLP)是人工智能(AI)和计算语言学领域的一个分支,它致力于使计算机能够理解、解释和生成人类语言。随着技术的发展,NLP已经从简单的模式匹配发展到了能够理解…
快速安装sudachipy日语包
1、前往 https://rustup.rs 下载并安装 Rustup
Linux系统可直接运行以下命令 Window系统需要去网站下载exe包
curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh2、安装 Rust 编译器
rustup install stable3、设置默认版本
rustup default stable4、重新安装
…

解决:ModuleNotFoundError: No module named ‘tiktoken’
解决:ModuleNotFoundError: No module named ‘tiktoken’ 文章目录 解决:ModuleNotFoundError: No module named tiktoken背景报错问题报错翻译报错位置代码报错原因解决方法方法一,直接安装方法二,手动下载安装方法三࿰…

使用Python进行自然语言处理(NLP):NLTK与Spacy的比较【第133篇—NLTK与Spacy】
使用Python进行自然语言处理(NLP):NLTK与Spacy的比较
自然语言处理(NLP)是人工智能领域的一个重要分支,它涉及到计算机如何理解、解释和生成人类语言。在Python中,有许多库可以用于NLP任务&…
stanfordcorenlp创建实例对象时,一直运行,不报错也不出结果
前几天因为工作需要下载了Stanford Corenlp工具,然后创建相应的实例对象,对文本进行分词、注释等操作。单句测试的时候可以正常运行,很快就出结果,但是写到函数里,就是一直运行,不报错也不出结果࿰…
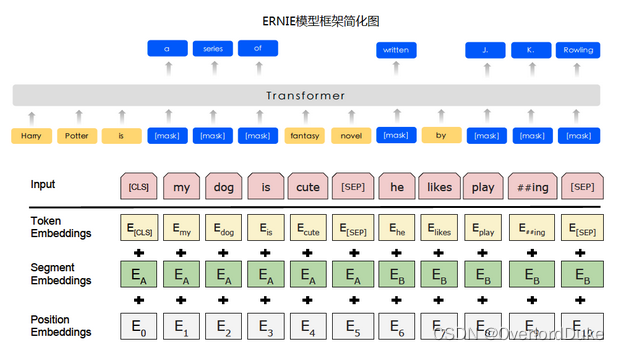
ERNIE实现酒店情感分析(文本分类)
ERNIE实现酒店情感分析(文本分类)
引言
在自然语言处理(NLP)领域,文本分类是一项重要的任务,它能够帮助我们理解和分析大量的文本数据。随着深度学习技术的发展,预训练模型成为了处理文本分类…
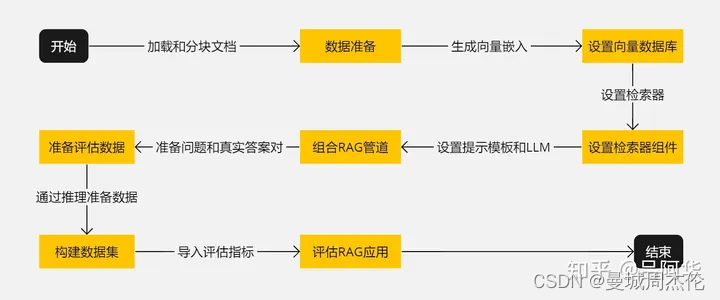
自然语言处理: 第十七章RAG的评估技术RAGAS
论文地址:[2309.15217] RAGAS: Automated Evaluation of Retrieval Augmented Generation (arxiv.org)
项目地址: explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines (github.com)
上一篇文章主要介绍了R…
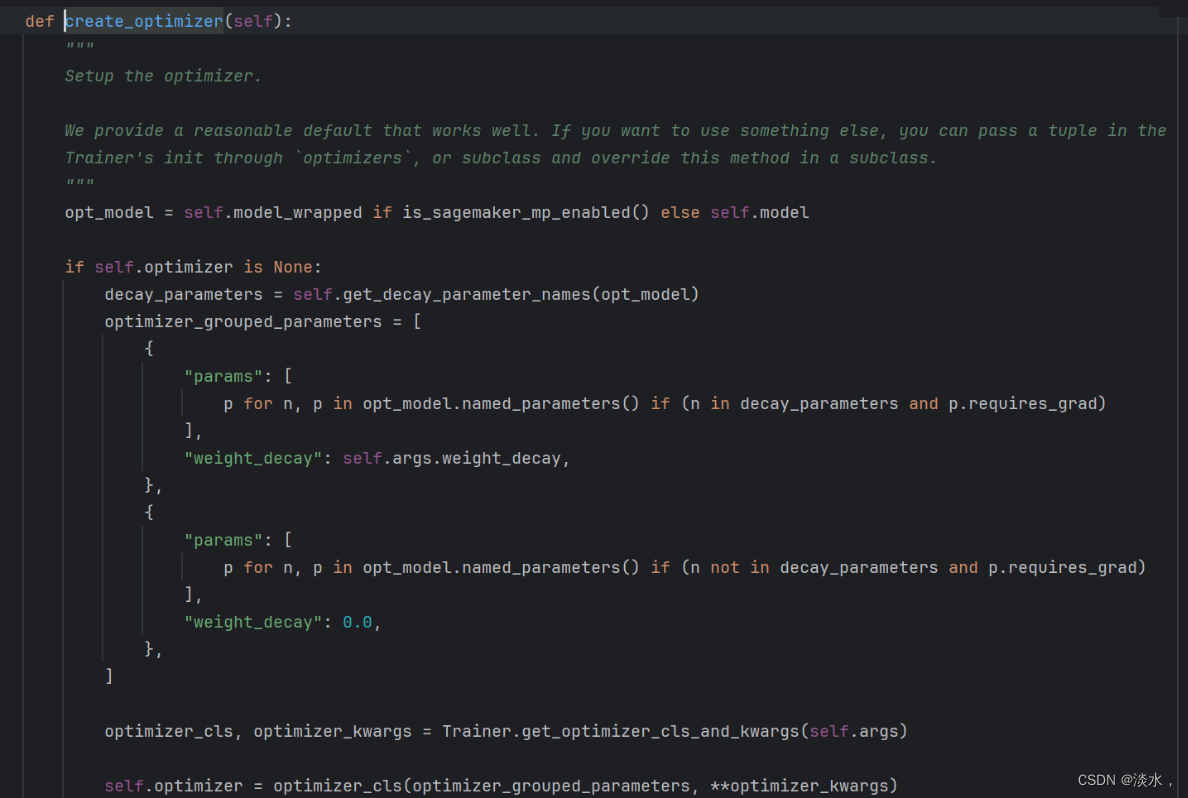
以微调deepseek为例,基于transformers改写实现lora+
LoRA: Efficient Low Rank Adaptation of Large Models
24年2月12的论文,主要思想就是对LoRA进行了一些改进,提升了模型效果。
摘要
证明了对Lora的A和B使用相同的学习率无法有效的特征学习。还证明了通过以一个良好选择的固定比率设置不同的学习速率…
![【自然语言处理】NLP入门(八):1、正则表达式与Python中的实现(8):正则表达式元字符:.、[]、^、$、*、+、?、{m,n}](https://img-blog.csdnimg.cn/direct/6d1dea02a36e4189942c427a5ed8dacd.png)
【自然语言处理】NLP入门(八):1、正则表达式与Python中的实现(8):正则表达式元字符:.、[]、^、$、*、+、?、{m,n}
文章目录 一、前言二、正则表达式与Python中的实现1、字符串构造2、字符串截取3、字符串格式化输出4、字符转义符5、字符串常用函数6、字符串常用方法7、正则表达式1. .:表示除换行符以外的任意字符2. []:指定字符集3. ^ :匹配行首࿰…
Prompt进阶系列5:LangGPT(提示链Prompt Chain)--提升模型鲁棒性
Prompt进阶系列5:LangGPT(提示链Prompt Chain)–提升模型鲁棒性
随着对大模型的应用实践的深入,许多大模型的使用者, Prompt 创作者对大模型的应用越来越得心应手。和 Prompt 有关的各种学习资料,各种优质内容也不断涌现。关于 Prompt 的实践…
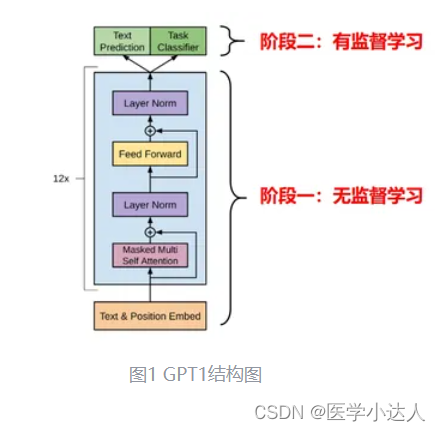
Python WikiGPT代码,GPT代码实战,逐行讲解GPT代码,教你完整写完GPT代码,GPT代码模板,一文教你学会写GPT代码
1.GPT基本介绍 在GPT1诞生之前,NLP领域已存在多种任务,比如文本分类、语义相似度,以及问答等,这些任务的共同点在于它们都是有监督学习,且各自维护不同的量级较小的训练语料。OpenAI为了进一步提升这些任务的预测效果&…
【NLP11-迁移学习】
1、了解迁移学习中的有关概念
1.1、预训练模型(pretrained model)
一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型。在NLP领域,预训练模型往往是语…
ERNIE SDK 本地使用与markdown自动生成
ERNIE SDK 仓库包含两个项目:ERNIE Bot Agent 和 ERNIE Bot。ERNIE Bot Agent 是百度飞桨推出的基于文心大模型编排能力的大模型智能体开发框架,结合了飞桨星河社区的丰富预置平台功能。ERNIE Bot 则为开发者提供便捷接口,轻松调用文心大模型…
【2024第十二届“泰迪杯”数据挖掘挑战赛】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程…
2024淘天阿里妈妈算法工程师一面&二面 面试题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
今天我们…

WebCPM:首个开源的交互式网页搜索中文问答模型
论文题目:WEBCPM: Interactive Web Search for Chinese Long-form Question Answering 论文日期:2023/05/23(ACL 2023) 论文地址:https://arxiv.org/abs/2305.06849 GitHub地址:https://arxiv.org/abs/2305.06849 文章…
语言模型transformers调用部分 (To be continue...
什么?!!!原来自回归模型的model.generate不能用于训练!!??
只能用法forward一次生成,但一次性只能得到一个tensor 就是在这里取最大值导致模型梯度断了,所以…
『大模型笔记』RAG应用的12种调优策略指南
RAG应用的12种调优策略指南 文章目录 一. 概要二. 数据索引2.1. 数据清洗2.2. 分块2.3. 嵌入模型2.4. 元数据(或未向量化的数据)2.5. 多索引2.6. 索引算法三. 推理阶段(检索和生成)3.1. 检索参数3.2. 高级检索策略3.3. 重新排序模型3.5. 大语言模型(LLM)
自然语言处理: 第十八章微调技术之QLoRA
文章地址: QLoRA: Efficient Finetuning of Quantized LLMs (arxiv.org)
项目地址: artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs (github.com)
前言
QLoRA是来自华盛顿大学的Tim Dettmers大神提出的模型量化算法,应用于LLM训练,降…
GPT-1原理-Improving Language Understanding by Generative Pre-Training
文章目录 前言提出动机模型猜想模型提出模型结构模型参数 模型预训练训练的目标训练方式训练参数预训练数据集预训练疑问点 模型微调模型输入范式模型训练微调建议微调疑问点 实验结果分析 前言
首先想感慨一波
这是当下最流行的大模型的的开篇之作,由OpenAI提出。…

神经网络学习笔记10——RNN、ELMo、Transformer、GPT、BERT
系列文章目录
参考博客1
参考博客2 文章目录 系列文章目录前言一、RNN1、简介2、模型结构3、RNN公式分析4、RNN的优缺点及优化1)LSTM是RNN的优化结构2)GRU是LSTM的简化结构 二、ELMo1、简介2、模型结构1)输入2)左右双向上下文信…

NLP:spacy库安装与zh_core_web_sm配置
到公司来第一个项目竟然是偏文本信息抽取与结构化的,(也太高看我了┭┮﹏┭┮)
反正给机会了就上吧,我就一臭实习的,怕个啥。配置了两天的环境,也踩了不少坑,我把我的经历给大家分享一下&#…
deepseek-coder模型量化
1 简介
DeepSeek-Coder在多种编程语言和各种基准测试中取得了开源代码模型中最先进的性能。 为尝试在开发板进行部署,首先利用llama.cpp对其进行量化。
2 llama.cpp安装
git clone之后进入文件夹make即可,再将依赖补全pip install -r requirements.tx…